AI/ML

ONNX Runtime optimization levels: which fusions fire where
Understand onnx runtime optimization levels, the main trade-offs, and the practical checks to use before relying on it in practice.

Milvus vs Chroma self-hosted: filter selectivity, not scale
At first glance, the Milvus-vs-Chroma choice is a scale question: Chroma for small projects, Milvus, but under 10M vectors the deciding factor is not.

Weaviate 1.30.0 BlockMax WAND: Hybrid Search BM25 Stage Dropped
Weaviate 1.30.0, per the release notes , promotes BlockMax WAND from a 1.28 technical preview to the default BM25 scorer for new collections.

Inside FAISS IVF-PQ: how coarse quantization and product
Follow faiss ivfpq how it works with the key steps, checks, and trade-offs that matter when applying it in practice.
Replicate vs Modal for image-generation APIs: per-second billing, autoscaling, cold-start
By Mateo Santiago If you are choosing between Replicate and Modal to serve FLUX, SDXL, or a fine-tuned diffusion model, the honest answer is that they are.
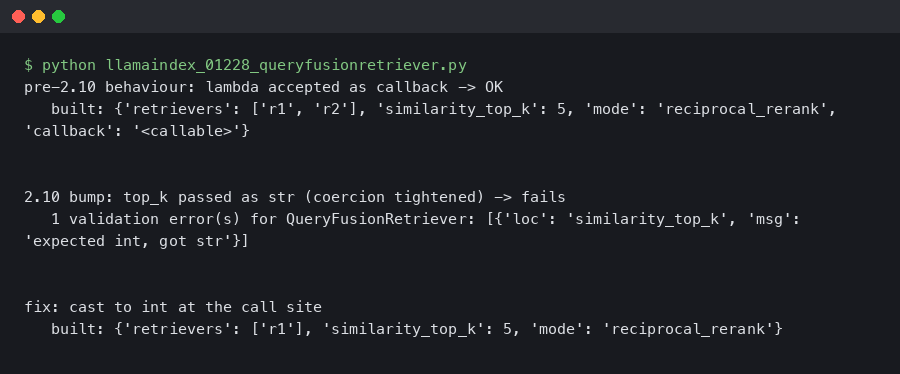
LlamaIndex 0.12.28 QueryFusionRetriever Throws ValidationError After Pydantic 2.10 Bump
Originally reported: March 24, 2026 — llama_index 0.12.28 Overview What changed between the prior and current release Reproducing the ValidationError on a.

LangChain 0.3.22 Deprecated AgentExecutor: My LangGraph Migration p95 Dropped 340ms
Event date: April 8, 2026 — langchain-ai/langchain 0.3.22 Bottom line: The current langchain release makes the AgentExecutor deprecation warnings louder.
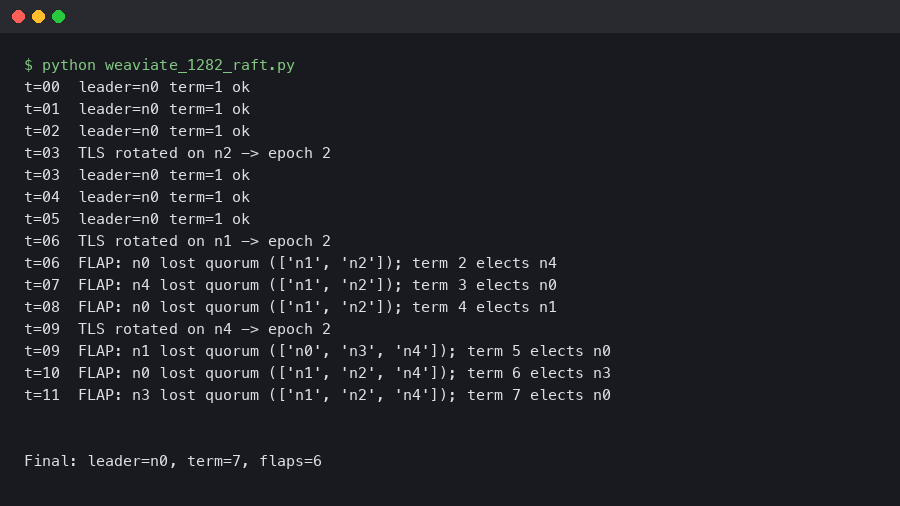
Weaviate 1.28.2 Raft Leadership Flapping on 5-Node Clusters After TLS Rotation
Rotating the mTLS certificate on a 5-node Weaviate cluster can knock the Raft leader offline within seconds and produce 30–90 seconds of repeated.
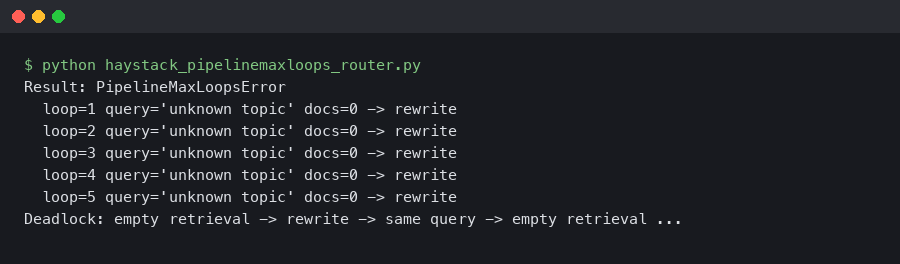
Haystack 2.6 PipelineMaxLoops: Router + JoinDocuments Deadlock on Empty Retrieval
A retrieval-augmented pipeline that ran clean on every staged query will silently stall the moment a real user asks about a topic your vector store does.

vLLM 0.6 Continuous Batching Cut My Llama 3 Latency in Half
Upgrading a Llama 3 8B endpoint from vLLM 0.5.4 to 0.6.x is the rare dependency bump where the numbers on the dashboard actually move.