
Revolutionizing Recommender Systems: How Milvus and NVIDIA Merlin Deliver Unprecedented Performance and Simplicity
Introduction
In the digital age, recommender systems are the lifeblood of personalization, driving user engagement and revenue for platforms ranging from e-commerce giants to streaming services. However, building and deploying these systems at scale is a monumental challenge. Traditional methods often buckle under the weight of massive datasets, real-time latency requirements, and the sheer complexity of MLOps pipelines. The latest Milvus News highlights a groundbreaking collaboration that directly addresses these pain points: the integration of the Milvus vector database with NVIDIA’s Merlin framework. This powerful combination creates an end-to-end, GPU-accelerated pipeline for building state-of-the-art recommender systems. By leveraging Milvus for highly efficient vector similarity search and Merlin for data processing, model training, and inference, developers can now build solutions that are not only exceptionally performant but also significantly less complex to architect and maintain. This article explores the technical details of this integration, providing practical code examples and best practices to help you harness its full potential. This development is a significant piece of NVIDIA AI News, promising to reshape how we approach large-scale personalization.
The Core Components: A Synergy of Speed and Scale
To understand the power of this integration, it’s essential to first grasp the roles of its two key players: Milvus and NVIDIA Merlin. Each is a formidable tool in its own right, but together, they form a cohesive, end-to-end solution for modern recommender systems.
Milvus: The Engine for Vector Similarity Search
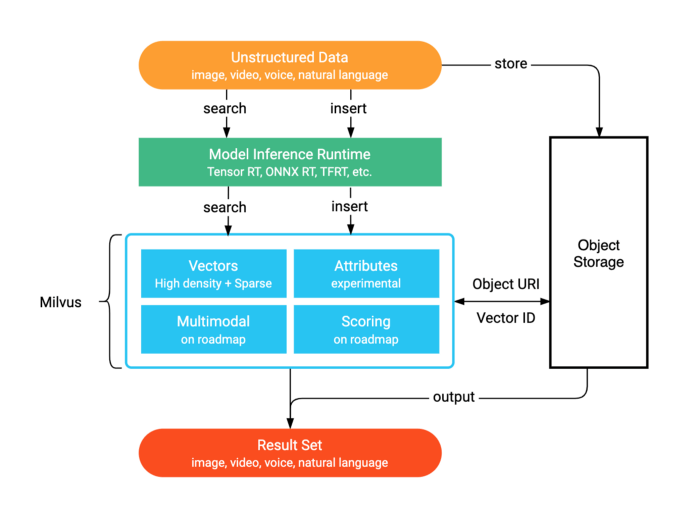
At its core, a recommender system’s job is to find “similar” items for a given user or item. In the era of deep learning, “similarity” is captured by embeddings—dense vector representations of users and items. Milvus is a purpose-built vector database designed to store, index, and search through billions of these embedding vectors at millisecond latencies. Unlike traditional databases, it’s optimized for Approximate Nearest Neighbor (ANN) search. Instead of building a custom search index from scratch using libraries like FAISS News, developers can offload this complex task to Milvus. It offers a variety of indexing algorithms (e.g., HNSW, IVF_FLAT) and, crucially, supports GPU-accelerated indexing via NVIDIA’s RAFT (Reusable Algorithmic Finetuning), making it a perfect match for a GPU-native ecosystem. This makes it a leading solution compared to alternatives discussed in Pinecone News or Weaviate News.
NVIDIA Merlin: The End-to-End Recommender Framework
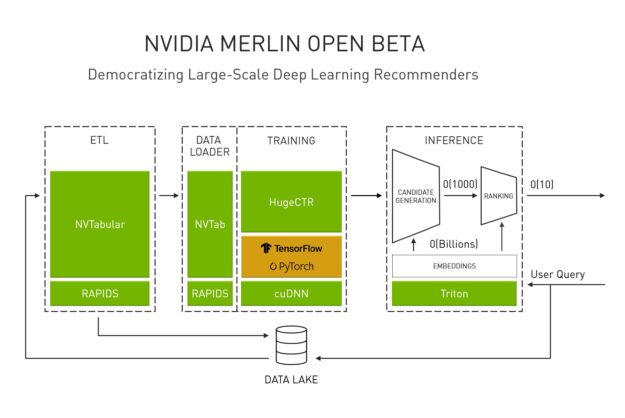
NVIDIA Merlin is not a single tool but a comprehensive framework that covers the entire recommender system lifecycle, all accelerated on NVIDIA GPUs. Its key components include:
- NVTabular: A feature engineering and preprocessing library designed to handle terabyte-scale datasets efficiently on GPUs, preparing data for model training.
- HugeCTR / Transformers4Rec: High-performance deep learning training frameworks optimized for click-through rate (CTR) prediction and sequential recommendation models. This is where models using insights from TensorFlow News or PyTorch News are trained at scale.
- Triton Inference Server: A high-performance inference serving solution that can deploy models from virtually any framework (TensorFlow, PyTorch, ONNX) and optimize them for production latency using tools like TensorRT.
