
MLflow 2.0 and Beyond: A Deep Dive into the Modern MLOps Lifecycle
The machine learning landscape is in a constant state of flux, with advancements in model architectures and the explosion of Large Language Models (LLMs) reshaping how we build intelligent applications. This rapid evolution introduces significant complexity into the MLOps lifecycle. Managing experiments, ensuring reproducibility, packaging models, and deploying them reliably has become a critical challenge for teams of all sizes. Amidst this complexity, MLflow has solidified its position as a cornerstone open-source platform for managing the end-to-end machine learning workflow.
Recent major releases have transformed MLflow from a collection of powerful but loosely connected components into a more integrated, opinionated, and streamlined platform. This evolution is designed to accelerate development, enforce best practices, and simplify the path from idea to production. This article provides a comprehensive technical exploration of these modern MLflow capabilities. We will delve into the architectural shifts, explore new features with practical code examples, and discuss how MLflow integrates with the broader AI ecosystem, including updates from the worlds of PyTorch News, TensorFlow News, and the rapidly advancing LangChain News.
A Unified MLOps Experience: Core Enhancements in Recent MLflow Releases
Historically, MLflow offered four primary components: Tracking, Projects, Models, and the Model Registry. While incredibly powerful, they required developers to manually stitch them together to form a cohesive workflow. The latest MLflow News signals a strategic shift towards a more integrated experience through the introduction of MLflow Pipelines (formerly known as Recipes), which provide a structured, repeatable, and customizable framework for the entire MLOps process.
Beyond Experiment Tracking: Introducing MLflow Pipelines
MLflow Pipelines are pre-defined, high-level templates that encapsulate the standard steps of an ML project, such as data ingestion, splitting, transformation, training, evaluation, and model registration. By adopting a declarative approach—defining the *what* in a YAML file rather than the *how* in code—Pipelines drastically reduce boilerplate and enforce a standardized structure across projects and teams.
The key benefits of this approach include:
- Standardization: Every project follows the same logical structure, making it easier for team members to collaborate and understand different projects.
- Reproducibility: The entire workflow, from data versioning to model parameters, is captured in configuration, ensuring that results can be reliably reproduced.
- Rapid Development: Developers can focus on model logic and data quality instead of writing repetitive MLOps code.
- Best Practices by Default: The pipeline structure encourages best practices like caching intermediate results (steps are not re-run if inputs haven’t changed) and clear environment separation.
Let’s look at a simple example of a regression pipeline configuration. This `pipeline.yaml` file defines the entire workflow for a basic regression task.
# pipeline.yaml
template: regression/v1
target_col: "quality"
primary_metric: "root_mean_squared_error"
data:
# Location of the input dataset.
location: "https://raw.githubusercontent.com/mlflow/mlflow-example/main/wine-quality.csv"
steps:
train:
# Use the scikit-learn ElasticNet model
using: "sklearn"
estimator_params:
alpha: 0.01
l1_ratio: 0.75
register:
# Allow model registration to a new or existing model name
allow_non_validated_model: trueTo execute this pipeline, you simply run a command from your terminal. MLflow handles the orchestration of each step, logging all results automatically.
# Run the entire pipeline
mlflow pipelines run
# Inspect the results of the training step
mlflow pipelines get-artifact --step train --artifact modelThis declarative framework simplifies model development, whether you are working with traditional tabular data from sources like Snowflake Cortex News or preparing complex models for deployment with standardized formats discussed in ONNX News.

Deep Dive: Building and Customizing MLflow Pipelines
While the default templates are powerful, the true strength of MLflow Pipelines lies in their customizability. You can override specific steps, integrate custom code, and manage complex configurations for different environments, making the framework adaptable to nearly any ML problem.
The Anatomy of a Pipeline: Steps and Profiles
An MLflow Pipeline is composed of several distinct steps, each with a specific purpose:
- ingest: Loads the raw data.
- split: Divides the data into training, validation, and test sets.
- transform: Applies feature engineering and preprocessing steps.
- train: Trains the model using the processed data.
- evaluate: Assesses the model’s performance against the test set and compares it to a baseline.
- register: Registers the best-performing model to the MLflow Model Registry.
To manage environment-specific configurations (e.g., local development vs. production), Pipelines use profiles. A profile is a YAML file (e.g., `profiles/local.yaml`) that can override any setting in the main `pipeline.yaml`. This allows you to specify different data sources, compute resources, or tracking server URIs without altering the core pipeline definition. This is essential when moving from a local setup, perhaps using tools from Google Colab News, to a production environment on AWS SageMaker News or Azure Machine Learning News.
