LlamaIndex News: Building Advanced AI with Event-Driven Workflows and SQL Integration
Introduction: The Next Evolution in AI Application Development
The landscape of Large Language Model (LLM) applications is evolving at a breakneck pace. We’ve moved beyond simple, single-prompt chatbots to sophisticated, multi-step agents that can reason, use tools, and interact with complex data sources. However, this increasing complexity has exposed the limitations of traditional, linear pipeline architectures. As developers strive to build more dynamic and intelligent systems, the rigidity of sequential chains becomes a bottleneck, hindering parallelism, conditional logic, and robust error handling. This is a central theme in recent LlamaIndex News and a challenge faced by the entire AI development community, from users of LangChain to developers on AWS SageMaker and Vertex AI.
In response to this challenge, LlamaIndex has introduced Workflows, a powerful new paradigm for orchestrating complex AI applications. Moving away from rigid chains, Workflows embrace a more flexible and scalable model based on Directed Acyclic Graphs (DAGs) and an event-driven architecture. This allows developers to define intricate relationships between different processing steps, enabling parallel execution, conditional branching, and a more modular design. This article provides a comprehensive technical deep dive into LlamaIndex Workflows, exploring their core concepts, practical implementation with crucial SQL database integrations, and advanced techniques for building the next generation of intelligent applications.
From Linear Chains to Dynamic DAGs: Understanding LlamaIndex Workflows
To fully appreciate the innovation of LlamaIndex Workflows, it’s essential to first understand the model they are designed to replace. The journey from linear chains to dynamic DAGs represents a significant leap in building sophisticated AI systems.
The Limitations of Sequential Processing
Most early RAG (Retrieval-Augmented Generation) applications followed a simple, linear sequence: receive a query, retrieve relevant documents from a vector database like Pinecone or Milvus, and then synthesize an answer using an LLM from providers like OpenAI or Anthropic. While effective for straightforward Q&A, this model struggles with complexity. What if you need to query multiple data sources in parallel? What if the choice of the next tool depends on the output of a previous step? Forcing these scenarios into a linear chain results in brittle, hard-to-maintain code that lacks efficiency and adaptability.
Introducing the Workflow: A DAG-Based Approach
LlamaIndex Workflows re-imagine this process as a Directed Acyclic Graph (DAG). In this model, each task is a “step” (a node in the graph), and the data passed between them is an “event” (an edge in the graph). This structure is inherently more flexible and powerful.
The key components are:
- Workflow: The main orchestrator that manages the execution of the graph. It tracks the state and directs the flow of events between steps.
- Step: A self-contained unit of work. A step can be anything from a simple data transformation function to a complex LLM call or a database query. Each step defines what events it consumes and what events it produces.
- Event: The data packet that flows through the workflow. An event carries the output from one step to the input of the next, triggering its execution.
This event-driven, graph-based approach unlocks capabilities that are difficult to implement in linear chains, such as running independent data retrieval tasks in parallel or creating conditional paths based on intermediate results. This development in LlamaIndex News aligns with broader industry trends seen in tools like Ray and Apache Spark MLlib, which have long used DAGs for distributed computing.
Core Concept: A Simple Workflow Example
Let’s look at a conceptual Python example to solidify these ideas. Here, we define a simple workflow with two sequential steps: one to generate a query and another to execute it.
from llama_index.core.workflow import (
Workflow,
Step,
Event,
Context,
step,
)
from typing import Dict, Any
# Define a custom event to carry our data
class QueryGeneratedEvent(Event):
query: str
class QueryResultEvent(Event):
result: Any
# Use the @step decorator to define a workflow step
@step
def generate_query_step(context: Context, **kwargs) -> QueryGeneratedEvent:
"""Generates a query based on initial input."""
topic = kwargs.get("topic", "AI advancements")
print(f"Step 1: Generating query for topic: {topic}")
return QueryGeneratedEvent(query=f"What are the latest news about {topic}?")
