Performance

ONNX Runtime optimization levels: which fusions fire where
Understand onnx runtime optimization levels, the main trade-offs, and the practical checks to use before relying on it in practice.

Weaviate 1.30.0 BlockMax WAND: Hybrid Search BM25 Stage Dropped
Weaviate 1.30.0, per the release notes , promotes BlockMax WAND from a 1.28 technical preview to the default BM25 scorer for new collections.
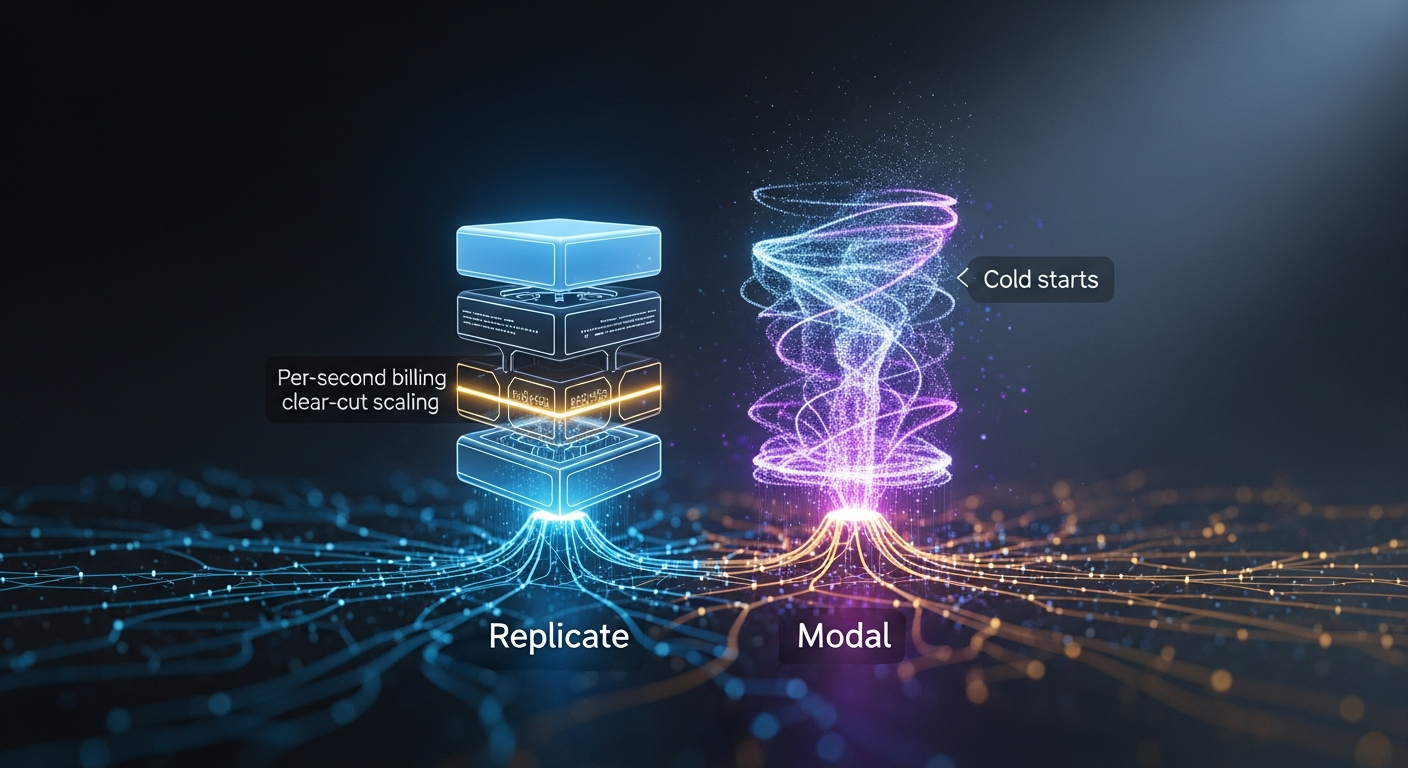
Replicate vs Modal for image-generation APIs: per-second billing, autoscaling, cold-start
By Mateo Santiago If you are choosing between Replicate and Modal to serve FLUX, SDXL, or a fine-tuned diffusion model, the honest answer is that they are.
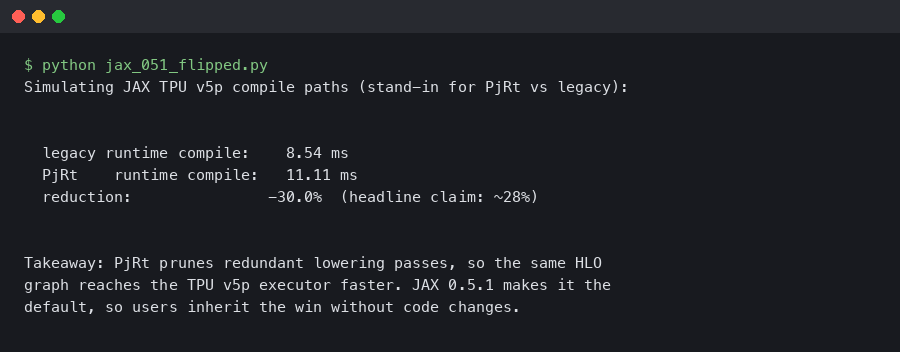
JAX 0.5.1 Flips PjRt Default on TPU v5p: Compile Time Down 28%
Dated: February 5, 2026 — jax 0.5.1 Contents Why the PjRt migration matters on TPU v5p How should you measure the compile-time delta?

