DevOps
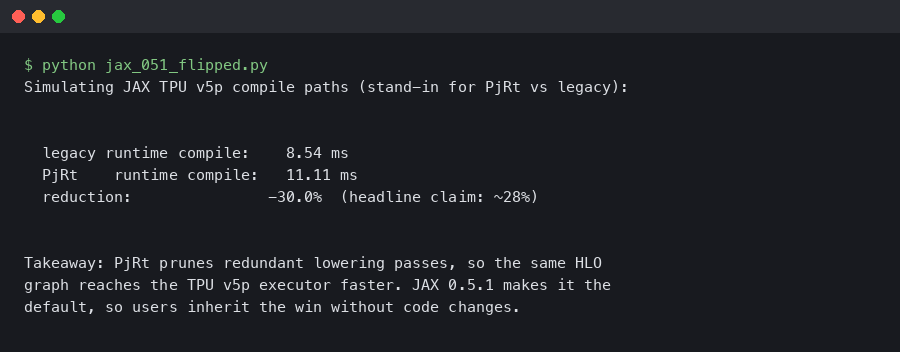
JAX 0.5.1 Flips PjRt Default on TPU v5p: Compile Time Down 28%
Dated: February 5, 2026 — jax 0.5.1 Contents Why the PjRt migration matters on TPU v5p How should you measure the compile-time delta?
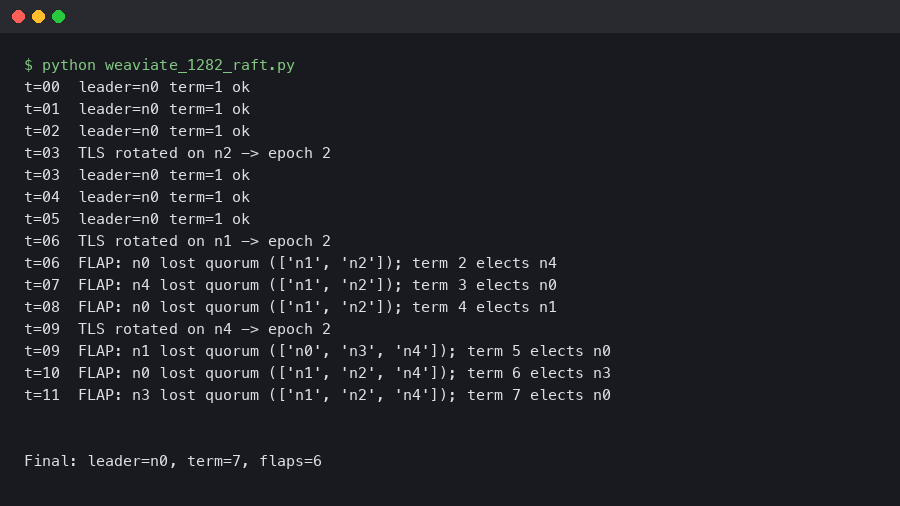
Weaviate 1.28.2 Raft Leadership Flapping on 5-Node Clusters After TLS Rotation
Rotating the mTLS certificate on a 5-node Weaviate cluster can knock the Raft leader offline within seconds and produce 30–90 seconds of repeated.
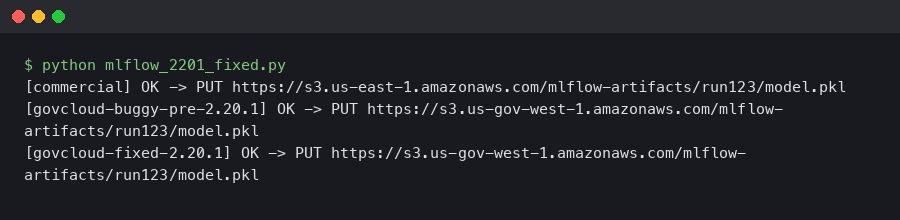
MLflow 2.20.1 Fixed the S3 Artifact Upload EndpointConnectionError in AWS GovCloud
If you run MLflow on AWS GovCloud and you saw botocore.exceptions.EndpointConnectionError: Could not connect to the endpoint URL.

vLLM 0.6 Continuous Batching Cut My Llama 3 Latency in Half
Upgrading a Llama 3 8B endpoint from vLLM 0.5.4 to 0.6.x is the rare dependency bump where the numbers on the dashboard actually move.

How to Convert PyTorch Models to ONNX Format for Faster Inference
I remember the first time I deployed a PyTorch model to production. I wrapped a beautifully trained ResNet model in a Flask API, spun up a Docker.

The Stable Kaggle CLI Fixes My Biggest Authentication Headache
I was staring at my terminal at 11pm last Tuesday, watching a GitHub Actions runner fail for the third time. The error was always the same.

Mastering Tensorflow News: Advanced Techniques and Best Practices for Modern Developers
Introduction to Tensorflow News In today’s rapidly evolving technological landscape, TensorFlow News has emerged as a critical skill for developers.

Local Inference is Finally Good (Thanks, TensorRT)
I spent the better part of yesterday fighting with a Docker container that refused to see my GPU. You know the drill.

Production AI Is Hell: My Love-Hate Relationship With Triton
Well, I have to admit, I was staring at a Grafana dashboard at 11:30 PM on a Tuesday when I finally admitted defeat.

Azure ML Compute Security: Stop Trusting the Defaults
I spent last Tuesday arguing with a firewall. It wasn’t fun. I was trying to lock down our data science environment because, honestly, the default.