@step
def execute_query_step(context: Context, event: QueryGeneratedEvent) -> QueryResultEvent:
"""'Executes' the query (simulation)."""
print(f"Step 2: Executing query: '{event.query}'")
# In a real application, this would call a search engine or database
simulated_result = {
"source": "Simulated Search",
"content": "LlamaIndex introduces event-driven workflows."
}
return QueryResultEvent(result=simulated_result)
# Create the workflow and add the steps
workflow = Workflow()
workflow.add_step(generate_query_step)
workflow.add_step(execute_query_step, consumes=QueryGeneratedEvent)
# Run the workflow
result_event = workflow.run(topic="LlamaIndex Workflows")
# Access the final result
print(f"\nWorkflow finished. Final Result: {result_event.result}")This simple example demonstrates the fundamental flow: a step is executed, it produces an event, and the workflow routes that event to the next step that is configured to consume it.
Practical Implementation: Integrating Workflows with a SQL Database
Real-world AI applications rarely exist in isolation. They need to interact with existing infrastructure, most commonly relational databases. A key use case is logging workflow activity for observability and managing state. Let’s build a workflow that interacts with a SQL database to log its progress, demonstrating schema design, transactions, and queries.
Defining the Database Schema for Workflow State
Before our workflow can interact with a database, we need a table to store the data. A well-designed schema is crucial for efficient logging and debugging. We’ll create a table to log each step’s execution details. This is a common practice when building systems that require auditing and traceability, often monitored with tools like LangSmith or ClearML.
CREATE TABLE workflow_logs (
log_id SERIAL PRIMARY KEY,
workflow_run_id UUID NOT NULL,
step_name VARCHAR(255) NOT NULL,
status VARCHAR(50) NOT NULL, -- e.g., 'STARTED', 'COMPLETED', 'FAILED'
input_payload JSONB,
output_payload JSONB,
executed_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP
);
COMMENT ON TABLE workflow_logs IS 'Stores execution logs for each step in a LlamaIndex Workflow.';This SQL schema defines a `workflow_logs` table with columns to track a unique run ID, the name of the step, its status, and JSONB fields to flexibly store input and output data.
Building a Workflow Step for Database Transactions
Now, let’s create a workflow step that writes to this table. It’s critical that database writes are performed within a transaction to ensure data integrity. If any part of the operation fails, the entire transaction is rolled back, preventing partial or corrupt data from being saved. Here we use `sqlalchemy` for database interaction.
import uuid
import json
from sqlalchemy import create_engine, text
from llama_index.core.workflow import step, Context, Event
# Assume engine is configured elsewhere, e.g.,
# DATABASE_URL = "postgresql://user:password@host:port/database"
# engine = create_engine(DATABASE_URL)
class LogEntryEvent(Event):
log_id: int
@step
def log_to_database_step(context: Context, event_to_log: Event) -> LogEntryEvent:
"""A workflow step to log an event to the database within a transaction."""
workflow_run_id = context.run_id # LlamaIndex provides a run_id in the context
step_name = "some_previous_step" # In a real workflow, this would be dynamic
# We serialize the event to JSON
input_payload = event_to_log.model_dump_json()
# Use a transaction to ensure atomic writes
with engine.connect() as connection:
with connection.begin() as transaction:
try:
sql = text("""
INSERT INTO workflow_logs (workflow_run_id, step_name, status, input_payload)
VALUES (:run_id, :step_name, :status, :payload::jsonb)
RETURNING log_id;
""")
result = connection.execute(
sql,
{
"run_id": workflow_run_id,
"step_name": step_name,
"status": "COMPLETED",
"payload": input_payload,
},
)
log_id = result.scalar_one()
transaction.commit()
print(f"Successfully logged event for run {workflow_run_id}. Log ID: {log_id}")
return LogEntryEvent(log_id=log_id)
except Exception as e:
print(f"Database transaction failed: {e}")
transaction.rollback()
raise
# To use this in a workflow:
# workflow.add_step(log_to_database_step, consumes=SomeOtherEvent)Querying Structured Data within a Workflow
Workflows can also retrieve data from a database to inform their execution. For instance, a step could fetch a user’s history to provide better context to an LLM. This combines the power of LLMs from sources like Hugging Face or Mistral AI with structured, reliable data from SQL databases.
