Data Engineering
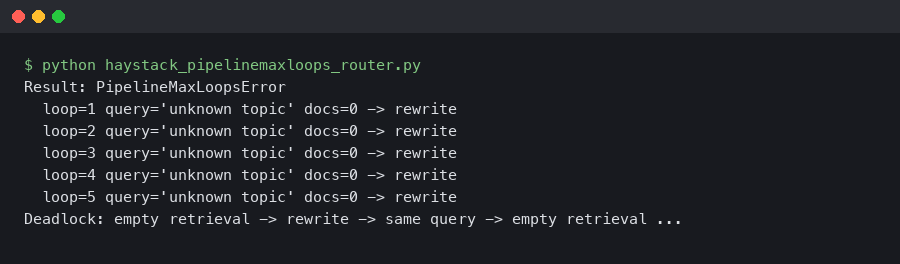
Haystack 2.6 PipelineMaxLoops: Router + JoinDocuments Deadlock on Empty Retrieval
A retrieval-augmented pipeline that ran clean on every staged query will silently stall the moment a real user asks about a topic your vector store does.

OpenAI vs Anthropic: Choosing the Best LLM for RAG Pipelines
I’ve spent the last two years tearing apart, rebuilding, and agonizing over Retrieval-Augmented Generation (RAG) architectures.

The Stable Kaggle CLI Fixes My Biggest Authentication Headache
I was staring at my terminal at 11pm last Tuesday, watching a GitHub Actions runner fail for the third time. The error was always the same.

Dask’s Active Memory Manager Finally Stopped Breaking My Pipelines
I used to dread the Slack notification. You know the one. The little red dot popping up at 7:30 AM telling me my overnight batch job failed.

Building a Streamlit Market Copilot That Actually Works
Financial news aggregators have a massive noise-to-signal problem, especially when tech stocks suddenly drop 8% while the broader market stays flat.

Mastering Tensorflow News: Advanced Techniques and Best Practices for Modern Developers
Introduction to Tensorflow News In today’s rapidly evolving technological landscape, TensorFlow News has emerged as a critical skill for developers.

Secure AI in Hex: Running Claude Inside Snowflake Cortex
I’ve lost count of how many times I’ve had to kill a project—or at least neuter it significantly—because InfoSec took one look at the architecture diagram.

Ray joined PyTorch Foundation: Why my infra team finally relaxed
Actually, I should clarify — I was sitting in a budget meeting last November when our CTO asked the question that usually makes me sweat: “Are we sure.

Stop scraping your Notion manually: A real sync pipeline to Pinecone
Actually, I should clarify – I spent last Tuesday night staring at a 429 Too Many Requests error from the Notion API, wondering why I ever decided to.

Ray and Monarch: Did PyTorch Finally Fix Distributed Training?
Well, I have to admit, I used to be one of those developers who hated dealing with the distributed training headaches.