
Unlocking the 1 Million Token Horizon: A Deep Dive into Large Context Windows on Amazon Bedrock
Introduction
The landscape of artificial intelligence is undergoing a seismic shift, driven by the exponential growth of Large Language Model (LLM) capabilities. One of the most significant recent advancements is the dramatic expansion of context windows, with some models now supporting up to one million tokens. This isn’t just an incremental improvement; it’s a paradigm shift that redefines what’s possible with generative AI. A million-token context window is equivalent to processing an entire 700-page book or a substantial codebase in a single prompt. This breakthrough, now accessible through managed services like Amazon Bedrock, is unlocking a new frontier of applications, from hyper-detailed document analysis to complex, context-aware code generation.
This article provides a comprehensive technical guide to understanding and leveraging these massive context windows on Amazon Bedrock. We will explore the core concepts, dive into practical implementation details using Python and `boto3`, showcase advanced techniques, and discuss the critical best practices for optimizing performance and cost. Whether you’re a seasoned ML engineer or a developer just starting with generative AI, this guide will equip you with the knowledge to harness the power of million-token models. This development is a key part of the ongoing Amazon Bedrock News, reflecting the platform’s commitment to providing access to state-of-the-art models from leading providers, a trend also seen in the latest Anthropic News and Vertex AI News.
Section 1: The Paradigm Shift: What is a 1M Token Context Window?
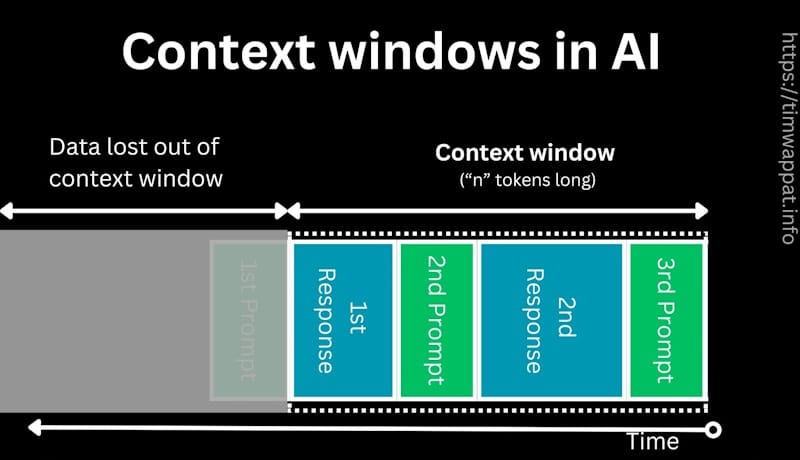
To fully grasp the magnitude of this development, it’s essential to understand the fundamentals. An LLM’s “context window” is the amount of text (the prompt and any previous conversation) the model can consider when generating a response. This text is broken down into “tokens,” which are fragments of words. For example, the word “transformer” might be broken into “transform” and “er”. A one-million-token context window allows the model to “remember” and reason over an immense volume of information simultaneously.
From Short-Term Memory to Encyclopedic Recall
Previously, models with smaller context windows (e.g., 4k to 32k tokens) operated like a human with limited short-term memory. They could handle a few pages of a document but would quickly “forget” the beginning of a long text. This necessitated complex engineering workarounds like Retrieval-Augmented Generation (RAG), where relevant document chunks are dynamically retrieved and fed to the model. While RAG is still incredibly powerful, a massive context window offers a complementary approach: simply providing the entire corpus of information at once. This is particularly useful for tasks requiring holistic understanding, cross-document synthesis, or analysis of intricate, long-form dependencies often found in legal contracts or large code repositories.
A Basic Invocation with Boto3
Interacting with these models on Amazon Bedrock is primarily done through the AWS SDK. The following Python example demonstrates a fundamental interaction with an Anthropic Claude model using `boto3`, the AWS SDK for Python. This foundational code is the starting point for all more complex applications.
import boto3
import json
# Initialize the Bedrock Runtime client
# Ensure your AWS credentials are configured (e.g., via environment variables)
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1' # Or any region where the model is available
)
def invoke_claude_model(prompt_text):
"""
Invokes an Anthropic Claude model on Amazon Bedrock.
"""
model_id = 'anthropic.claude-3-5-sonnet-20240620-v1:0' # Example model ID
# Construct the request body according to the model's API
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": prompt_text}]
}
]
})
try:
response = bedrock_runtime.invoke_model(
body=body,
modelId=model_id,
accept='application/json',
contentType='application/json'
)
response_body = json.loads(response.get('body').read())
# Extract the generated text from the response
generated_text = response_body['content'][0]['text']
return generated_text
except Exception as e:
print(f"Error invoking model: {e}")
return None
# Example usage
prompt = "Explain the concept of a transformer architecture in neural networks in a few paragraphs."
response_text = invoke_claude_model(prompt)
if response_text:
print("Model Response:")
print(response_text)This simple script establishes a connection, formats a request, and parses the response. The key is the `prompt_text` variable—with a 1M token model, this string can now contain the equivalent of a novel.