Integrating with the Modern AI Stack
You can easily customize a pipeline to use different libraries or custom logic. For example, to switch from a scikit-learn model to a LightGBM model, you would simply modify the `train` step in `pipeline.yaml`. For more complex customizations, you can provide your own Python code.
Here’s how you might write a custom training step to incorporate a model from the Hugging Face Transformers News ecosystem. You would create a `custom_steps.py` file and reference it in your pipeline configuration.
# custom_steps.py
import mlflow
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
)
from datasets import load_dataset
def custom_train_step(data_path, model_name="distilbert-base-uncased"):
"""
A custom training step for a Hugging Face transformer model.
"""
with mlflow.start_run() as run:
# Load data (assuming pre-processed)
dataset = load_dataset("csv", data_files=data_path)
# Tokenizer and Model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
num_train_epochs=1,
per_device_train_batch_size=8,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
)
# Train the model
trainer.train()
# Log the model with MLflow
mlflow.transformers.log_model(
transformers_model={"model": model, "tokenizer": tokenizer},
artifact_path="transformer_model",
)
return run.info.run_idThis modularity allows MLflow to act as an orchestration layer on top of a diverse set of tools, from distributed computing frameworks like Ray News and Dask News to specialized hardware acceleration libraries covered in NVIDIA AI News.
Advanced Capabilities: Scaling and Adapting for the LLM Era
The machine learning world is increasingly dominated by LLMs. Recognizing this trend, MLflow has introduced powerful new features tailored specifically for developing, evaluating, and managing LLM-based applications. This is a critical area of development, aligning with the latest OpenAI News and Google DeepMind News.
Prompt Engineering and Evaluation with MLflow
One of the most significant recent additions is the enhancement of the `mlflow.evaluate()` API. It now includes capabilities designed for generative models, moving beyond traditional metrics like accuracy and F1-score. You can now evaluate models based on criteria like fluency, toxicity, and adherence to custom guidelines using LLM-as-a-judge evaluation.
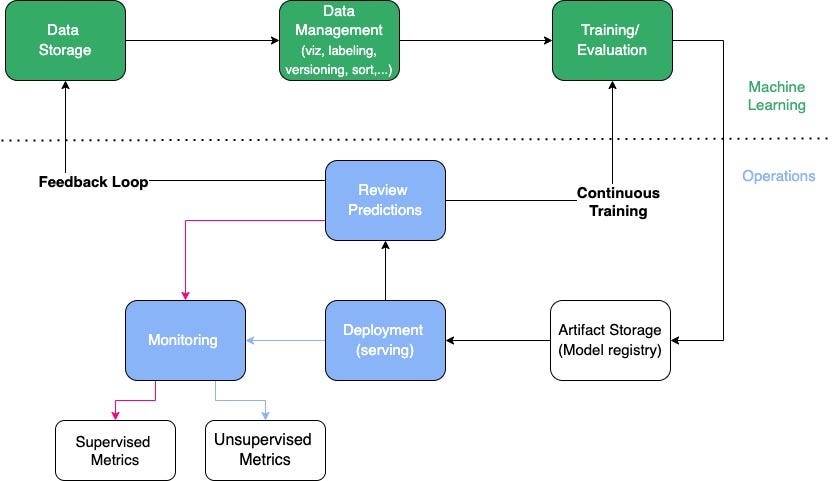
This feature is invaluable for prompt engineering, allowing you to systematically compare the outputs of different prompts or models (e.g., comparing models from Anthropic News vs. Cohere News vs. Mistral AI News). The results are displayed in a rich UI, making it easy to analyze and compare text outputs side-by-side.
import mlflow
import pandas as pd
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
# Define a simple model function that queries an LLM
def create_summary_model(model_name="gpt-3.5-turbo"):
def summary_model(inputs):
summaries = []
for text in inputs:
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "You are a helpful assistant that summarizes text."},
{"role": "user", "content": f"Please summarize the following text in one sentence: {text}"},
],
)
summaries.append(response.choices[0].message.content)
return summaries
return summary_model
# Input data and ground truth
eval_data = pd.DataFrame({
"text": [
"The quick brown fox jumps over the lazy dog. This sentence contains all letters of the English alphabet.",
"MLflow is an open-source platform for managing the end-to-end machine learning lifecycle."
