
A Deep Dive into ClearML’s New Features: Revolutionizing the MLOps Lifecycle
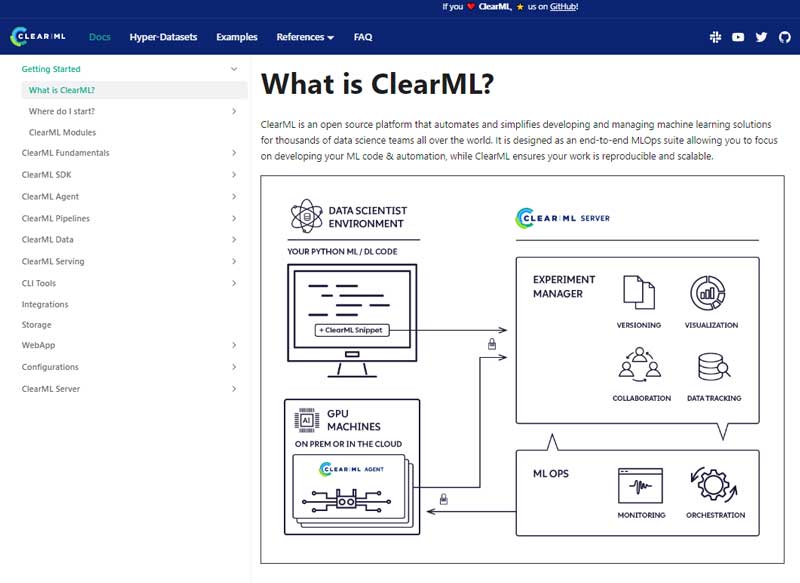
The machine learning operations (MLOps) landscape is a whirlwind of constant innovation. As models grow in complexity and the pace of research accelerates, the need for a robust, unified platform to manage the entire ML lifecycle—from initial experiment to production deployment—has never been more critical. In this dynamic environment, ClearML has solidified its position as a leading open-source MLOps solution, empowering teams to collaborate, iterate, and deploy with unprecedented efficiency.
Recent advancements in the platform are pushing the boundaries of what’s possible, particularly in bridging the notorious gap between model development and real-world deployment. This article provides a comprehensive technical exploration of ClearML’s core capabilities and its latest features. We’ll dive into practical code examples, best practices, and how ClearML integrates into the modern AI stack, which includes the latest developments from the PyTorch News and TensorFlow News communities. Whether you’re fine-tuning a model from the Hugging Face News hub or building a complex pipeline for a proprietary algorithm, understanding these features is key to streamlining your workflow and accelerating your time to production.
Foundational Pillars: Experiment Management and Data Versioning
Before exploring the newest features, it’s essential to understand the foundation upon which ClearML is built. Its two primary pillars—seamless experiment tracking and robust data versioning—solve some of the most persistent challenges in machine learning development: reproducibility and traceability.
Seamless Experiment Tracking
One of ClearML’s most powerful features is its ability to automatically log and manage every detail of your training runs with minimal code intrusion. By adding just two lines of Python code to your script, ClearML captures:
- The entire code state, including uncommitted changes from your Git repository.
- A complete list of installed Python packages and their versions.
- Hyperparameters, whether defined via argument parsers, configuration files, or directly in the code.
- Scalar metrics (like loss and accuracy), plots, images, and debug samples reported during training.
- Console output (both stdout and stderr).
- Model artifacts and checkpoints saved during the process.
This comprehensive logging ensures that any experiment can be perfectly reproduced, analyzed, and compared. Consider a standard training script using PyTorch. Integrating ClearML is remarkably simple.
# main_train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from clearml import Task
# Step 1: Initialize the ClearML Task
# This will automatically connect to the ClearML server and create a new experiment
task = Task.init(
project_name="Image Classification",
task_name="PyTorch MNIST Training Example"
)
# A simple CNN model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = torch.relu(x)
x = self.conv2(x)
x = torch.relu(x)
x = torch.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
output = torch.log_softmax(x, dim=1)
return output
def main():
# Connect hyperparameters to the Task
params = {
'lr': 0.01,
'momentum': 0.5,
'epochs': 2,
'batch_size': 64,
}
params = task.connect(params)
# Standard PyTorch data loading
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset = datasets.MNIST('../data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset, batch_size=params['batch_size'])
model = Net()
optimizer = optim.SGD(model.parameters(), lr=params['lr'], momentum=params['momentum'])
# Training loop
for epoch in range(1, params['epochs'] + 1):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f"Epoch {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.6f}")
# Step 2: Report metrics to ClearML
task.get_logger().report_scalar(
title="Training Loss",
series="loss",
value=loss.item(),
iteration=(epoch - 1) * len(train_loader) + batch_idx
)
# Save the model
torch.save(model.state_dict(), "mnist_cnn.pt")
print("Training finished. Model saved.")