-- This query retrieves the last 5 completed steps for a given workflow run
SELECT
step_name,
output_payload,
executed_at
FROM
workflow_logs
WHERE
workflow_run_id = :run_id AND status = 'COMPLETED'
ORDER BY
executed_at DESC
LIMIT 5;A Python step could execute this query to fetch context. This demonstrates how LlamaIndex Workflows can act as the glue between unstructured data processing with LLMs and structured data management in traditional databases, a crucial capability for enterprise-grade AI.
Advanced Techniques: Event-Driven Logic and Parallel Execution
The true power of LlamaIndex Workflows is realized when you move beyond sequential tasks and start implementing complex logic and parallel processing. The event-driven nature of the architecture is key to unlocking these advanced patterns.
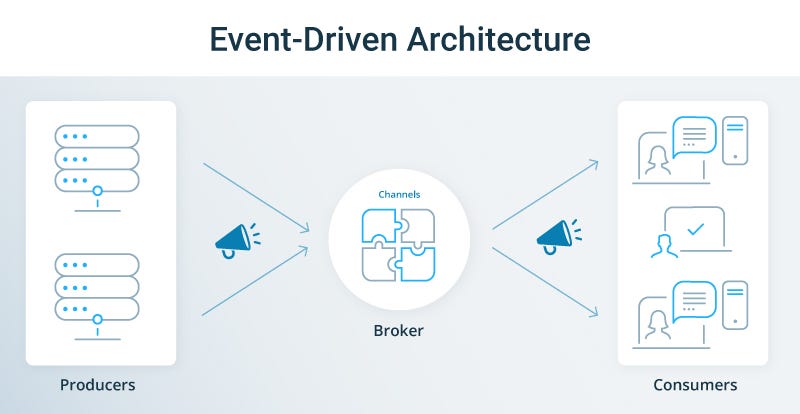
Conditional Branching with Event Listeners
Workflows can execute different branches of the graph based on the type or content of an event. This is achieved by having steps that consume specific event types. A “router” or “classifier” step can analyze input and emit one of several different event types, effectively directing the workflow down a specific path.
Imagine a workflow that handles user requests. A classifier step could determine if the user is asking a question (requiring a RAG pipeline) or requesting a data summary (requiring a SQL query). The step would then emit either a `QuestionEvent` or a `SummaryRequestEvent`, triggering the appropriate downstream steps.
from llama_index.core.workflow import Workflow, step, Event
from typing import Union
# --- Define Events for different branches ---
class GeneralQuestionEvent(Event):
query: str
class ReportRequestEvent(Event):
report_type: str
# --- Define Steps for each branch ---
@step
def route_request_step(context, query: str) -> Union[GeneralQuestionEvent, ReportRequestEvent]:
"""Classifies the user query and routes to the correct branch."""
if "report" in query.lower():
print("Routing to: Report Generation")
return ReportRequestEvent(report_type="sales_summary")
else:
print("Routing to: General Q&A")
return GeneralQuestionEvent(query=query)
@step
def rag_pipeline_step(context, event: GeneralQuestionEvent):
"""Handles general questions using a RAG pipeline."""
print(f"Executing RAG for query: {event.query}")
# ... RAG logic here ...
return Event(result="RAG pipeline result")
@step
def sql_report_step(context, event: ReportRequestEvent):
"""Generates a report by querying a SQL database."""
print(f"Generating SQL report for: {event.report_type}")
# ... Text-to-SQL or direct query logic here ...
return Event(result="SQL report result")
# --- Build the Workflow ---
branching_workflow = Workflow()
branching_workflow.add_step(route_request_step)
branching_workflow.add_step(rag_pipeline_step, consumes=GeneralQuestionEvent)
branching_workflow.add_step(sql_report_step, consumes=ReportRequestEvent)
# --- Run with different inputs ---
print("--- Running with a general question ---")
branching_workflow.run(query="What is LlamaIndex?")
print("\n--- Running with a report request ---")
branching_workflow.run(query="Generate a sales report.")Harnessing Parallelism and Indexing for Performance
The DAG structure is a natural fit for parallel execution. If a workflow has two steps that don’t depend on each other’s output, LlamaIndex can run them concurrently. For example, a step that retrieves data from a Weaviate vector store can run at the same time as a step that queries a user profile from a SQL database. A subsequent “joiner” step can then consume the outputs from both parallel steps once they are complete.
