
Unlocking 3x Throughput: A Deep Dive into TensorRT-LLM’s Multiblock Attention for Long-Sequence Inference
The proliferation of Large Language Models (LLMs) has revolutionized countless industries, but their deployment in production environments presents significant technical hurdles. One of the most pressing challenges is efficiently handling long sequence lengths, a critical requirement for applications like advanced Retrieval-Augmented Generation (RAG), document summarization, and complex reasoning tasks. As context windows expand, the computational and memory demands of the underlying self-attention mechanism grow quadratically, creating a severe bottleneck for inference throughput. This is where the latest advancements in optimization libraries become crucial. The latest TensorRT News highlights a groundbreaking technique designed to shatter this barrier.
NVIDIA’s TensorRT-LLM, a specialized library for accelerating LLM inference, has introduced a powerful feature known as Multiblock Attention. This innovative approach re-architects how memory is managed during the attention calculation, leading to dramatic performance gains. By intelligently breaking down the massive Key-Value (KV) cache into manageable blocks, it enables significantly higher throughput—in some cases more than tripling it—for models processing extremely long sequences. This article provides a comprehensive technical exploration of Multiblock Attention, from the foundational challenges it solves to practical implementation details and best practices for maximizing its impact. We will delve into the code, concepts, and the broader implications for the AI ecosystem, touching upon trends from PyTorch News to the evolving landscape of MLOps tools like MLflow News.
The Quadratic Challenge of Self-Attention
To fully appreciate the innovation of Multiblock Attention, we must first understand the fundamental problem it solves. The power of the Transformer architecture, popularized by models from OpenAI News and Mistral AI News, lies in its self-attention mechanism, but this power comes at a steep computational cost.
The Standard Attention Mechanism Explained
At its core, self-attention allows a model to weigh the importance of different tokens in an input sequence when producing a representation for a specific token. This is achieved by computing three vectors for each token: Query (Q), Key (K), and Value (V). The attention score is calculated using the formula:
Attention(Q, K, V) = softmax( (Q * K^T) / sqrt(d_k) ) * V
The critical bottleneck here is the matrix multiplication Q * K^T. If the sequence length is ‘n’, both Q and K are matrices of shape `[n, d_k]`, where `d_k` is the dimension of the head. The resulting attention score matrix has a shape of `[n, n]`. This means both the computational complexity and the memory required for this intermediate matrix scale quadratically with the sequence length, denoted as O(n²). For a sequence of 32,000 tokens, this intermediate matrix can become astronomically large, consuming precious GPU High-Bandwidth Memory (HBM).
The KV Cache: A Double-Edged Sword
During autoregressive inference (generating text token by token), performance is optimized by caching the Key and Value vectors of previously processed tokens. This is known as the KV cache. Without it, the model would have to recompute the K and V states for the entire sequence at every single generation step, which is prohibitively slow. The KV cache avoids this redundant work.
However, the KV cache itself becomes a memory monster. For a model with a long context window, the cache must store the K and V tensors for every token in that window. This memory consumption can easily run into tens of gigabytes, severely limiting the number of concurrent requests (batch size) a GPU can handle. Let’s quantify this with a practical example.

import torch
def calculate_kv_cache_size(batch_size, seq_len, num_layers, num_heads, head_dim, dtype=torch.float16):
"""
Calculates the memory footprint of the KV cache for a given LLM configuration.
Args:
batch_size (int): The number of sequences in the batch.
seq_len (int): The length of the sequence.
num_layers (int): The number of transformer layers in the model.
num_heads (int): The number of attention heads.
head_dim (int): The dimension of each attention head.
dtype (torch.dtype): The data type (e.g., float16, int8).
Returns:
float: The total size of the KV cache in gigabytes (GB).
