
AutoML in 2024: Bridging the Gap Between Development and Production with Integrated MLOps
The democratization of artificial intelligence has been a long-standing goal in the tech community, promising to unlock predictive power for organizations of all sizes, regardless of their in-house expertise. At the heart of this movement is Automated Machine Learning (AutoML), a discipline focused on automating the complex, iterative, and often tedious tasks of building machine learning models. For years, AutoML was seen primarily as a tool for algorithm selection and hyperparameter tuning. However, the latest AutoML News reveals a profound transformation. Modern AutoML is no longer a standalone utility; it has evolved into a deeply integrated component of the end-to-end MLOps lifecycle.
This evolution addresses a critical bottleneck in AI adoption: the gap between a promising model in a notebook and a reliable, production-grade AI system. Today’s leading platforms are infusing AutoML with robust MLOps capabilities, offering simplified development workflows, real-time model insights, and automated governance. This shift is enabling teams to build, deploy, and manage AI models faster and with greater confidence. From cloud giants with offerings like Vertex AI and AWS SageMaker to the vibrant open-source ecosystem, the focus is clear: make AI not just powerful, but also practical, scalable, and trustworthy.
The Evolution of AutoML: Beyond Hyperparameter Tuning
To appreciate the current landscape, it’s essential to understand how far AutoML has come. Its initial promise was to solve the Combined Algorithm Selection and Hyperparameter optimization (CASH) problem, a computationally intensive search for the best model and its settings. While revolutionary, this represented only a fraction of the machine learning workflow. The true value is unlocked when automation extends across the entire pipeline.
From Niche Tool to Core Platform Component
Early AutoML tools were often used in isolation, producing a model artifact that was then handed off to an engineering team for a separate, manual deployment process. This created silos and slowed down iteration. The modern paradigm, however, treats AutoML as a foundational layer of an integrated machine learning platform. This means automation is now applied to:
- Data Preprocessing and Cleaning: Automatically handling missing values, scaling numerical features, and encoding categorical variables.
- Feature Engineering: Systematically creating and selecting new features from raw data to improve model performance. This can involve generating polynomial features, interaction terms, or time-series-based attributes.
- Model Selection and Architecture Search: Moving beyond just choosing between scikit-learn models to include sophisticated deep learning architectures from frameworks like TensorFlow and PyTorch. Neural Architecture Search (NAS) automates the very design of the neural network itself.
A Practical Look at Foundational AutoML
Open-source libraries like auto-sklearn and FLAML provide an excellent entry point for experiencing this automated workflow. They encapsulate the core principles of searching through a vast space of pipelines (preprocessor + model) to find the one that performs best on a given dataset, all with minimal code.
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics
# 1. Load a standard dataset
X, y = sklearn.datasets.load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = \
sklearn.model_selection.train_test_split(X, y, random_state=42)
# 2. Initialize the AutoML classifier
# We give it a total time limit and a limit per single model run.
# n_jobs=-1 uses all available CPU cores.
automl = autosklearn.classification.AutoSklearnClassifier(
time_left_for_this_task=120, # Total time in seconds
per_run_time_limit=30, # Time limit for a single model
n_jobs=-1,
)
# 3. Start the automated search process
print("Starting AutoML search...")
automl.fit(X_train, y_train, dataset_name='digits')
# 4. Display the results of the search
# show_models() reveals the final ensemble of models found.
print("\n--- AutoML Search Results ---")
print(automl.show_models())
# 5. Evaluate the final ensemble on the test set
y_hat = automl.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(y_test, y_hat)
print(f"\nAccuracy score on test data: {accuracy:.4f}")This single .fit() call abstracts away thousands of potential decisions, from data scaling methods to the choice between a random forest and a support vector machine, delivering a high-performing model pipeline automatically.

The MLOps Convergence: Deploying and Monitoring with Confidence
Finding a good model is only half the battle. The true challenge lies in operationalizing it. This is where the convergence of AutoML and MLOps becomes a game-changer. The latest MLflow News and updates from platforms like Weights & Biases and ClearML highlight a strong trend toward seamless integration, transforming AutoML from a potential “black box” into a transparent and manageable asset.
Why MLOps is Crucial for AutoML
Without a strong MLOps foundation, AutoML can create more problems than it solves. A model that performs well today might degrade silently in production due to data drift. An automated process that isn’t reproducible is a liability in regulated industries. MLOps provides the necessary guardrails:
- Reproducibility: Tracking every artifact, parameter, and data version used during the AutoML search ensures that any resulting model can be recreated and audited.