To ensure that database queries within these workflows are fast, proper indexing is non-negotiable. Our `workflow_logs` table, for instance, will be queried frequently by `workflow_run_id`. Adding an index is a simple but critical optimization.
-- Create an index on the workflow_run_id for fast lookups of a specific run's history.
CREATE INDEX idx_workflow_logs_run_id
ON workflow_logs (workflow_run_id);
-- An index on the timestamp can also be useful for time-based analysis.
CREATE INDEX idx_workflow_logs_executed_at
ON workflow_logs (executed_at DESC);This simple SQL command can dramatically improve the performance of any workflow steps that need to query the log history, ensuring the application remains responsive even as the log table grows.
Best Practices, Tooling, and the Broader AI Ecosystem
Building robust applications with LlamaIndex Workflows goes beyond just writing the code. Adhering to best practices and integrating with the right tools is essential for creating maintainable, scalable, and observable systems.
Best Practices for Designing Workflows
- Modularity: Design steps to be small, focused, and responsible for a single logical task. This makes them easier to test, reuse, and debug.
- Idempotency: Whenever possible, make steps idempotent—meaning that running them multiple times with the same input produces the same result. This is crucial for building reliable retry mechanisms.
- Configuration Management: Externalize configuration details like API keys, database URLs, and LLM model names (e.g., from Cohere or Google DeepMind). Don’t hardcode them in your steps.
- Observability: The complexity of DAGs makes tracing and debugging essential. Integrate with tools like Weights & Biases or LangSmith to visualize the execution flow, inspect inputs/outputs, and monitor performance.
Integrating with the AI Stack
LlamaIndex Workflows are designed to be a central orchestration layer, not an isolated component. They can seamlessly integrate a vast array of tools from the modern AI stack. A single workflow could leverage:
- Models: LLMs from OpenAI, open-source models via Hugging Face Transformers, or specialized models fine-tuned with PyTorch or TensorFlow.
- Data Sources: Vector databases like Chroma and Qdrant, relational databases, and APIs.
- Deployment Platforms: Workflows can be wrapped in a web server using FastAPI or Flask and deployed on services like Modal, Replicate, or enterprise platforms like Azure Machine Learning.
- Inference Optimization: For high-throughput scenarios, model inference steps can be accelerated using tools like NVIDIA’s TensorRT or frameworks like vLLM.
This interoperability is a testament to the vibrant open-source ecosystem and a key reason why recent LlamaIndex News is generating so much excitement.
Conclusion: Charting the Future of Complex AI Applications
The introduction of LlamaIndex Workflows marks a pivotal moment in the development of advanced AI applications. By moving from restrictive linear chains to a dynamic, event-driven DAG architecture, developers are now equipped with a far more powerful and flexible toolset. We’ve seen how this new paradigm enables sophisticated patterns like conditional branching and parallel execution, which are essential for building intelligent agents that can handle complex, real-world tasks.
Furthermore, the ability to deeply integrate these workflows with traditional data systems like SQL databases is not just a feature—it’s a requirement for building robust, stateful, and enterprise-ready solutions. By combining the reasoning power of LLMs with the reliability of structured data and transactional integrity, we can create applications that are both intelligent and dependable. As LlamaIndex Workflows move from beta to a stable release, the next step for developers is to start experimenting. Build your first multi-step workflow, integrate it with a database, and explore the new possibilities this architecture unlocks for your own AI-powered products.


