
The Developer’s Guide to Securing Ollama: From Localhost to Production
The world of local Large Language Models (LLMs) has been revolutionized by tools that simplify setup and experimentation. Among these, Ollama has emerged as a clear favorite for developers and researchers, offering a streamlined way to run powerful open-source models like Llama 3, Mistral, and Phi-3 directly on personal hardware. Its simplicity is its greatest strength—a single command can download a model and expose a local API server for immediate use. However, this same simplicity can become a significant security liability if not managed correctly. As the latest Ollama News highlights its growing adoption, it’s crucial to address a common pitfall: the unintentional exposure of Ollama instances to the public internet.
This article provides a comprehensive technical guide for developers on securing their Ollama instances. We will explore the default security posture, detail the severe risks of a publicly exposed server, and provide practical, step-by-step instructions and code examples for hardening your setup. Whether you’re a hobbyist building a project with LangChain, a researcher fine-tuning a model, or a startup prototyping a new AI feature, these best practices will help you leverage the power of local LLMs safely and responsibly. This is essential in an ecosystem where developments in PyTorch News and Hugging Face News are constantly pushing the boundaries of what’s possible on local machines.
Understanding Ollama’s Architecture and Default Security
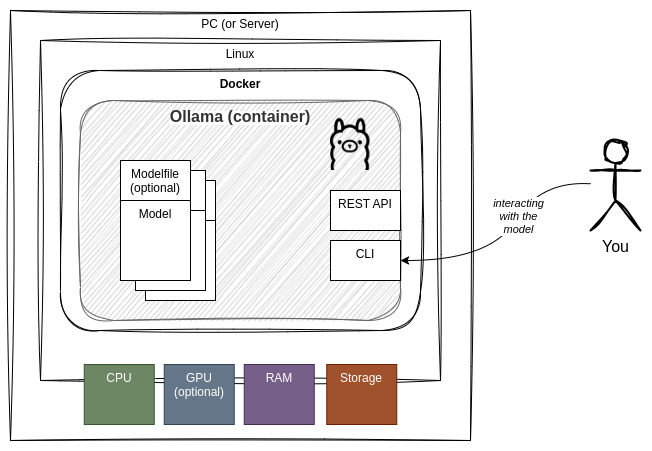
To secure a system effectively, you must first understand how it works. Ollama’s architecture is a classic client-server model, which is key to its flexibility but also the source of potential security issues if misconfigured.
How Ollama Works: A Client-Server Model
When you run an Ollama command like ollama run llama3, you are interacting with the Ollama client. This client communicates with a background server process (a daemon) that is responsible for managing models and handling inference requests. This server exposes a REST API, which is the core of Ollama’s functionality. By default, this server starts automatically and listens for HTTP requests on port 11434.
This API-first approach is incredibly powerful. It allows various applications and frameworks, from simple Python scripts to complex applications built with FastAPI or integrated with LlamaIndex, to interact with the LLM. The server handles the heavy lifting of loading models into memory (often leveraging GPU acceleration, a hot topic in NVIDIA AI News) and processing inference requests.
The Default Security Posture: Safe by Default, Risky if Changed
Out of the box, the Ollama server is configured securely. It binds to 127.0.0.1, also known as localhost. This means the API is only accessible to applications running on the same machine. You can safely run Ollama and a Python script on your laptop, and they can communicate without exposing the LLM to your local network or the internet.
The problem arises when developers need to access their Ollama instance from another device. A common scenario is testing a mobile application that needs to communicate with an LLM running on a desktop. To achieve this, a developer might set the OLLAMA_HOST environment variable to 0.0.0.0. While this makes the server accessible across the local network, binding to 0.0.0.0 tells the operating system to listen on all available network interfaces. If the machine has a public IP address and lacks a properly configured firewall, the Ollama API instantly becomes exposed to the entire internet. This simple change, intended for convenience, inadvertently opens a massive security hole.
