
Building Advanced RAG Applications with .NET and Qdrant: A Deep Dive into Microsoft.Extensions.VectorData
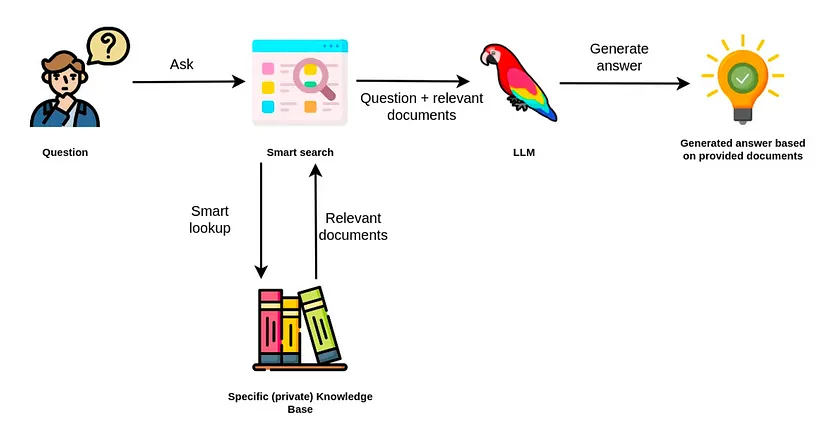
The landscape of software development is being reshaped by the rapid advancements in Generative AI. At the heart of many intelligent applications, from sophisticated chatbots to semantic search engines, lies the concept of Retrieval-Augmented Generation (RAG). This powerful technique grounds Large Language Models (LLMs) with factual, domain-specific data, drastically reducing hallucinations and improving response accuracy. To implement RAG effectively, developers need a robust and efficient way to store and retrieve high-dimensional data, which is where vector databases come into play.
Qdrant has emerged as a leading open-source vector database, celebrated for its high performance, powerful filtering capabilities, and resource efficiency. It’s designed from the ground up to handle billions of vectors with ease. For developers in the .NET ecosystem, the integration of such powerful AI infrastructure has just become significantly easier. Microsoft’s new Microsoft.Extensions.VectorData library provides a standardized, pluggable abstraction layer for interacting with vector stores. This allows developers to build applications that can seamlessly switch between different backends like Qdrant, Milvus, or Azure AI Search with minimal code changes. This article provides a comprehensive guide to leveraging the power of Qdrant within your .NET applications using this new library, complete with practical code examples and best practices.
Core Concepts: Bridging the .NET and Vector Search Worlds
Before diving into the implementation details, it’s crucial to understand the fundamental concepts that power vector search. These principles are the bedrock upon which modern AI-driven search and RAG systems are built, and the new .NET library provides an elegant bridge to this technology.
Understanding Vector Embeddings and Similarity Search
At its core, vector search revolves around vector embeddings. An embedding is a numerical representation of data—be it text, an image, or audio—in the form of a high-dimensional vector (an array of numbers). These vectors are generated by deep learning models, such as those found in the Hugging Face Transformers News or from powerful APIs provided by OpenAI News or Azure AI News. The magic of these models is that they place semantically similar items close to each other in the vector space. For example, the text “king” and “queen” will have vectors that are much closer together than “king” and “car.”
Vector similarity search is the process of finding the vectors in a database that are closest to a given query vector. This “closeness” is typically measured using mathematical formulas like Cosine Similarity or Dot Product. By finding the nearest neighbors, we can retrieve the most semantically relevant documents or data points, which is the foundational operation for any RAG pipeline.
Introducing Microsoft.Extensions.VectorData
The Microsoft.Extensions.VectorData library is a game-changer for .NET developers. It introduces a common abstraction, the VectorStore, which decouples your application’s logic from the specific vector database implementation. This follows the best practices of modern software design, promoting modularity and flexibility.
The key benefits include:
- Portability: Write your search and indexing logic once and easily switch between different vector databases like Qdrant News, Chroma News, or managed services by simply changing the configuration.