LangChain 0.3.22 Deprecated AgentExecutor: My LangGraph Migration p95 Dropped 340ms
Event date: April 8, 2026 — langchain-ai/langchain 0.3.22 Bottom line: The current langchain release makes the AgentExecutor deprecation warnings louder.
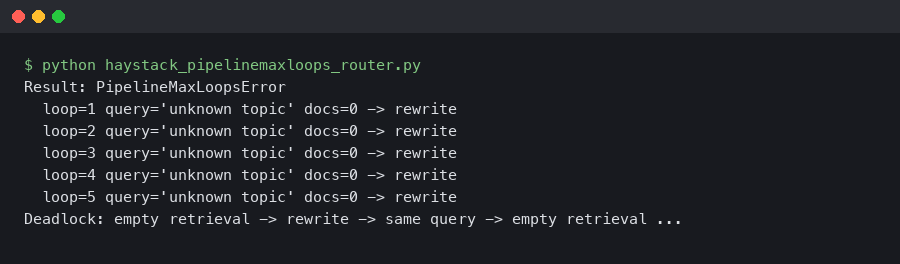
Haystack 2.6 PipelineMaxLoops: Router + JoinDocuments Deadlock on Empty Retrieval
A retrieval-augmented pipeline that ran clean on every staged query will silently stall the moment a real user asks about a topic your vector store does.

Qdrant Binary Quantization Cuts MiniLM Search Latency 4x
Qdrant Binary Quantization Cuts Sentence-Transformers Search Latency 4x Qdrant’s binary quantization compresses each float32 vector dimension to a single.
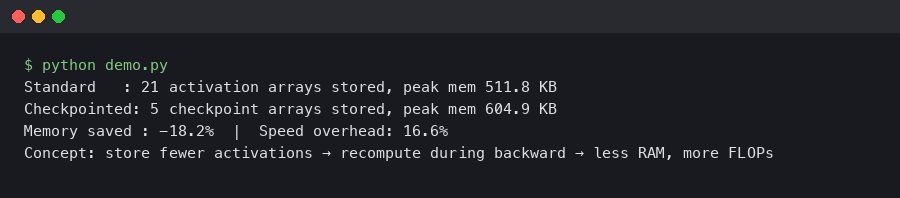
JAX Gradient Checkpointing on TPU v5e: 40% Memory Cut at 12% Speed Cost
In this article How does JAX gradient checkpointing reduce memory on TPU v5e? What is the checkpoint policy that drives the 40% memory saving?
Mistral-7B-v0.3 QLoRA on Modal A100-40GB: nf4 + bf16_compute Beat My RunPod H100 Spot Cost Per Step
TL;DR: For a Mistral-7B-v0.3 QLoRA fine-tune at sequence length 2048 and micro-batch 4, a Modal A100-40GB container running bitsandbytes nf4 with bfloat16.

vLLM 0.6 Continuous Batching Cut My Llama 3 Latency in Half
Upgrading a Llama 3 8B endpoint from vLLM 0.5.4 to 0.6.x is the rare dependency bump where the numbers on the dashboard actually move.