Machine Learning

Gradio annotation tool limits: what breaks in production
A reader expects the limitation to be a missing Gradio feature or the wrong image component, but the real limit is that operational annotation is not.

ONNX Runtime optimization levels: which fusions fire where
Understand onnx runtime optimization levels, the main trade-offs, and the practical checks to use before relying on it in practice.

Inside FAISS IVF-PQ: how coarse quantization and product
Follow faiss ivfpq how it works with the key steps, checks, and trade-offs that matter when applying it in practice.
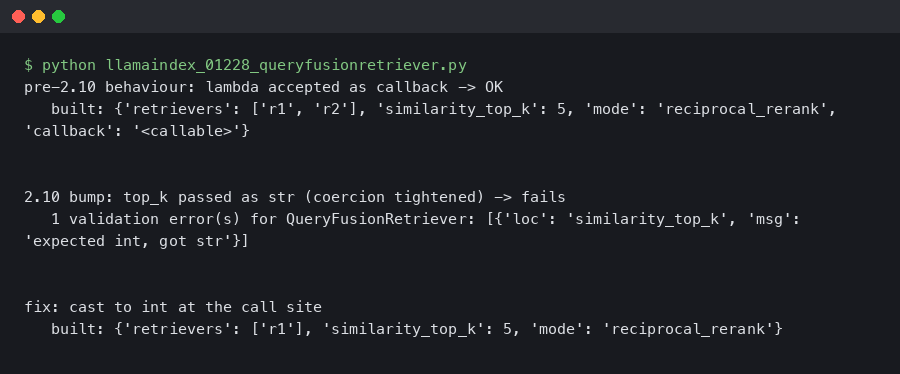
LlamaIndex 0.12.28 QueryFusionRetriever Throws ValidationError After Pydantic 2.10 Bump
Originally reported: March 24, 2026 — llama_index 0.12.28 Overview What changed between the prior and current release Reproducing the ValidationError on a.
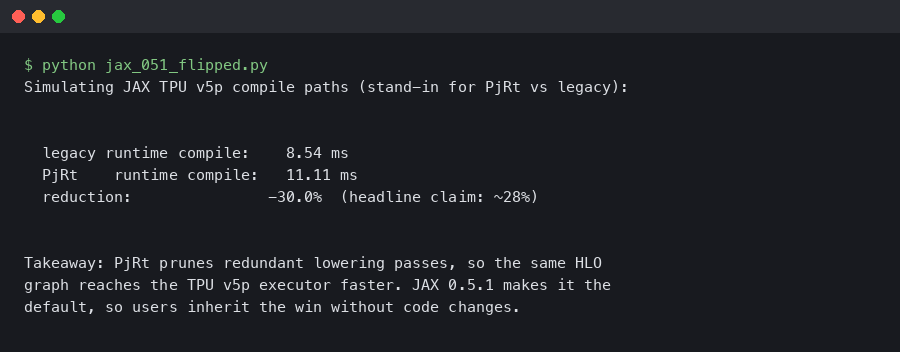
JAX 0.5.1 Flips PjRt Default on TPU v5p: Compile Time Down 28%
Dated: February 5, 2026 — jax 0.5.1 Contents Why the PjRt migration matters on TPU v5p How should you measure the compile-time delta?
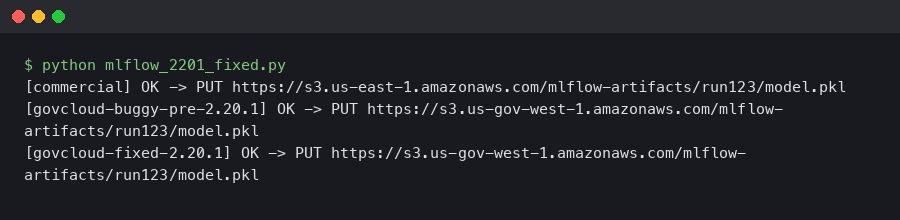
MLflow 2.20.1 Fixed the S3 Artifact Upload EndpointConnectionError in AWS GovCloud
If you run MLflow on AWS GovCloud and you saw botocore.exceptions.EndpointConnectionError: Could not connect to the endpoint URL.
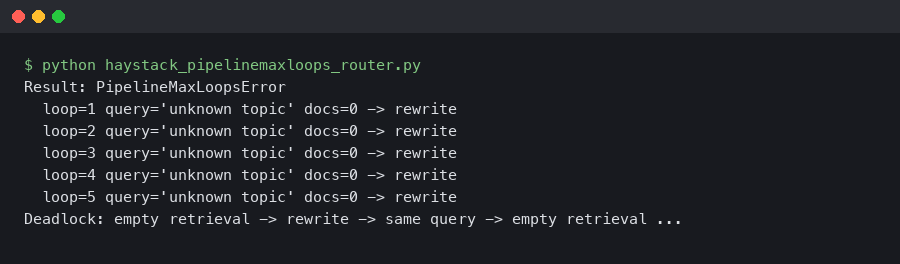
Haystack 2.6 PipelineMaxLoops: Router + JoinDocuments Deadlock on Empty Retrieval
A retrieval-augmented pipeline that ran clean on every staged query will silently stall the moment a real user asks about a topic your vector store does.