"""
if dtype == torch.float16:
bytes_per_element = 2
elif dtype == torch.int8:
bytes_per_element = 1
else: # float32
bytes_per_element = 4
# Calculate size for one tensor (Key or Value)
# Shape: [batch_size, num_heads, seq_len, head_dim]
# For all layers, we multiply by num_layers
# For both K and V, we multiply by 2
total_elements = batch_size * seq_len * num_layers * num_heads * head_dim * 2
total_bytes = total_elements * bytes_per_element
# Convert bytes to gigabytes
gb_size = total_bytes / (1024 ** 3)
return gb_size
# --- Example Usage for a Llama-2 7B-like model ---
config = {
"batch_size": 8,
"seq_len": 32768, # A long context window
"num_layers": 32,
"num_heads": 32,
"head_dim": 128,
"dtype": torch.float16
}
kv_cache_gb = calculate_kv_cache_size(**config)
print(f"Model Configuration:")
print(f" - Batch Size: {config['batch_size']}")
print(f" - Sequence Length: {config['seq_len']}")
print(f" - Data Type: {config['dtype']}")
print(f"Estimated KV Cache Size: {kv_cache_gb:.2f} GB")
# For a single sequence, it's still substantial
kv_cache_single_gb = calculate_kv_cache_size(batch_size=1, **config)
print(f"\nEstimated KV Cache Size for a single sequence: {kv_cache_single_gb:.2f} GB")
As the output of this code shows, even for a modest batch size, the KV cache for a 32k context window can consume over 60 GB of HBM, exceeding the capacity of many powerful GPUs. This forces practitioners to use a batch size of 1, crippling throughput and making the deployment economically unviable. This is the exact problem that the latest NVIDIA AI News aims to solve.
Introducing Multiblock Attention: A Paradigm Shift in Memory Management
Multiblock Attention, also known as PagedAttention in other contexts like the popular vLLM News, fundamentally changes how the KV cache is stored and accessed. It draws inspiration from virtual memory and paging concepts in modern operating systems to overcome the limitations of a contiguous memory layout.
Core Concept: Breaking Down the KV Cache
Instead of allocating a single, massive, contiguous block of memory for the entire KV cache of a sequence, Multiblock Attention divides the cache into smaller, fixed-size blocks. Each block can store a small segment of the sequence’s Key and Value tensors. These blocks are allocated dynamically from a global pool as the sequence is processed.
This approach has several key advantages:
- Elimination of Internal Fragmentation: In the traditional approach, memory is pre-allocated for the maximum possible sequence length. If a sequence is shorter, the unused portion is wasted. With blocks, memory is allocated only as needed, leading to near-zero waste.
- Flexible Memory Management: The blocks for a single sequence do not need to be contiguous in memory. This allows the system to manage memory much more efficiently, similar to how an OS manages RAM pages.
- Enabling Advanced Scheduling: Because sequences share a common pool of memory blocks, it becomes easier to implement sophisticated scheduling algorithms, pause and resume generation, and even share memory blocks between different sequences that have a common prefix (e.g., in beam search or parallel sampling).
How It Works During Inference
During the generation process, the attention mechanism is modified to work with this blocked memory layout. When computing attention for a new token, its Query vector must attend to all the past Key and Value vectors stored across multiple blocks.
The computation kernel iterates through the list of blocks associated with the sequence. For each block, it loads the K and V data, computes the partial attention scores, and updates the running softmax normalization constants. This block-wise computation avoids materializing the giant `[n, n]` attention matrix, instead computing the final output in a streaming fashion. This is a critical optimization that works hand-in-hand with the memory management scheme.
import numpy as np
# --- Conceptual Example of Block-wise Attention ---
# This is a simplified illustration of the logic, not a real implementation.
def conceptual_multiblock_attention(query_vector, key_blocks, value_blocks):
"""
Illustrates the logic of computing attention over non-contiguous blocks.
Args:
query_vector (np.array): The Query vector for the current token.
key_blocks (list of np.array): A list of blocks containing past Key vectors.
value_blocks (list of np.array): A list of blocks containing past Value vectors.
Returns:
np.array: The final context vector.