Here’s a simple Python script to demonstrate how easily any application can interact with the Ollama API. If the server is exposed, anyone can run code like this against it.
import requests
import json
# The URL for the local Ollama API
# If OLLAMA_HOST is 0.0.0.0, this could be a public IP
OLLAMA_URL = "http://127.0.0.1:11434/api/generate"
# The data payload for the request
payload = {
"model": "llama3",
"prompt": "Why is securing local LLM servers important?",
"stream": False
}
try:
# Send the POST request
response = requests.post(OLLAMA_URL, json=payload)
response.raise_for_status() # Raise an exception for bad status codes
# Parse and print the response
response_data = response.json()
print(response_data.get('response', 'No response content found.'))
except requests.exceptions.RequestException as e:
print(f"Error connecting to Ollama server: {e}")
print("Please ensure the Ollama server is running and accessible.")
The Severe Risks of an Exposed Ollama Instance
An unprotected Ollama API endpoint is not just a minor misconfiguration; it’s a gateway for abuse that can lead to serious consequences. The risks span from resource hijacking to data leakage and system manipulation.
Unauthorized Resource Consumption and Denial of Service
LLM inference is computationally intensive, consuming significant CPU, RAM, and especially GPU resources. An exposed Ollama instance is an open invitation for malicious actors to use your hardware for their own purposes, free of charge. This can manifest in several ways:
- Denial of Service (DoS): Attackers can bombard your server with complex, long-running prompts, maxing out your GPU and CPU, and making the machine unusable for you.
- Cryptojacking: While less direct, an attacker with access could potentially probe for other system vulnerabilities to install cryptocurrency mining software.
- Financial Drain: If you are running the instance on a cloud provider like AWS SageMaker, Vertex AI, or Azure Machine Learning, this unauthorized usage will translate directly into a massive, unexpected bill.
Data Exfiltration and Sensitive Information Leaks
Many advanced applications use LLMs in Retrieval-Augmented Generation (RAG) pipelines, often powered by frameworks like LangChain or Haystack and vector databases such as Pinecone, Weaviate, or Chroma. In these systems, sensitive documents are chunked, embedded, and fed into the LLM’s context window to answer user queries.
If the underlying Ollama API is exposed, an attacker could potentially craft malicious prompts to trick the RAG application into revealing sensitive information from the documents it has access to. This is a classic prompt injection attack, but one that is executed through an unprotected API endpoint, bypassing any application-level security you may have built with tools like Streamlit or Gradio.
Model and System Manipulation
The Ollama API does more than just generate text. It includes administrative endpoints for managing the models on the server. An attacker can use these endpoints to cause significant disruption:
- List Models: An attacker can enumerate all the models you have, including potentially proprietary, fine-tuned models.
- Delete Models: An attacker can send a simple API request to delete your models, destroying hours of work and causing application failure.
- Pull Malicious Models: The API allows for creating and modifying models via a Modelfile. An attacker could potentially craft a malicious Modelfile to probe the local system or consume excessive disk space by pulling dozens of large models.
This Python script shows how trivial it is for an attacker to list the models on an exposed server, which is often the first step in a targeted attack.
import requests
import json
# Replace with the public IP of an exposed server
EXPOSED_OLLAMA_IP = "http://TARGET_IP_ADDRESS:11434"
def list_models(server_url):
"""
Connects to an Ollama server and lists the available models.
"""
try:
response = requests.get(f"{server_url}/api/tags")
response.raise_for_status()
models = response.json().get("models", [])
if not models:
print("No models found on the server.")
return
print("Found the following models:")
for model in models:
print(f"- {model['name']} (Size: {model['size'] / 1e9:.2f} GB)")
except requests.exceptions.RequestException as e:
print(f"Could not connect to the Ollama server at {server_url}. Error: {e}")
if __name__ == "__main__":
list_models(EXPOSED_OLLAMA_IP)
Practical Steps to Secure Your Ollama Server
Securing your Ollama instance involves a layered approach. By combining proper configuration, network controls, and a reverse proxy, you can create a robust and secure setup.
Step 1: Use Proper Host Binding
The first and most important rule is to never bind Ollama to 0.0.0.0 on a machine with a public IP address unless it is protected by a firewall. If you need network access within a trusted local network, bind it to the machine’s specific private IP address (e.g., 192.168.1.100). This prevents it from being accessible from outside your LAN.
Step 2: Implement a Reverse Proxy with Authentication

For any scenario that requires exposing Ollama beyond the local machine, the best practice is to place it behind a reverse proxy like Nginx or Caddy. The reverse proxy acts as a secure gatekeeper. It can handle TLS/SSL encryption (HTTPS), enforce authentication, and then forward valid requests to the Ollama server, which remains safely bound to localhost.