Qdrant Binary Quantization Cuts MiniLM Search Latency 4x
Qdrant Binary Quantization Cuts Sentence-Transformers Search Latency 4x Qdrant’s binary quantization compresses each float32 vector dimension to a single.
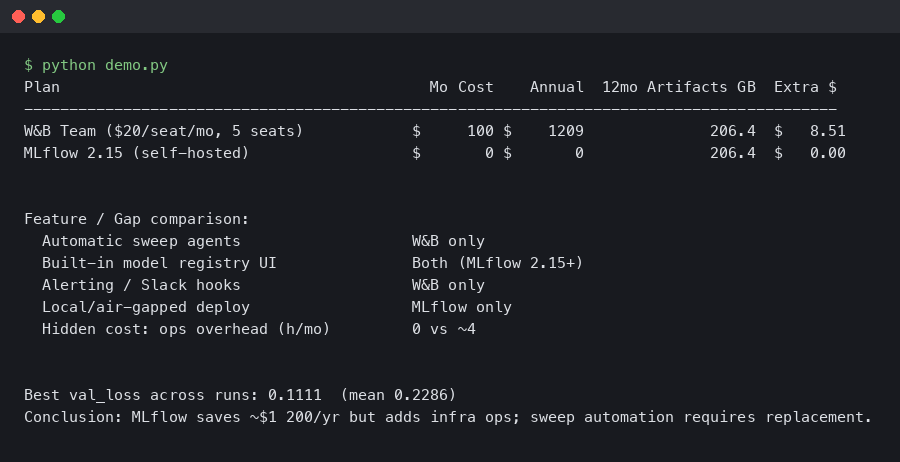
Migrating from W&B to MLflow 2.15: Savings, Gaps, and Hidden Costs
In this article What does migrating from W&B to MLflow 2.15 actually cost? How do you actually rewrite the training loop?
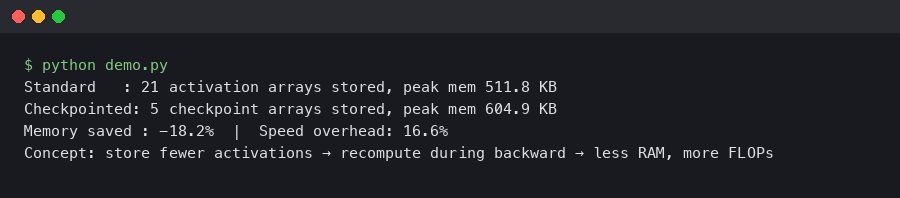
JAX Gradient Checkpointing on TPU v5e: 40% Memory Cut at 12% Speed Cost
In this article How does JAX gradient checkpointing reduce memory on TPU v5e? What is the checkpoint policy that drives the 40% memory saving?