"""
# These would be computed in a streaming fashion on the GPU
attention_scores = []
print(f"Processing query against {len(key_blocks)} blocks...")
# Step 1: Compute dot products for all blocks
for i, k_block in enumerate(key_blocks):
# In reality, this happens in a single CUDA kernel
print(f" - Computing scores for block {i+1}")
scores = np.dot(query_vector, k_block.T)
attention_scores.append(scores)
# Concatenate scores from all blocks
all_scores = np.concatenate(attention_scores)
# Step 2: Apply softmax over all concatenated scores
# This is the tricky part in a real implementation, often done with
# online softmax to maintain numerical stability.
max_score = np.max(all_scores)
exp_scores = np.exp(all_scores - max_score)
softmax_probs = exp_scores / np.sum(exp_scores)
# Step 3: Compute weighted sum of Value vectors
# This also happens block-by-block.
output_vector = np.zeros_like(value_blocks[0][0])
current_pos = 0
for i, v_block in enumerate(value_blocks):
block_len = v_block.shape[0]
# Get the corresponding probabilities for this block
block_probs = softmax_probs[current_pos : current_pos + block_len]
# Compute weighted sum for this block and add to total
# Reshape probs for broadcasting: (block_len,) -> (1, block_len)
output_vector += np.dot(block_probs.reshape(1, -1), v_block)
current_pos += block_len
return output_vector.flatten()
# --- Setup a dummy scenario ---
head_dim = 64
block_size = 16 # Each block holds 16 tokens
num_blocks = 4
# A single query vector for the new token
q_vec = np.random.randn(head_dim)
# Create some dummy key and value blocks
k_blocks = [np.random.randn(block_size, head_dim) for _ in range(num_blocks)]
v_blocks = [np.random.randn(block_size, head_dim) for _ in range(num_blocks)]
# Run the conceptual function
final_context = conceptual_multiblock_attention(q_vec, k_blocks, v_blocks)
print(f"\nFinal context vector shape: {final_context.shape}")
Building and Deploying Models with Multiblock Attention
Moving from theory to practice, TensorRT-LLM provides a streamlined workflow for compiling and deploying models with this advanced feature. The process involves converting a standard model from a source like the Hugging Face Hub into a highly optimized TensorRT engine.
Compiling a Model with TensorRT-LLM

The primary tool for this is the `trtllm-build` command-line utility. This tool takes a model checkpoint (either in its original format or a converted format) and applies a suite of optimizations, including operator fusion, kernel auto-tuning, and quantization. To enable Multiblock Attention, you simply need to add a specific flag.
The key flag is --use_paged_kv_cache. When this is enabled, TensorRT-LLM builds the attention kernels to work with the blocked memory layout. You must also specify the maximum batch size and sequence lengths the engine should support. This information is crucial for the underlying memory manager in the Triton Inference Server to pre-allocate the block pool.
# Example command to build a Mistral-7B model with Multiblock Attention (Paged KV Cache)
# This assumes you have already converted the Hugging Face model to the TensorRT-LLM checkpoint format.
CHECKPOINT_DIR="./tllm_checkpoint_mistral_7b"
ENGINE_DIR="./engine_mistral_7b"
GEMM_PLUGIN="float16" # Use float16 for GEMM operations
# The crucial flags are --use_paged_kv_cache and the max_* flags
trtllm-build --checkpoint_dir ${CHECKPOINT_DIR} \
--output_dir ${ENGINE_DIR} \
--gemm_plugin ${GEMM_PLUGIN} \
--use_paged_kv_cache \
--max_batch_size 64 \
--max_input_len 32000 \
--max_output_len 2048 \
--max_beam_width 1
echo "TensorRT-LLM engine built successfully in ${ENGINE_DIR}"
Serving the Optimized Engine with Triton
Once the engine is built, the next step is to serve it for live inference. NVIDIA’s Triton Inference Server is the ideal platform for this, especially with its `tensorrtllm_backend`. This backend is specifically designed to work with TensorRT-LLM engines and manage their unique requirements, including the paged KV cache memory pool.
