MLOps

Milvus vs Chroma self-hosted: filter selectivity, not scale
At first glance, the Milvus-vs-Chroma choice is a scale question: Chroma for small projects, Milvus, but under 10M vectors the deciding factor is not.
Replicate vs Modal for image-generation APIs: per-second billing, autoscaling, cold-start
By Mateo Santiago If you are choosing between Replicate and Modal to serve FLUX, SDXL, or a fine-tuned diffusion model, the honest answer is that they are.
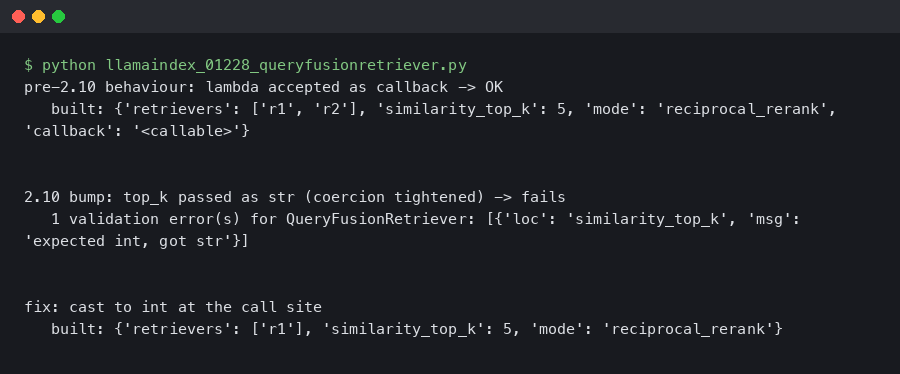
LlamaIndex 0.12.28 QueryFusionRetriever Throws ValidationError After Pydantic 2.10 Bump
Originally reported: March 24, 2026 — llama_index 0.12.28 Overview What changed between the prior and current release Reproducing the ValidationError on a.
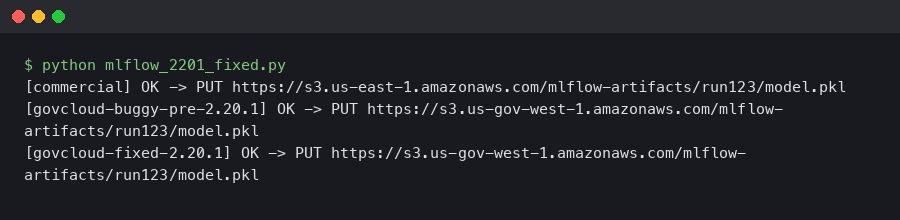
MLflow 2.20.1 Fixed the S3 Artifact Upload EndpointConnectionError in AWS GovCloud
If you run MLflow on AWS GovCloud and you saw botocore.exceptions.EndpointConnectionError: Could not connect to the endpoint URL.
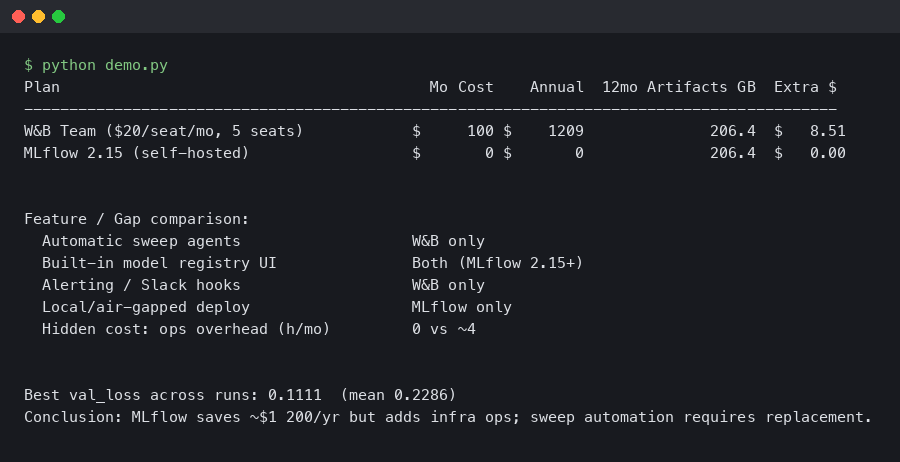
Migrating from W&B to MLflow 2.15: Savings, Gaps, and Hidden Costs
In this article What does migrating from W&B to MLflow 2.15 actually cost? How do you actually rewrite the training loop?
Mistral-7B-v0.3 QLoRA on Modal A100-40GB: nf4 + bf16_compute Beat My RunPod H100 Spot Cost Per Step
TL;DR: For a Mistral-7B-v0.3 QLoRA fine-tune at sequence length 2048 and micro-batch 4, a Modal A100-40GB container running bitsandbytes nf4 with bfloat16.

vLLM 0.6 Continuous Batching Cut My Llama 3 Latency in Half
Upgrading a Llama 3 8B endpoint from vLLM 0.5.4 to 0.6.x is the rare dependency bump where the numbers on the dashboard actually move.
Dropping my local tracking server for Comet’s new free tier
The 2 AM breaking point Well, there I was, staring at my terminal at 1:30 AM on a Thursday, watching my training loop crash for the fourth time.

Production AI Is Hell: My Love-Hate Relationship With Triton
Well, I have to admit, I was staring at a Grafana dashboard at 11:30 PM on a Tuesday when I finally admitted defeat.

Optuna’s New Rust Storage Backend Is Absurdly Fast
Actually, I should clarify – I spent three hours last Tuesday staring at a progress bar that simply refused to move. You know the feeling.