Model Optimization

ONNX Runtime optimization levels: which fusions fire where
Understand onnx runtime optimization levels, the main trade-offs, and the practical checks to use before relying on it in practice.
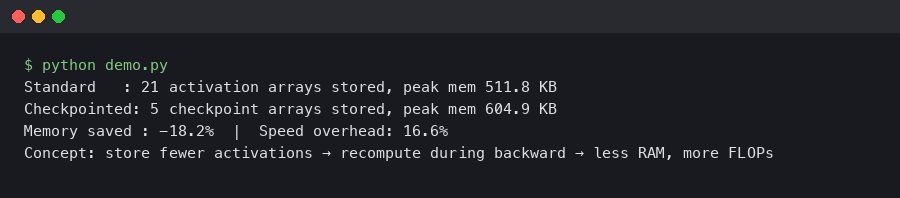
JAX Gradient Checkpointing on TPU v5e: 40% Memory Cut at 12% Speed Cost
In this article How does JAX gradient checkpointing reduce memory on TPU v5e? What is the checkpoint policy that drives the 40% memory saving?

DeepSpeed Ulysses: A Breakthrough in Training Extreme Long-Sequence AI Models
Introduction: Breaking the Sequence Length Barrier in Transformer Models The world of artificial intelligence is in a constant race to build larger, more.