After deploying the model to Triton, clients can send requests as they normally would. The backend handles the complex orchestration of batching requests, dynamically allocating memory blocks, and scheduling execution on the GPU to maximize utilization. This seamless integration is a major advantage, abstracting away the complexity from the end-user. A developer using a tool like LangChain or LlamaIndex can simply point to the Triton endpoint without needing to know about the underlying memory optimizations.
import tritonclient.http as httpclient
import numpy as np
# --- Example Python client to query a Triton server running a TensorRT-LLM model ---
def send_request_to_triton(prompt_text):
"""
Sends a generation request to a Triton Inference Server.
"""
TRITON_URL = "localhost:8000"
MODEL_NAME = "tensorrt_llm" # The name of the model in Triton's model repository
try:
triton_client = httpclient.InferenceServerClient(url=TRITON_URL)
except Exception as e:
print("Could not create Triton client: " + str(e))
return
# Input tensors
# The prompt is encoded as a numpy array of token IDs.
# Here we use a placeholder. In a real app, you'd use a tokenizer.
input_ids = np.array([list(prompt_text.encode('utf-8'))], dtype=np.uint32)
input_lengths = np.array([[len(prompt_text)]], dtype=np.uint32)
# Other required inputs for TensorRT-LLM backend
request_output_len = np.array([[100]], dtype=np.uint32) # Max new tokens to generate
inputs = [