Section 2: Practical Implementation: Large-Scale Document Analysis
The true power of a large context window is realized when dealing with substantial amounts of data. A common and high-value use case is performing question-answering (Q&A) over a very large document, such as a comprehensive financial report, a legal deposition, or a lengthy technical manual. This moves beyond simple keyword searching into genuine comprehension and synthesis of information across the entire document.
From Theory to Practice: Q&A on a Massive Text
Imagine you have a 200-page PDF of a company’s annual report. Your goal is to ask nuanced questions that require understanding context from different sections. Instead of building a complex RAG pipeline with a vector database like Pinecone or Milvus, you can now feed the entire document’s text directly to the model.
The following example demonstrates how to read a large text file and use it within a prompt to ask a specific question. This approach is powerful for tasks where the answer depends on the interplay of information scattered throughout the document.
import boto3
import json
import os
# Assume bedrock_runtime client is initialized as in the previous example
bedrock_runtime = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
def query_large_document(document_path, question):
"""
Reads a large text file and asks a question about it using a large context model.
"""
try:
with open(document_path, 'r', encoding='utf-8') as f:
document_content = f.read()
except FileNotFoundError:
print(f"Error: The file '{document_path}' was not found.")
return None
except Exception as e:
print(f"Error reading file: {e}")
return None
# Construct a prompt that includes the full document context
prompt = f"""
Here is a complete document:
{document_content}
Based on the information contained ONLY in the document provided above, please answer the following question: {question}
Provide a concise answer and cite the key sentences or data points from the document that support your answer.
"""
model_id = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": prompt}]
}
]
})
try:
print("Invoking model with large context... this may take some time.")
response = bedrock_runtime.invoke_model(
body=body,
modelId=model_id
)
response_body = json.loads(response.get('body').read())
answer = response_body['content'][0]['text']
return answer
except Exception as e:
print(f"Error during model invocation: {e}")
return None
# --- Example Usage ---
# Create a dummy large text file for demonstration
large_text = "This is a sample text. " * 50000 # Approx. 250k tokens
large_text += "\nThe critical finding of the 2023 report is that Project Nebula's efficiency increased by 15% due to the new integration of the FooBar system. "
large_text += "More sample text. " * 50000
# Create a file named 'large_report.txt'
with open('large_report.txt', 'w') as f:
f.write(large_text)
# Now, query the document
question_to_ask = "What was the efficiency gain for Project Nebula in 2023 and what caused it?"
result = query_large_document('large_report.txt', question_to_ask)
if result:
print("\n--- Model's Answer ---")
print(result)
# Clean up the dummy file
os.remove('large_report.txt')
This example highlights a key prompt engineering technique: wrapping the large context in XML-like tags (e.g., `
Section 3: Advanced Techniques: The “Needle in a Haystack” Test
While impressive, simply processing a large document is just the beginning. The real test of a large context window model is its ability to recall specific, minute details from any part of that context. This is often evaluated using the “Needle in a Haystack” test, a methodology designed to measure a model’s retrieval accuracy across its entire context length.
Finding a Single Fact in a Sea of Data
The test works by embedding a specific, unique sentence (the “needle”) into a massive, irrelevant body of text (the “haystack”). The model is then prompted to find and report on that specific sentence. A successful result demonstrates that the model isn’t just getting a vague “gist” of the text but is actively processing and retaining information from all parts of the context window.
This capability has profound real-world applications. For a legal team, it could mean finding a single critical clause in hundreds of pages of discovery documents. For a developer, it could be identifying a specific deprecated function call within an entire monolithic codebase. The following code implements a version of this test.
import boto3
import json
import random
# Assume bedrock_runtime client is initialized
bedrock_runtime = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
def run_needle_in_haystack_test(haystack_size_tokens, needle_position_percent):
"""
Performs a Needle in a Haystack test on a Bedrock model.
:param haystack_size_tokens: The approximate number of tokens for the haystack.
:param needle_position_percent: Where to place the needle (0-100).
"""
# The "needle" - a unique, specific fact.
needle = "The special magic word to activate the system is 'Klaatu Barada Nikto'."
# The "haystack" - irrelevant text. We'll use a simple repeated sentence.
# A single sentence "The quick brown fox jumps over the lazy dog." is ~10 tokens.
haystack_sentence = "The quick brown fox jumps over the lazy dog. "
num_sentences = haystack_size_tokens // 10
haystack_list = [haystack_sentence] * num_sentences
# Insert the needle at the specified position
insertion_index = int(num_sentences * (needle_position_percent / 100))
haystack_list.insert(insertion_index, f"\n{needle}\n")
haystack_text = "".join(haystack_list)
# The question that requires finding the needle
question = "What is the special magic word to activate the system?"
prompt = f"""
I will provide you with a large body of text. Buried somewhere within this text is a single sentence that contains a 'magic word'.