- Simplicity: It provides a clean, high-level API for common vector operations like adding data and performing searches, hiding the complexities of the underlying database-specific clients.
- Integration: It seamlessly integrates with the .NET dependency injection system, making it easy to manage the lifecycle and configuration of your vector store within any ASP.NET Core or modern .NET application.
Setting up the Qdrant provider is straightforward. After installing the necessary NuGet package (Microsoft.Extensions.VectorData.Qdrant), you configure it in your application’s service collection.
// In your Program.cs for a .NET Minimal API
using Microsoft.Extensions.VectorData;
var builder = WebApplication.CreateBuilder(args);
// Add services to the container.
// Retrieve Qdrant configuration from appsettings.json
var qdrantOptions = builder.Configuration.GetSection("Qdrant").Get<QdrantVectorStoreOptions>();
// Add the Qdrant VectorStore to the dependency injection container
builder.Services.AddQdrantVectorStore(qdrantOptions);
var app = builder.Build();
// ... your API endpoints ...
app.Run();
// Example appsettings.json configuration
/*
{
"Qdrant": {
"Endpoint": "http://localhost:6333",
"CollectionName": "dotnet-articles"
}
}
*/
Practical Implementation: Indexing and Searching Data with Qdrant
With the foundational concepts and initial setup covered, let’s move on to the practical aspects of building a vector search-powered application. This involves two main steps: indexing your data into Qdrant and then querying it to find relevant information.
Generating Embeddings and Indexing Documents
The first step is to convert your source data (e.g., text from documents, product descriptions) into vector embeddings. This is typically done by calling an embedding model API. For this example, we’ll assume we have a service, IEmbeddingService, that handles this conversion. Once you have the vector, you package it along with its original text and any relevant metadata into a VectorDataItem and add it to the store.
The metadata is crucial for advanced filtering. For instance, you could store a document’s creation date, author, or category, which you can later use to refine your searches. The following example demonstrates how to index a collection of articles.
public class IndexingService
{
private readonly VectorStore _vectorStore;
private readonly IEmbeddingService _embeddingService; // Assume this service generates embeddings
public IndexingService(VectorStore vectorStore, IEmbeddingService embeddingService)
{
_vectorStore = vectorStore;
_embeddingService = embeddingService;
}
public async Task IndexArticlesAsync(IEnumerable<Article> articles)
{
var vectorDataItems = new List<VectorDataItem>();
foreach (var article in articles)
{
// 1. Generate the embedding for the article content
var embedding = await _embeddingService.GenerateEmbeddingAsync(article.Content);
// 2. Create a metadata dictionary
var metadata = new Dictionary<string, object>
{
{ "title", article.Title },
{ "author", article.Author },
{ "published_date", article.PublishedDate.ToUniversalTime().ToString("o") },
{ "category", article.Category }
};
// 3. Create the VectorDataItem
var vectorDataItem = new VectorDataItem(
embedding,
text: article.Content, // The original text can be stored for retrieval
metadata: metadata
);
vectorDataItems.Add(vectorDataItem);
}
// 4. Add the items to the vector store in a batch
if (vectorDataItems.Any())
{
await _vectorStore.AddAsync(vectorDataItems);
Console.WriteLine($"Successfully indexed {vectorDataItems.Count} articles.");
}
}
}
public record Article(string Title, string Content, string Author, DateTime PublishedDate, string Category);
public interface IEmbeddingService { Task<float[]> GenerateEmbeddingAsync(string text); }
Performing Similarity Searches
Once your data is indexed, you can perform similarity searches. The process mirrors indexing: you take a user’s query, generate an embedding for it using the exact same model, and then use the SearchAsync method of the VectorStore. This method returns a list of the most similar items from your Qdrant collection, along with their similarity scores and stored metadata.