],
"ground_truth": [
"A pangram about a fox and a dog demonstrates all letters of the alphabet.",
"MLflow is a tool for the complete MLOps process."
]
})
# Create two different "models" (representing different prompts or base models)
model_v1 = create_summary_model("gpt-3.5-turbo")
model_v2 = create_summary_model("gpt-4") # A different model
# Use mlflow.evaluate to compare the models
with mlflow.start_run() as run:
eval_results = mlflow.evaluate(
model=model_v1,
data=eval_data["text"],
targets="ground_truth",
model_type="question-answering", # Use a relevant model type for text generation
evaluators=["default"]
)
print(eval_results.metrics)
# You can now log another run to compare model_v2 and see the difference in the UIIntegrating with Vector Databases and RAG Pipelines
Retrieval-Augmented Generation (RAG) has become a dominant pattern for building context-aware LLM applications. MLflow is adapting to help manage the complexity of these systems. You can use MLflow to track experiments for RAG pipelines built with popular frameworks like those from LlamaIndex News. This includes logging not just the LLM but also the retriever, the prompt templates, and even artifacts like vector store indexes from providers like Pinecone News, Weaviate News, or Chroma News. By logging an entire `LangChain` or `LlamaIndex` chain as a custom MLflow model, you can version, deploy, and reproduce your entire RAG pipeline with a single, unified interface.
Best Practices for Enterprise-Grade MLOps with MLflow
As you scale your MLOps practice, adhering to best practices becomes crucial for maintaining velocity and ensuring governance. MLflow’s recent updates make it easier to implement these practices across your organization.
Model Governance and the MLflow Model Registry
The Model Registry remains a central pillar of MLflow for model governance. It acts as a central repository for all your production-candidate models, allowing you to manage versions, assign stages (e.g., `Staging`, `Production`), and add descriptive metadata. MLflow Pipelines integrate directly with the registry, automatically registering the best-performing model from an `evaluate` step. This closes the loop from development to deployment, providing a clear audit trail and simplifying rollbacks.
Performance Optimization and Deployment
Before deploying a model, especially to edge devices or high-throughput environments, optimization is key. You can use tools like TensorRT News or OpenVINO News to compile and accelerate your models. The resulting optimized model can be logged as a new version in the MLflow Model Registry, linked to its unoptimized parent. This ensures you maintain a clear lineage while managing multiple deployment-ready formats. From the registry, models can be deployed to a variety of targets, including cloud platforms like Vertex AI News or inference servers like the Triton Inference Server.
Avoiding Common Pitfalls
To maximize the benefits of MLflow, be mindful of these common pitfalls:
- Not Using a Remote Tracking Server: For team collaboration, a local `mlruns` directory is insufficient. Set up a centralized, remote tracking server with a database backend to share experiments and models.
- Ignoring Profiles for Environment Management: Hardcoding paths or credentials in your main pipeline configuration leads to brittle workflows. Use profiles to separate configuration from logic.
- Forgetting Code Versioning: MLflow automatically logs the Git commit hash if you are in a Git repository. Always commit your code before running an experiment to ensure full reproducibility.
- Overlooking Custom Model Flavors: For complex models or pipelines (like a RAG chain), the built-in flavors may not be enough. Creating a custom Python model (`pyfunc`) flavor allows you to package any object and its inference logic together.
While MLflow provides a comprehensive solution, it’s also worth noting the broader MLOps ecosystem. Tools like Weights & Biases News and Comet ML News offer alternative approaches to experiment tracking, often with a focus on highly interactive UIs and team collaboration features. Understanding the landscape helps you make informed decisions about your MLOps stack.
Conclusion and Next Steps
MLflow has evolved significantly, maturing from a set of discrete tools into a cohesive, powerful platform for modern MLOps. The introduction of MLflow Pipelines provides a standardized, reproducible, and highly automated framework that accelerates the journey from development to production. Furthermore, its latest enhancements for LLM evaluation and integration with the generative AI stack demonstrate a commitment to staying at the forefront of the industry.
By embracing these new features, you can bring order to the chaos of the modern ML lifecycle, enabling your team to build more robust, reliable, and scalable AI applications. As a next step, explore the official MLflow Pipelines documentation, try out the templates with your own datasets, and consider how this structured approach can be integrated into your existing workflows, whether on-premise or on a major cloud platform like Azure Machine Learning. The future of MLOps is about structured, repeatable, and automated processes, and MLflow is clearly a leading force in shaping that future.