- Model Lineage: Understanding which dataset and which search configuration produced a specific model is vital for debugging and governance.
- Automated Deployment: Integrating AutoML with CI/CD pipelines allows the best-found model to be automatically packaged (e.g., using ONNX for interoperability) and deployed to inference servers like NVIDIA Triton Inference Server.
- Continuous Monitoring: Once deployed, models must be monitored for performance degradation, data drift, and prediction fairness. This feedback loop can trigger an automated retraining run by the AutoML system.
Integrating Experiment Tracking with AutoML
Experiment tracking tools are the cornerstone of MLOps. By logging every run from an AutoML process, data science teams gain full visibility. This allows them to compare different search strategies, analyze the trade-offs between model complexity and performance, and select a final model with confidence. Here’s how a simulated AutoML hyperparameter search can be logged using MLflow.
import mlflow
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
# Set up MLflow to log to a local file database
mlflow.set_tracking_uri("sqlite:///mlflow.db")
mlflow.set_experiment("AutoML HPO Experiment")
# Load data
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Simulate an AutoML hyperparameter search for a Logistic Regression model
C_values = [0.1, 1.0, 5.0, 10.0]
solvers = ['liblinear', 'saga']
print("Starting simulated AutoML run with MLflow tracking...")
for c_param in C_values:
for solver_param in solvers:
# Each combination is a new run within the experiment
with mlflow.start_run():
# Log the hyperparameters being tested
mlflow.log_param("C", c_param)
mlflow.log_param("solver", solver_param)
# Train the model
model = LogisticRegression(C=c_param, solver=solver_param, max_iter=2000)
model.fit(X_train, y_train)
# Evaluate the model and log the performance metric
accuracy = accuracy_score(y_test, model.predict(X_test))
mlflow.log_metric("accuracy", accuracy)
# Log the trained model as an artifact for later use
mlflow.sklearn.log_model(model, f"logreg-model-C{c_param}-{solver_param}")
print(f" Logged run: C={c_param}, solver={solver_param}, Accuracy={accuracy:.4f}")
print("\nExperiment finished. Run 'mlflow ui' in your terminal to see the results.")After running this script, you can launch the MLflow UI to see a dashboard comparing all the runs, making it easy to identify the top-performing model and its corresponding parameters.
Advanced AutoML Frontiers: Neural Architecture Search and Generative AI
The principles of automation are now being applied to the most complex and cutting-edge areas of AI. This is where AutoML is evolving from a tool for classical machine learning into a critical enabler for deep learning and Large Language Models (LLMs).
Automating the Design of Neural Networks
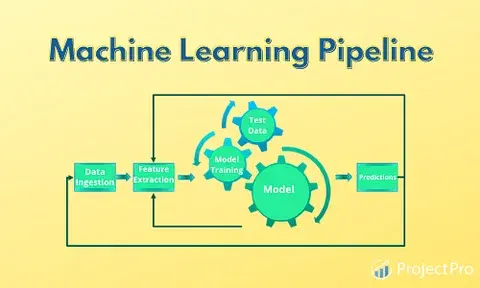
Neural Architecture Search (NAS) is a subfield of AutoML that focuses on automatically designing the optimal topology of a neural network. Instead of manually deciding the number of layers, the type of convolutions, or the activation functions, NAS algorithms explore a vast search space of possible architectures. While computationally intensive, requiring frameworks like Ray or Dask for distributed training, recent Google DeepMind News and research have introduced more efficient methods. NAS is particularly impactful in computer vision and sequence modeling, often discovering novel architectures that outperform human-designed ones.
AutoML for the Generative AI Lifecycle
The explosion of Generative AI, fueled by models from OpenAI, Anthropic, Mistral AI, and Meta AI, has created a new set of complex workflows. AutoML is rapidly adapting to automate key parts of this lifecycle:
- Automated Fine-Tuning: Finding the best hyperparameters (learning rate, batch size, number of epochs) for fine-tuning a model from Hugging Face Transformers on a custom dataset is a perfect use case for HPO tools like Optuna.
- RAG Pipeline Optimization: Retrieval-Augmented Generation (RAG) systems have many tunable parts. AutoML can be used to select the best embedding model from Sentence Transformers, choose the optimal chunking strategy, and find the right vector database (e.g., Pinecone, Milvus, Weaviate) configuration for a specific use case. Frameworks like LangChain and LlamaIndex are becoming prime targets for this type of automation.