The limit parameter controls how many results to return (often referred to as ‘k’ in vector search terminology), and the minSimilarity parameter allows you to filter out results that are not sufficiently relevant.
public class SearchService
{
private readonly VectorStore _vectorStore;
private readonly IEmbeddingService _embeddingService;
public SearchService(VectorStore vectorStore, IEmbeddingService embeddingService)
{
_vectorStore = vectorStore;
_embeddingService = embeddingService;
}
public async Task<IEnumerable<SearchResult>> FindSimilarArticlesAsync(string query, int limit = 5)
{
// 1. Generate an embedding for the user's query
var queryEmbedding = await _embeddingService.GenerateEmbeddingAsync(query);
// 2. Perform the search against the vector store
var searchResult = await _vectorStore.SearchAsync(queryEmbedding, limit: limit);
// 3. Process and return the results
var results = searchResult.Items.Select(item => new SearchResult(
Content: item.Text,
Similarity: item.Similarity,
Metadata: item.Metadata
));
return results;
}
}
public record SearchResult(string Content, float Similarity, IReadOnlyDictionary<string, object> Metadata);
Advanced Techniques: Leveraging Qdrant’s Power through .NET
While the basic add and search operations cover many use cases, the true power of a vector database like Qdrant lies in its advanced features. These capabilities are essential for building robust, production-grade AI systems.
Metadata Filtering for Efficient Hybrid Search
One of Qdrant’s standout features is its ability to perform pre-filtering. This means you can apply filters on the metadata *before* the vector similarity search is executed. This is significantly more efficient than fetching a large number of vector results and then filtering them in your application code. For example, you could search for articles matching a query but only within a specific category or published after a certain date.
While the `Microsoft.Extensions.VectorData` abstraction is still evolving, for highly complex filtering scenarios that might not be exposed yet, you can always drop down to the native `Qdrant.Client` library. However, for many common cases, you can achieve the desired outcome by retrieving a slightly larger set of results and applying filters in your application logic. The orchestration of this combination of metadata-based filtering and semantic search is often called “hybrid search.” This approach is fundamental to frameworks like LangChain News and LlamaIndex News, which build sophisticated data retrieval pipelines.
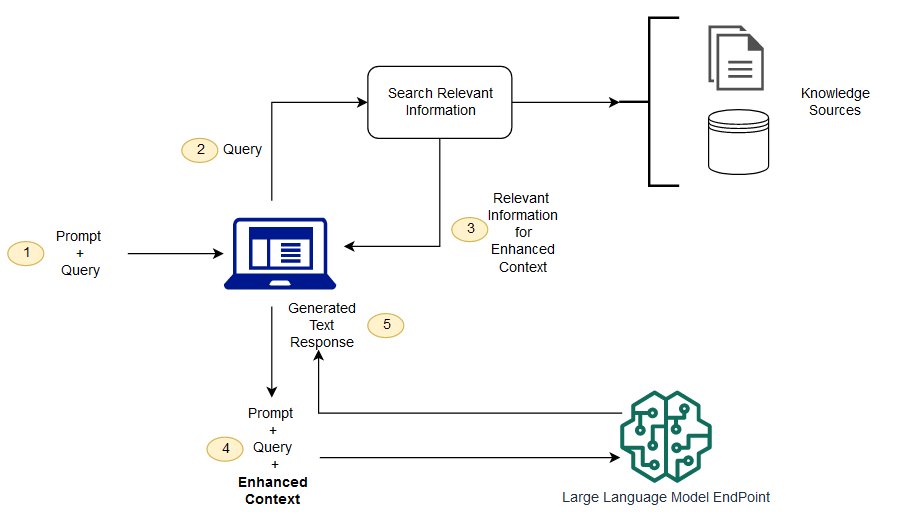
Building a Simple RAG Pipeline
The search functionality we’ve built is the “Retrieval” part of RAG. To complete the pipeline, we need to augment an LLM prompt with the retrieved context. This grounds the model in the specific data you’ve provided, enabling it to answer questions based on your knowledge base.
The workflow is as follows:
- User Query: A user asks a question, e.g., “What are the latest developments in PyTorch?”