The synergy is clear: Merlin handles the heavy lifting of data preparation and model training to produce high-quality embeddings. Milvus then takes these embeddings and provides a scalable, real-time search layer, effectively creating a highly performant two-stage recommender system.
# Conceptual: Defining a schema for item embeddings in Milvus
from pymilvus import CollectionSchema, FieldSchema, DataType, Collection
# 1. Define fields for our collection
# Primary key field
item_id_field = FieldSchema(
name="item_id",
dtype=DataType.INT64,
is_primary=True,
)
# Item embedding vector field
item_embedding_field = FieldSchema(
name="item_embedding",
dtype=DataType.FLOAT_VECTOR,
dim=128 # Dimension of embeddings from the Merlin model
)
# Optional: A field for item category for metadata filtering
category_field = FieldSchema(
name="category",
dtype=DataType.VARCHAR,
max_length=256
)
# 2. Create the collection schema
schema = CollectionSchema(
fields=[item_id_field, item_embedding_field, category_field],
description="Item embeddings for recommender system",
enable_dynamic_field=False
)
# 3. Create the collection in Milvus
collection_name = "movie_recs"
collection = Collection(
name=collection_name,
schema=schema,
using='default', # Connection alias
consistency_level="Strong"
)
print(f"Successfully created collection: '{collection_name}'")Implementation Deep Dive: Building a Two-Stage Recommender
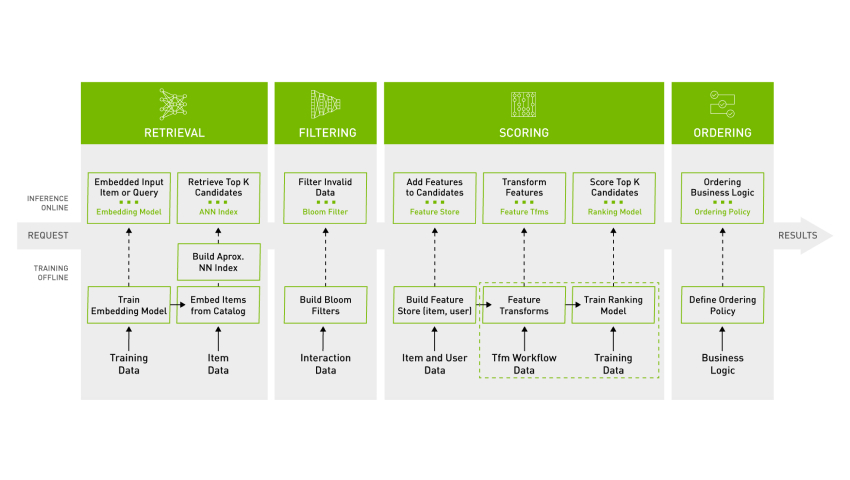
A common and effective architecture for large-scale recommenders is the two-stage system. The first stage (candidate generation) quickly filters millions of items down to a few hundred relevant candidates. The second stage (ranking) uses a more complex model to precisely rank this smaller set. The Milvus and Merlin combination excels at powering this architecture.
Stage 1: Candidate Generation with Milvus
After training a two-tower model with Merlin, where one tower produces user embeddings and the other produces item embeddings, the first step is to index all item embeddings into Milvus. This is a one-time (or periodic) batch process.
First, you need to create an index on the vector field for efficient searching. For GPU-powered search, you can leverage the `CAGRA` index from the RAFT library.
# Indexing item embeddings for fast retrieval
from pymilvus import Collection, utility
# Assuming 'collection' is the Collection object from the previous step
collection = Collection("movie_recs")
# 1. Define the index parameters
# For GPU-accelerated search, we use CAGRA (powered by RAFT)
index_params = {
"metric_type": "L2", # Or IP for inner product
"index_type": "GPU_CAGRA",
"params": {
"intermediate_graph_degree": 64,
"graph_degree": 32,
"build_algo": "IVF_PQ", # Algorithm for building the index
}
}
# 2. Create the index on the embedding field
collection.create_index(
field_name="item_embedding",
index_params=index_params
)
# 3. Load the collection into memory for searching
collection.load()
print(f"Index created and collection loaded. Ready for search.")
print(utility.index_building_progress("movie_recs"))Once the item embeddings are indexed, real-time candidate generation becomes straightforward. When a user requests recommendations, you generate their embedding using the user tower of your model (often served via Triton Inference Server). This user embedding is then used to query Milvus to find the top-K most similar item embeddings.
# Performing a real-time search for a given user embedding
import numpy as np
# Assume 'collection' is our loaded Milvus collection
# Assume 'get_user_embedding' is a function that returns a user's 128-dim vector
def get_recommendations(user_id: int, top_k: int = 100):
"""
Generates top-K candidates for a user from Milvus.