This code snippet shows how Optuna, a powerful hyperparameter optimization framework, can be used to find the best learning rate and batch size for fine-tuning a Hugging Face model.
import optuna
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, TrainingArguments, Trainer
import numpy as np
import evaluate
# This example requires `pip install optuna transformers datasets evaluate accelerate`
# Use a small subset for a quick demonstration
dataset = load_dataset("yelp_review_full", split="train[0:500]")
tokenized_ds = dataset.train_test_split(test_size=0.2, seed=42)
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_train = tokenized_ds["train"].map(tokenize_function, batched=True)
tokenized_eval = tokenized_ds["test"].map(tokenize_function, batched=True)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
def model_init():
return AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=5)
def objective(trial):
# Define the search space for hyperparameters
training_args = TrainingArguments(
output_dir="./optuna_results",
evaluation_strategy="epoch",
disable_tqdm=True,
learning_rate=trial.suggest_float("learning_rate", 1e-5, 5e-5, log=True),
per_device_train_batch_size=trial.suggest_categorical("batch_size", [8, 16]),
num_train_epochs=2, # Keep epochs low for demo
)
trainer = Trainer(
model_init=model_init,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_eval,
compute_metrics=compute_metrics,
)
trainer.train()
eval_result = trainer.evaluate()
return eval_result["eval_accuracy"]
# Create a study object and optimize the objective function.
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=8) # Run 8 trials to find best params
print("Best trial found:")
best_trial = study.best_trial
print(f" Accuracy: {best_trial.value:.4f}")
print(" Best hyperparameters: ", best_trial.params)Practical Guidance: Best Practices and Choosing Your AutoML Solution
Adopting AutoML successfully requires a strategic approach. It’s not a magic wand but a powerful accelerator that yields the best results when guided by clear goals and domain expertise.
Key Considerations for Implementation
- Start with the Business Problem: Define the success metric clearly before you begin. Is it reducing customer churn, improving forecast accuracy, or classifying support tickets? The business goal should drive the technical choices.
- Data Quality is Paramount: The “garbage in, garbage out” principle applies forcefully to AutoML. Invest time in understanding, cleaning, and preparing your data. No amount of automation can compensate for poor data quality.
- Balance Automation and Control: Use AutoML to explore a wide range of possibilities quickly, but use your domain knowledge to constrain the search space. For example, if you know a certain feature is nonsensical, exclude it. Review the top-performing models to ensure they are interpretable and make business sense.
- Manage Computational Costs: AutoML can be resource-intensive. Set realistic time or budget constraints for the search process. This is especially critical on cloud platforms like Azure Machine Learning, where extensive searches can incur significant costs.
Open Source vs. Commercial Platforms
The choice between open-source tools and commercial platforms depends on your team’s skills, budget, and infrastructure.
- Open Source (e.g., Auto-Keras, FLAML, Optuna): These tools offer maximum flexibility and prevent vendor lock-in. They are excellent for learning and for teams with strong engineering capabilities who can manage the underlying infrastructure. You can run them anywhere, from your laptop to a Google Colab notebook.
- Commercial Platforms (e.g., Google Vertex AI, AWS SageMaker Autopilot, DataRobot, H2O.ai): These solutions provide a fully managed, end-to-end experience with integrated data storage, experiment tracking, model registries, and one-click deployment. They are ideal for enterprises seeking to accelerate AI adoption with built-in governance and support. The emergence of offerings like Snowflake Cortex News also shows a trend of data warehouses embedding AutoML directly, simplifying the path from data to insight.
Conclusion: The Future is Automated and Integrated
The narrative of AutoML has fundamentally shifted. It has matured from a promising but isolated tool for model building into the automated engine of the modern MLOps platform. The most significant AutoML News today is not about beating a benchmark by a fraction of a percent, but about reliability, speed, and integration. By automating the full lifecycle—from feature engineering to production monitoring—these systems empower data scientists to focus on high-impact strategic work rather than repetitive tuning.
This convergence of AutoML and MLOps democratizes access to powerful AI, enabling more organizations to build and deploy robust, valuable machine learning solutions. As the technology continues to advance, especially in the realm of Generative AI, this integrated approach will become even more critical, accelerating innovation and turning the promise of AI into tangible business reality.