Here is an example Nginx configuration that adds a layer of Basic Authentication and proxies requests to the local Ollama instance. This is a powerful technique also used to protect MLOps dashboards from tools like MLflow or ClearML.
server {
listen 80;
server_name your_domain.com; # Or your server's IP
# Redirect all HTTP traffic to HTTPS
location / {
return 301 https://$host$request_uri;
}
}
server {
listen 443 ssl;
server_name your_domain.com;
# SSL Certificate paths (use Let's Encrypt or your own certs)
ssl_certificate /etc/letsencrypt/live/your_domain.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/your_domain.com/privkey.pem;
location / {
# Add Basic Authentication
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.htpasswd; # Path to password file
# Proxy requests to the local Ollama server
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# Settings for handling streaming responses
proxy_buffering off;
proxy_cache off;
proxy_set_header Connection '';
proxy_http_version 1.1;
chunked_transfer_encoding on;
}
}
To create the .htpasswd file for authentication, you can use the htpasswd utility (often included with Apache tools):
# Install apache2-utils if you don't have it
sudo apt-get update
sudo apt-get install -y apache2-utils
# Create a new user (you will be prompted for a password)
sudo htpasswd -c /etc/nginx/.htpasswd your_username
Step 3: Configure Your Firewall
A firewall is your first line of defense. Even if you misconfigure a service, a firewall can prevent it from being exposed. Using a tool like UFW (Uncomplicated Firewall) on Linux, you should adopt a “deny by default” policy and only open the ports you absolutely need (like SSH, HTTP, and HTTPS).
Crucially, you should ensure that port 11434 is not open to the public. The only traffic it should receive is from the local reverse proxy.
Advanced Considerations and Production Environments
For more complex or production-level deployments, you should integrate additional layers of security and operational best practices, drawing inspiration from the broader MLOps and AI infrastructure world, including trends seen in Google DeepMind News and Meta AI News.

Containerization and Orchestration
Running Ollama inside a Docker container provides process isolation and simplifies dependency management. When deploying in a container orchestrator like Kubernetes, you can leverage Network Policies to create granular firewall rules, explicitly defining that only the reverse proxy pod is allowed to communicate with the Ollama pod on port 11434. This is a standard pattern for deploying scalable inference services, similar to how one might deploy a model optimized with TensorRT on a Triton Inference Server.
Connecting Securely from Frameworks
When integrating your newly secured Ollama instance with a framework like LangChain, you must update your client-side code to connect to the secure endpoint (the reverse proxy) and provide the necessary credentials. This ensures the entire chain of communication is secure.
from langchain_community.llms import Ollama
import os
# It's better to use environment variables for credentials
# For this example, we'll hardcode them.
# In a real app, use os.getenv("OLLAMA_USERNAME") etc.
USERNAME = "your_username"
PASSWORD = "your_password"
# The URL points to your Nginx reverse proxy, not directly to Ollama
SECURE_OLLAMA_URL = "https://your_domain.com"
# LangChain's Ollama integration does not directly support basic auth headers.
# A common workaround is to embed credentials in the URL.
# NOTE: This is only secure over HTTPS.
# Nginx and other proxies can be configured to read credentials from the URL.
llm = Ollama(
model="llama3",
base_url=f"https://{USERNAME}:{PASSWORD}@{SECURE_OLLAMA_URL.replace('https://', '')}"
)
# Now you can use the LLM object as usual
response = llm.invoke("Explain the importance of layered security for AI applications.")
print(response)
Conclusion: Security as a Core Tenet of AI Development
Ollama has done a remarkable job of democratizing access to powerful LLMs, making it a key player in the ongoing wave of AI innovation, alongside major announcements in OpenAI News and Anthropic News. Its ease of use is a major feature, but it places the responsibility for secure configuration squarely on the developer. The risks of an exposed instance—from resource theft to data breaches—are severe and entirely avoidable.
By following the best practices outlined in this guide, you can confidently and securely leverage Ollama in your projects. Always remember the core principles: never expose the service directly to the internet by binding to 0.0.0.0, always place it behind a reverse proxy for authentication and encryption, and use a firewall as your first line of defense. As the AI landscape matures, building with a security-first mindset is not just a best practice; it is a fundamental requirement for creating robust, reliable, and trustworthy applications.