Your task is to find that exact sentence and tell me what the magic word is. Do not summarize or add any extra information.
Here is the text:
{haystack_text}
Question: {question}
"""
print(f"Running test with haystack of ~{haystack_size_tokens} tokens.")
print(f"Needle inserted at {needle_position_percent}% of the context.")
model_id = 'anthropic.claude-3-5-sonnet-20240620-v1:0'
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 200,
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": prompt}]
}
]
})
try:
response = bedrock_runtime.invoke_model(body=body, modelId=model_id)
response_body = json.loads(response.get('body').read())
answer = response_body['content'][0]['text']
print("\n--- Model's Answer ---")
print(answer)
# Check for success
if "Klaatu Barada Nikto" in answer:
print("\nSUCCESS: The model found the needle!")
else:
print("\nFAILURE: The model did not find the needle.")
except Exception as e:
print(f"An error occurred: {e}")
# --- Example Usage ---
# Run a test with a ~500k token context, placing the needle 75% of the way through.
run_needle_in_haystack_test(haystack_size_tokens=500000, needle_position_percent=75)
Running experiments like this is crucial for building trust in these models. For production systems, you might use MLOps platforms like MLflow or Weights & Biases to systematically run these tests across different context sizes and needle positions, generating performance heatmaps to understand a model’s retrieval capabilities and limitations.
Section 4: Best Practices, Pitfalls, and Optimization
While incredibly powerful, leveraging million-token context windows requires careful consideration of several factors to be effective and efficient. Simply throwing data at the model is not an optimal strategy. The latest OpenAI News and Google DeepMind News confirm that even with advanced models, thoughtful implementation is key.
Cost and Latency: The Two Elephants in the Room
The most significant considerations are cost and latency.
- Cost: LLM pricing is based on tokens—both input and output. Sending a 900,000-token prompt is substantially more expensive than sending a 4,000-token one. It’s crucial to use large contexts only when the task genuinely requires it. For simpler Q&A, a traditional RAG approach with a smaller context model might be far more cost-effective.
- Latency: Processing a million tokens takes time. While models are becoming faster, users can still expect a noticeable delay for the first token to be generated. For interactive applications like chatbots, this can be a deal-breaker. Employing streaming responses, where the model’s output is sent back token-by-token as it’s generated, is essential for maintaining a good user experience.
The “Lost in the Middle” Problem

Research has shown that some LLMs exhibit a “U-shaped” performance curve, where they recall information from the beginning and end of a long context more reliably than from the middle. This is known as the “lost in the middle” problem. To mitigate this:
- Instruction Placement: Always place your most important instructions and questions at the very beginning or very end of the prompt.
- Document Reordering: If you have control over the input document, consider placing the most critical sections or a summary at the start or end to improve the model’s focus.
Choosing the Right Tool for the Job
A 1M token context window is not a silver bullet. It’s a powerful new tool in the developer’s arsenal. The decision to use it should be deliberate:
- Use Large Context When: The task requires a holistic understanding of an entire, large document; when relationships between disparate parts of the text are crucial; or for comprehensive code analysis and refactoring.
- Use RAG When: You have a massive, multi-document knowledge base; when cost and latency are primary concerns; and when the user’s query can be satisfied with a few specific chunks of information.
Often, a hybrid approach is best. For instance, you could use a traditional RAG system to identify the top 5-10 most relevant documents and then feed all of them into a large context window model for a final, synthesized answer. This combines the scalability of RAG with the deep reasoning of large context models. This is a hot topic in LangChain News, with new agents and chains being developed to manage these hybrid strategies.
Conclusion
The arrival of million-token context windows on platforms like Amazon Bedrock represents a monumental leap forward for generative AI. It fundamentally changes the scale of problems we can solve, moving from paragraph-level analysis to book-level comprehension in a single API call. We’ve explored the core concepts, demonstrated practical implementations for document analysis, and validated model capabilities with the “Needle in a Haystack” test. We also covered the critical best practices regarding cost, latency, and prompt engineering that are essential for successful real-world deployment.
The journey doesn’t end here. As models from providers like Anthropic, Cohere, and others continue to evolve, we can expect even larger context windows, lower latency, and reduced costs. The next step for developers and engineers is to begin experimenting. Start with your own documents and codebases, measure performance, and identify the unique use cases within your domain that can now be unlocked. By combining this powerful technology with thoughtful engineering and a clear understanding of its trade-offs, you can build the next generation of intelligent applications that were once the stuff of science fiction.