if __name__ == '__main__':
main()Robust Data Versioning with ClearML-Data
Reproducibility extends beyond code to the data itself. ClearML-Data provides a powerful mechanism for creating immutable, versioned datasets. It functions like Git for your data, allowing you to track changes, link specific data versions to experiments, and ensure that your training runs are always using the exact same data split. This is crucial for debugging, auditing, and maintaining model integrity over time, especially when dealing with the large datasets required by models emerging from Meta AI News or Google DeepMind News.
From Model Registry to Inference: A Look at New Deployment Capabilities
While experiment tracking is foundational, the ultimate goal is to get models into production. ClearML has introduced powerful new features to streamline this transition, making deployment more accessible, iterative, and integrated.

The Unified Model Registry
Once an experiment produces a promising model artifact, it can be promoted to the ClearML Model Registry with a single click in the UI or a line of code. The registry acts as a central hub for all your production-ready models, providing versioning, metadata, and a clear lineage back to the experiment and data that created it. This centralized approach is vital for governance and collaboration, ensuring that everyone on the team knows which model is the latest and greatest. It also facilitates deployment by supporting standard formats, and the latest ONNX News shows a growing trend towards framework-agnostic runtimes, which ClearML readily supports.
Introducing “Sneak Peek” Deployments
A standout new feature is the concept of a “sneak peek” deployment. This addresses a common MLOps pain point: the need for quick, temporary model validation without the overhead of a full production deployment pipeline. A sneak peek provides a REST API endpoint for a model directly from the model registry or even an ongoing experiment. This allows data scientists and engineers to:
- Quickly test a model’s behavior with real-world inputs.
- Share a live model demo with stakeholders or product managers.
- Perform integration testing with downstream applications.
You can interact with this temporary endpoint programmatically. For instance, after deploying a model that expects a JSON payload, you can test it using Python’s requests library.
import requests
import json
# URL provided by the ClearML UI for the "sneak peek" deployment
# This is a hypothetical URL and will be unique for your deployment
SNEAK_PEEK_URL = "http://localhost:8080/serve/iris-classifier"
# Sample data for an Iris classification model (sepal length, sepal width, petal length, petal width)
# The expected input format depends on your model's serving script
input_data = {
"inputs": [
{
"name": "features",
"shape": [1, 4],
"datatype": "FP32",
"data": [5.1, 3.5, 1.4, 0.2]
}
]
}
headers = {"Content-Type": "application/json"}
try:
response = requests.post(url=SNEAK_PEEK_URL, headers=headers, data=json.dumps(input_data))
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
# The output format will depend on your model's post-processing logic
prediction = response.json()
print(f"Request successful!")
print(f"Model Prediction: {prediction}")
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
Scaling with ClearML Serving and Kubernetes
While sneak peeks are for temporary validation, the path to a scalable, resilient production environment runs through clearml-serving. This component is designed to deploy models on Kubernetes, leveraging its power for auto-scaling, load balancing, and fault tolerance. It can serve models optimized with tools like NVIDIA AI News‘s TensorRT or Intel’s OpenVINO. This provides a clear, manageable path from a single-replica test deployment to a high-throughput production service, rivaling the capabilities of dedicated platforms like AWS SageMaker News or Vertex AI News but with the flexibility of being open-source and cloud-agnostic.
Orchestrating Complex Pipelines and Ecosystem Integrations
Modern machine learning is rarely a single training script. It’s a complex web of data ingestion, preprocessing, training, evaluation, and deployment. ClearML Pipelines allows you to define these multi-stage workflows as code, creating a Directed Acyclic Graph (DAG) of execution.
Building and Automating Pipelines
With ClearML Pipelines, each step in your workflow becomes a component that can be executed independently, often on different hardware using clearml-agent. This modular approach promotes reusability and simplifies complex processes. For example, you can define a pipeline that first processes data, then trains a model, and finally evaluates its performance.