httpclient.InferInput("input_ids", input_ids.shape, "UINT32"),
httpclient.InferInput("input_lengths", input_lengths.shape, "UINT32"),
httpclient.InferInput("request_output_len", request_output_len.shape, "UINT32"),
]
inputs[0].set_data_from_numpy(input_ids)
inputs[1].set_data_from_numpy(input_lengths)
inputs[2].set_data_from_numpy(request_output_len)
# Output tensor
outputs = [
httpclient.InferRequestedOutput("output_ids")
]
print(f"Sending request for prompt: '{prompt_text}'")
# Send request
results = triton_client.infer(
model_name=MODEL_NAME,
inputs=inputs,
outputs=outputs
)
# Process response
output_ids = results.as_numpy("output_ids")
# In a real app, you would decode these IDs back to text.
print("Received response from Triton server.")
print("Output IDs shape:", output_ids.shape)
return output_ids
# --- Example Usage ---
if __name__ == "__main__":
prompt = "Explain the benefits of Multiblock Attention in TensorRT-LLM"
send_request_to_triton(prompt)
Maximizing Throughput and Efficiency
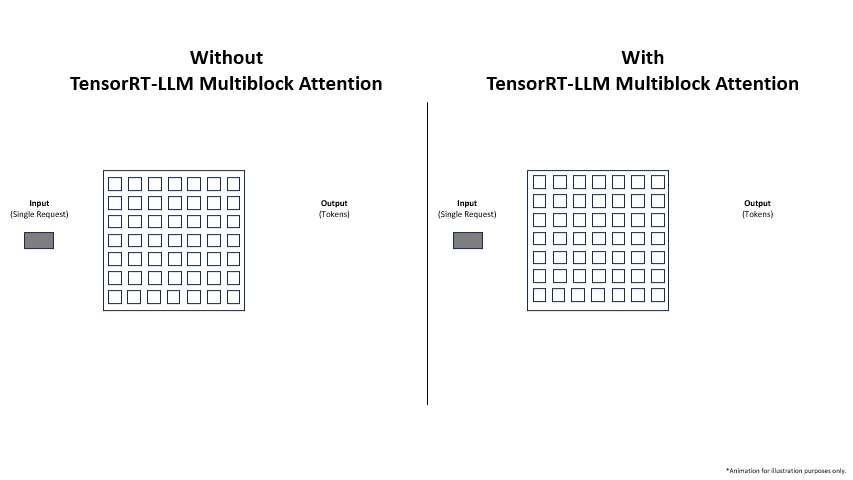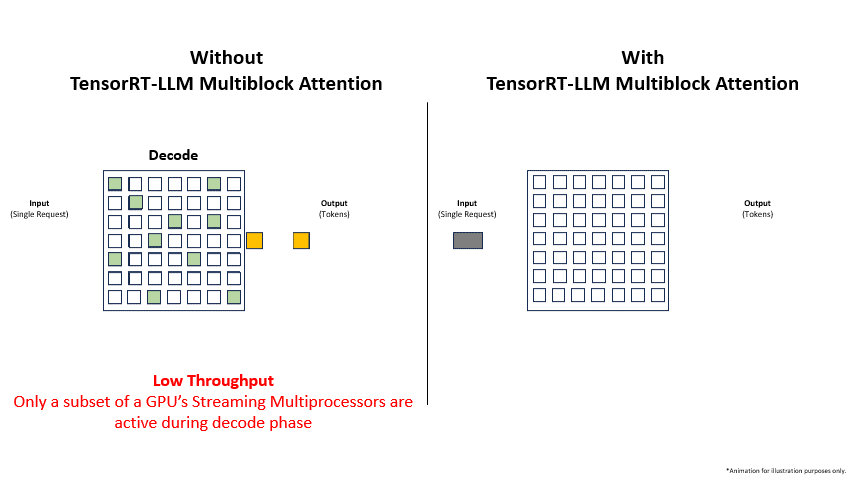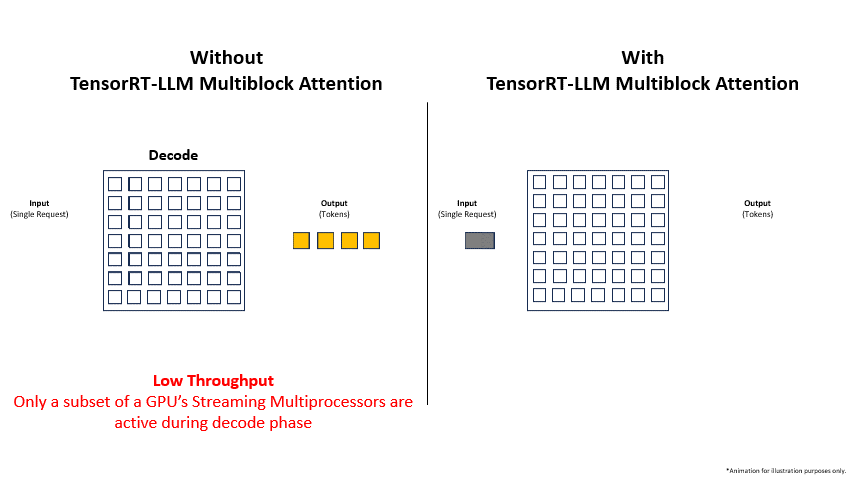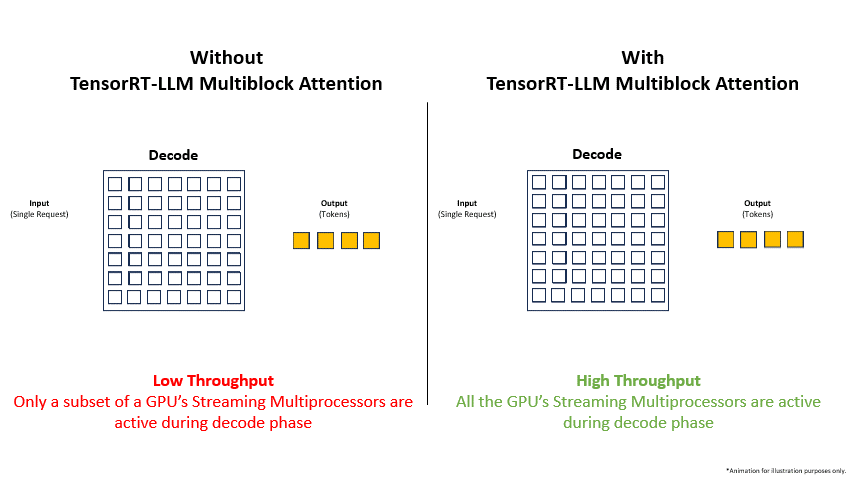
Adopting Multiblock Attention is not just about enabling long contexts; it’s about fundamentally improving the efficiency and economics of LLM deployment. The latest Google DeepMind News and Meta AI News show a clear trend towards models with larger context windows, making these optimizations more critical than ever.