- Retrieve Context: Your application uses the
SearchServicefrom the previous example to find the most relevant articles about PyTorch News from your Qdrant database. - Construct Prompt: You create a new, augmented prompt for the LLM. This prompt includes the original user query and the content of the retrieved articles.
Example Prompt:
"Based on the following context, please answer the user's question.Context:
[Content of Article 1]...
[Content of Article 2]...User Question: What are the latest developments in PyTorch?"
.NET logo – Microsoft .NET Logo PNG Vector (AI) Free Download - Generate Response: You send this augmented prompt to an LLM API, such as those from OpenAI News, Anthropic News, or Mistral AI News. The LLM then generates a response that is directly informed by the provided context.
This process ensures the answer is not only relevant but also factually consistent with your indexed data, making it a powerful tool for enterprise applications.
public class RagService
{
private readonly SearchService _searchService;
private readonly ILLMService _llmService; // Assume this service calls an LLM API
public RagService(SearchService searchService, ILLMService llmService)
{
_searchService = searchService;
_llmService = llmService;
}
public async Task<string> GenerateAnswerAsync(string userQuery)
{
// 1. Retrieve relevant context from Qdrant
var searchResults = await _searchService.FindSimilarArticlesAsync(userQuery, limit: 3);
// 2. Combine the content of the search results into a single context string
var context = string.Join("\n\n---\n\n", searchResults.Select(r => r.Content));
// 3. Construct the augmented prompt
var prompt = $"""
Based on the following context, please provide a concise answer to the user's question.
If the context does not contain the answer, state that you don't know.
Context:
{context}
User Question: {userQuery}
""";
// 4. Send the prompt to the LLM and get the final answer
var answer = await _llmService.GenerateResponseAsync(prompt);
return answer;
}
}
public interface ILLMService { Task<string> GenerateResponseAsync(string prompt); }
Best Practices and Optimization
To move from a proof-of-concept to a production-ready system, consider these best practices and optimization strategies.
- Data Preparation and Chunking: LLMs and embedding models have context window limitations. Large documents should be split into smaller, semantically coherent chunks before being embedded. A common strategy is to chunk by paragraph or create overlapping chunks to ensure no context is lost at the boundaries.
- Choose the Right Embedding Model: The model used for indexing must be the same one used for querying. Consider the trade-offs: larger models may offer better semantic understanding but come with higher latency and cost. Open-source models from sources like Sentence Transformers News can be a cost-effective alternative to API-based ones. Tracking model performance and experiments can be managed with tools like MLflow News or Weights & Biases News.
- Qdrant Configuration: On the Qdrant server side, you can fine-tune performance significantly. Explore features like Scalar Quantization, which reduces the memory footprint of vectors and can speed up searches at the cost of a minor precision loss. You can also adjust the HNSW graph parameters for your collection to balance search speed and accuracy.
- Scalability and Monitoring: Qdrant is designed to scale horizontally. As your data grows, you can add more nodes to your cluster. Monitor key metrics like query latency, indexing speed, and resource utilization to ensure your system remains performant.
- Asynchronous Operations: Always use the asynchronous methods (e.g.,
AddAsync,SearchAsync) provided by the library to ensure your .NET application remains responsive and can handle concurrent requests efficiently, especially in web applications built with ASP.NET Core.
Conclusion
The integration of powerful vector databases like Qdrant into the .NET ecosystem via the Microsoft.Extensions.VectorData library marks a significant milestone. It empowers .NET developers to build sophisticated, next-generation AI applications with greater ease and flexibility than ever before. By abstracting the underlying data store, developers can focus on building core application logic while retaining the freedom to choose the best vector database for their specific needs.
We’ve walked through the entire process, from understanding the core concepts of vector embeddings to implementing a practical RAG pipeline. You are now equipped with the knowledge to index your data, perform efficient similarity searches, and leverage these capabilities to create intelligent, context-aware applications. The worlds of enterprise development with .NET and cutting-edge AI are converging, and now is the perfect time to start building.