# pipeline_definition.py
from clearml import PipelineController
# Define the pipeline controller
pipe = PipelineController(
name="Complete Training Pipeline",
project="ML Pipelines",
version="1.0"
)
# Use a specific execution queue for all steps in this pipeline
pipe.set_default_execution_queue("default")
# Define Step 1: Data Preprocessing
# This assumes you have a script 'preprocess.py' checked into your Git repository
# which has already been run once and logged as a Task in ClearML.
pipe.add_step(
name="data_preprocessing",
base_task_project="Data Preparation",
base_task_name="Initial data cleaning"
)
# Define Step 2: Model Training
# This step depends on the output of the preprocessing step.
# We can pass artifacts (like a processed dataset ID) from one step to another.
pipe.add_step(
name="model_training",
parents=["data_preprocessing"],
base_task_project="Image Classification",
base_task_name="PyTorch MNIST Training Example",
parameter_override={
"Args/dataset_id": "${data_preprocessing.artifacts.processed_data.id}"
}
)
# Define Step 3: Model Evaluation
pipe.add_step(
name="model_evaluation",
parents=["model_training"],
base_task_project="Model Analysis",
base_task_name="Calculate validation metrics",
parameter_override={
"Args/model_id": "${model_training.models.output.-1.id}"
}
)
# Start the pipeline execution locally (for debugging)
# In production, you would typically upload and run this from the UI or CI/CD
pipe.start_locally(run_pipeline_steps_locally=False)
print("Pipeline started! Check the ClearML UI for progress.")
This declarative pipeline-as-code approach provides a powerful alternative to other orchestration tools like MLflow News or Kubeflow Pipelines, with tight integration into the rest of the ClearML ecosystem. For distributed workloads within a pipeline step, ClearML also integrates with frameworks like Ray News and Dask News.
The Expanding Ecosystem: From LLMs to Vector Databases
The rise of Generative AI and Large Language Models (LLMs) has introduced new MLOps challenges. ClearML is actively expanding to meet these needs. You can now effectively track experiments involving popular frameworks like LangChain News and LlamaIndex News. This includes logging prompts, chains, and evaluation metrics from tools like LangSmith News. Furthermore, when building Retrieval-Augmented Generation (RAG) systems, you can use ClearML-Data to version the document chunks and even the resulting vector embeddings before they are loaded into a vector database like Pinecone News, Weaviate News, or Milvus News.
Best Practices and Optimizing Your ClearML Workflow
To get the most out of ClearML, adopting a few best practices can significantly improve your team’s efficiency and the scalability of your MLOps processes.
Structuring Projects for Scalability
Use ClearML projects to logically group related experiments. For example, create separate projects for “Data Exploration,” “Feature Engineering,” and “Model Training.” Within a project, use consistent task naming and tags to make experiments easy to find, filter, and compare. This organization becomes invaluable as your team and the number of experiments grow.
Leveraging Remote Execution with clearml-agent
The true power of ClearML is unlocked with remote execution. A clearml-agent is a daemon process that you can run on any machine—a powerful on-premise GPU server, a cloud VM, or a Kubernetes cluster. The agent listens to specific queues for tasks to execute. This architecture allows you to:
- Develop on a laptop, train on a supercomputer: Write your code locally, and with a simple command, clone the experiment and enqueue it for execution on a powerful remote machine.
- Manage resources effectively: Create different queues for different hardware types (e.g., `gpu_high_memory`, `cpu_intensive`) and prioritize critical jobs.
- Ensure a reproducible environment: The agent automatically recreates the experiment’s Python environment, ensuring the code runs exactly as it did during development.
This workflow provides a self-hosted, flexible alternative to cloud-based execution platforms like Modal News or Replicate News.
Collaboration and Reporting
Don’t overlook the UI. The ClearML web interface is a powerful collaborative tool. Use it to compare the performance of multiple experiments side-by-side, create custom leaderboards to track progress on a specific task, and build detailed reports with plots and notes to share with stakeholders. This transparency is key to aligning technical teams and business objectives, a goal shared by platforms like Weights & Biases News and Comet ML News.
Conclusion
The MLOps field is maturing, and the focus is shifting from isolated tools to integrated platforms that cover the entire lifecycle. ClearML’s recent advancements, especially features like “sneak peek” deployments and robust pipeline orchestration, demonstrate a clear commitment to solving real-world engineering challenges. By providing a unified, open-source solution for experiment tracking, data versioning, model deployment, and automation, ClearML empowers data science and machine learning teams to move faster and with greater confidence.
As the AI world continues to be shaped by developments from OpenAI News, Anthropic News, and the open-source community, having a versatile MLOps backbone is no longer a luxury but a necessity. By integrating ClearML into your workflow, you can build a scalable, reproducible, and collaborative environment that is ready to tackle the next generation of machine learning challenges. The next step is to explore the platform, integrate the SDK into your next project, and experience firsthand how it can streamline your path from idea to impact.