Key Performance Benefits
- Drastically Increased Throughput: By nearly eliminating memory waste, the system can fit significantly more concurrent sequences onto the GPU. This directly translates to a higher number of requests processed per second, which is the primary source of the reported 3x (or more) throughput improvement.
- True Long-Context Inference: Models can now be deployed with their full context windows (e.g., 32k, 128k, or even more) without immediately running out of memory. This unlocks new capabilities for applications built on frameworks like Haystack that rely on processing large documents.
- Improved GPU Utilization: Continuous batching and efficient memory management keep the GPU’s computational units busy, reducing idle time and maximizing the return on investment for expensive hardware like NVIDIA’s H100 and H200 systems.
Best Practices and Considerations
To get the most out of this technology, consider the following best practices:
- Combine with Quantization: For maximum performance, use Multiblock Attention in conjunction with quantization techniques like INT8 or FP8. This reduces the memory footprint of both the model weights and the KV cache, compounding the benefits.
- Hardware Matters: The benefits are most pronounced on GPUs with large amounts of HBM. The efficient memory management allows you to fully leverage the capacity of top-tier hardware.
- Monitor Performance: Use MLOps platforms like Weights & Biases or Comet ML News to track key metrics like throughput, latency, and GPU memory utilization. This allows you to quantify the improvements and fine-tune your deployment configuration.
- Tune Batching Strategy: The Triton backend offers sophisticated batching and scheduling strategies. Experiment with parameters like `max_queue_delay` to find the optimal balance between latency and throughput for your specific workload.
import pynvml
def check_gpu_memory_before_batching():
"""
A simple utility to check available GPU memory, a common practice
before launching a large batch processing job.
"""
pynvml.nvmlInit()
# Assuming a single GPU system for simplicity
handle = pynvml.nvmlDeviceGetHandleByIndex(0)
info = pynvml.nvmlDeviceGetMemoryInfo(handle)
total_memory_gb = info.total / (1024**3)
free_memory_gb = info.free / (1024**3)
used_memory_gb = info.used / (1024**3)
print(f"--- GPU Memory Status ---")
print(f"Total: {total_memory_gb:.2f} GB")
print(f"Used: {used_memory_gb:.2f} GB")
print(f"Free: {free_memory_gb:.2f} GB")
# A simple heuristic for a production system
# This logic would be inside the inference server's scheduler
if free_memory_gb < 10: # Threshold in GB
print("\nWARNING: Low available GPU memory. Consider reducing batch size.")
else:
print("\nSufficient GPU memory available for new batches.")
pynvml.nvmlShutdown()
# --- Example Usage ---
if __name__ == "__main__":
check_gpu_memory_before_batching()
Conclusion
The introduction of Multiblock Attention in TensorRT-LLM represents a significant leap forward in solving the LLM inference bottleneck. By fundamentally rethinking memory management for the KV cache, it directly tackles the quadratic complexity problem that has long hindered the efficient deployment of models with large context windows. This is not an incremental improvement; it is a transformative technology that unlocks new levels of throughput and enables applications that were previously impractical due to memory constraints.
For developers and MLOps engineers working in the AI space, from those using Azure AI News platforms to those building on AWS SageMaker, this development is a call to action. By leveraging TensorRT-LLM and Triton Inference Server, you can dramatically improve the performance and cost-efficiency of your LLM services. The key takeaways are clear: memory is the new frontier of LLM optimization