"""
# 1. Generate the user embedding (this would typically be a call to a model server)
# For this example, we'll use a random vector
user_embedding = [np.random.rand(128).astype('float32')]
# 2. Define search parameters
search_params = {
"metric_type": "L2",
"params": {
"search_width": 128, # Number of nodes to visit during search
}
}
# 3. Execute the search query against Milvus
results = collection.search(
data=user_embedding,
anns_field="item_embedding",
param=search_params,
limit=top_k,
output_fields=["item_id", "category"] # Also retrieve metadata
)
# 4. Process and return the results
retrieved_ids = []
for hit in results[0]:
retrieved_ids.append(hit.id)
# print(f"Item ID: {hit.id}, Distance: {hit.distance}, Category: {hit.entity.get('category')}")
return retrieved_ids
# Example usage
user_id = 12345
candidate_item_ids = get_recommendations(user_id)
print(f"Generated {len(candidate_item_ids)} candidates for user {user_id}: {candidate_item_ids[:10]}...")Stage 2: Re-ranking with a Triton-Served Model
The list of `candidate_item_ids` from Milvus is the input to the second stage. Here, a more powerful and feature-rich ranking model (e.g., a deep cross-network or a transformer) is used to score and re-order these candidates. This model, also trained using Merlin, can consider complex interactions between user features and item features that are too computationally expensive to evaluate across the entire item catalog. This ranking model is deployed on Triton Inference Server for low-latency production serving. This pattern ensures the system is both scalable and highly accurate.
Advanced Techniques and Ecosystem Integration
The Merlin and Milvus stack provides a solid foundation, but its power can be extended further by integrating with the broader MLOps and AI ecosystem. This is where tools discussed in MLflow News or platforms like AWS SageMaker and Vertex AI come into play.
Handling Dynamic Data and Cold Starts
Real-world item catalogs are not static. New items are added, and old ones are removed. Milvus handles this gracefully with support for insertions and deletions. For the “cold start” problem (recommending for new users or items), you can use average embeddings or feature-based embeddings as a starting point. As you gather more interaction data, these embeddings can be updated. Experiment tracking tools like those featured in Weights & Biases News are invaluable for managing these different embedding generation strategies.
Incorporating Multimodal and Language Features
Modern recommenders often go beyond simple user-item interactions. By using models from sources like Hugging Face Transformers News or multimodal architectures, you can create embeddings that incorporate text descriptions, images, and other rich features. For instance, a movie’s embedding could be a combination of its genre, user ratings, and an embedding of its poster image. Milvus can index these rich, high-dimensional vectors just as easily, enabling powerful multimodal search. This also opens the door to conversational recommendation, where frameworks from LangChain News or LlamaIndex News could be used to translate a user’s natural language query into an embedding to search against the Milvus index.
Hybrid Search: Combining Vector and Scalar Filtering
Sometimes, you need to filter candidates based on metadata before performing the vector search. For example, “find movies similar to ‘The Matrix’ but only from the ‘Sci-Fi’ category and released after 2010.” Milvus supports powerful boolean expression filtering on scalar fields alongside the ANN search. This allows you to pre-filter the search space, leading to more relevant results and often lower latency. This is a significant advantage over simpler vector search libraries.
Best Practices and Optimization Strategies
To get the most out of the Milvus and Merlin integration, consider the following best practices:
- Choose the Right Index: The choice of index in Milvus is critical. For GPU-centric workloads, `GPU_CAGRA` is a top performer. For CPU-based serving, `HNSW` offers an excellent balance of speed and accuracy. Always benchmark different index types and parameters with your own data.
- Batch Everything: For both data insertion into Milvus and inference calls to Triton, batching is key. Sending single requests is inefficient. Group user requests or data insertions into batches to maximize GPU utilization and throughput. Frameworks like Ray or Dask can help manage this distributed computation.
- Optimize Your Embeddings: The dimensionality of your embeddings impacts storage costs, memory usage, and search speed. Experiment with different dimensions. Techniques like Product Quantization (PQ), supported by Milvus, can further compress vectors to reduce the memory footprint at the cost of some accuracy.
- Monitor and Tune: Use monitoring tools to track query latency, QPS (queries per second), and recall. Both Milvus and Triton expose Prometheus metrics. Continuously tune search parameters (like `search_width` or `ef`) and index parameters to meet your application’s specific latency and accuracy requirements.
Conclusion: The Future of Personalization is Here
The integration of Milvus with NVIDIA Merlin marks a significant milestone in the evolution of recommender systems. By abstracting away the immense complexity of building and scaling a vector search infrastructure, it allows data scientists and engineers to focus on what they do best: designing and training powerful models. The result is a seamless, end-to-end, GPU-accelerated pipeline that delivers state-of-the-art performance while reducing development time and operational overhead.
The key takeaways are clear: this combination provides a highly performant, scalable, and simplified architecture for modern personalization. As AI continues to evolve, with trends from OpenAI News and Google DeepMind News pushing the boundaries of model capabilities, having a robust and flexible backend like the Milvus and Merlin stack will be crucial. For any organization looking to build or upgrade its recommender systems, this powerful duo represents a clear and compelling path forward, promising a future of faster, smarter, and more engaging user experiences.


