
Mastering MLOps: A Deep Dive into Experiment Tracking and Model Management with Comet ML
In the rapidly evolving landscape of machine learning, moving from a Jupyter notebook to a production-ready model is a journey fraught with challenges. Reproducibility, collaboration, and scalability are no longer optional luxuries but essential requirements for any serious ML team. This is the core problem that MLOps (Machine Learning Operations) aims to solve. At the heart of a robust MLOps strategy lies a critical component: experiment tracking. Without it, teams are flying blind, unable to compare model versions, reproduce results, or understand what truly drives performance. This is where platforms like Comet ML shine, providing a comprehensive suite of tools to manage the entire lifecycle of a model, from initial experimentation to production monitoring.
Comet ML offers a centralized platform to track, compare, explain, and reproduce your machine learning experiments. It serves as a single source of truth for your team, capturing everything from code and hyperparameters to metrics, model weights, and data lineage. By automating the tedious and error-prone process of manual logging, Comet empowers data scientists to focus on what they do best: building better models. This article will provide a comprehensive technical guide to leveraging Comet ML, exploring its core functionalities, integration with popular frameworks, advanced features, and best practices for building a scalable and efficient MLOps pipeline.
The Foundation: Understanding and Implementing Core Experiment Tracking
At its core, Comet ML is built around the concepts of Workspaces, Projects, and Experiments. A Workspace is the top-level organization, typically for your team or company. Within a Workspace, you create Projects to group related experiments, such as “customer-churn-prediction” or “image-classification-v2”. Each time you run your training script, a new Experiment is created within that project, automatically capturing a wealth of information.
Getting started is remarkably simple. After signing up for Comet and creating a project, you’ll receive an API key. The integration into your Python code requires just a few lines.
Setting Up Your First Experiment
Let’s begin with a basic example using Scikit-learn to train a simple classifier. This demonstrates how effortlessly Comet can be integrated into an existing workflow to log hyperparameters and evaluation metrics.
First, ensure you have the necessary libraries installed:
pip install comet_ml scikit-learnNext, modify your training script to include the Comet Experiment object. The `Experiment` object is the primary interface for logging data to the Comet platform. By placing it at the beginning of your script using a `with` statement, it automatically captures stdout, code, installed packages, and system metrics.
import comet_ml
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.datasets import make_classification
# Initialize the Comet Experiment
# Replace with your API key and project details
experiment = comet_ml.Experiment(
api_key="YOUR_API_KEY",
project_name="sklearn-classification",
workspace="YOUR_WORKSPACE_NAME"
)
# --- 1. Data Preparation ---
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_redundant=5, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# --- 2. Hyperparameter Definition ---
params = {
"solver": "liblinear",
"C": 0.1,
"random_state": 42,
"max_iter": 100
}
# Log hyperparameters to Comet
experiment.log_parameters(params)
# --- 3. Model Training ---
model = LogisticRegression(**params)
model.fit(X_train, y_train)
# --- 4. Model Evaluation ---
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
# Log metrics to Comet
experiment.log_metric("accuracy", accuracy)
print(f"Model Accuracy: {accuracy:.4f}")
# The experiment will automatically end when the script finishes
print("Experiment logged successfully to Comet ML!")After running this script, you can navigate to your Comet UI. You’ll find a new experiment containing the logged hyperparameters (`solver`, `C`, etc.), the final accuracy metric, system information, your source code, and much more. This creates an immutable record of your run, which is the first step toward true reproducibility.
Deep Integration with Modern ML Frameworks
While the basic setup is powerful, Comet’s true strength is revealed through its deep integrations with popular frameworks. The latest PyTorch News and TensorFlow News often highlight new features for distributed training or performance optimization, and having an MLOps tool that seamlessly supports these is crucial. Comet provides auto-logging capabilities for many frameworks, which minimizes the amount of boilerplate code you need to write.
Tracking a PyTorch Training Loop
Let’s consider a common scenario: training a simple neural network with PyTorch. Comet can automatically log metrics like loss and accuracy at each step or epoch, allowing you to visualize the training process in real-time.
import comet_ml
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
# Initialize Comet Experiment
experiment = comet_ml.Experiment(
api_key="YOUR_API_KEY",
project_name="pytorch-mnist-example",
workspace="YOUR_WORKSPACE_NAME"
)
# --- Hyperparameters ---
hyperparams = {
"learning_rate": 0.01,
"epochs": 10,
"batch_size": 64,
"architecture": "SimpleNN"
}
experiment.log_parameters(hyperparams)
# --- Dummy Data and Model ---
X_train = torch.randn(500, 784)
y_train = torch.randint(0, 10, (500,))
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=hyperparams["batch_size"])
model = nn.Sequential(
nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=hyperparams["learning_rate"])
# --- Training Loop ---
model.train()
for epoch in range(hyperparams["epochs"]):
epoch_loss = 0
for i, (inputs, labels) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Log batch-level loss
experiment.log_metric("batch_loss", loss.item(), step=(epoch * len(train_loader) + i))
epoch_loss += loss.item()
avg_epoch_loss = epoch_loss / len(train_loader)
# Log epoch-level loss
experiment.log_metric("epoch_loss", avg_epoch_loss, epoch=epoch + 1)
print(f"Epoch {epoch+1}/{hyperparams['epochs']}, Loss: {avg_epoch_loss:.4f}")
# Log the model file to Comet
torch.save(model.state_dict(), "model.pth")
experiment.log_model("SimpleNN-model", "model.pth")
print("PyTorch training complete and logged to Comet.")In this example, we use `experiment.log_metric()` inside the training loop. By providing `step` and `epoch` arguments, we give Comet the context to create beautiful, interactive charts of our training curves. This is invaluable for debugging issues like overfitting or slow convergence. Furthermore, by using `experiment.log_model()`, we version our trained model artifact directly with the experiment that produced it, ensuring a clear lineage.
Advanced MLOps: From Hyperparameter Optimization to Model Registry
Once you’ve mastered basic tracking, Comet offers advanced features to professionalize your MLOps workflow. These tools help automate tedious tasks, manage model versions for deployment, and gain deeper insights into model behavior.
Automated Hyperparameter Optimization
Finding the optimal set of hyperparameters is a common and time-consuming task. Comet includes a built-in Optimizer that can automate this search. It integrates with algorithms like Bayesian optimization, grid search, and random search. Alternatively, it integrates smoothly with popular libraries like Optuna News or Hyperopt.
Here’s how you can use Comet’s Optimizer to find the best learning rate and batch size for a model.
import comet_ml
# 1. Define the search space and algorithm
config = {
"algorithm": "bayes",
"spec": {
"metric": "accuracy",
"objective": "maximize",
},
"parameters": {
"learning_rate": {"type": "float", "min": 0.001, "max": 0.1, "scalingType": "loguniform"},
"batch_size": {"type": "integer", "min": 32, "max": 128},
"optimizer_type": {"type": "categorical", "values": ["adam", "sgd"]},
},
}
# 2. Create an Optimizer object
optimizer = comet_ml.Optimizer(config, api_key="YOUR_API_KEY", project_name="hyperparam-optimization")
# 3. The training loop
for experiment in optimizer.get_experiments():
# This loop will run for the number of trials you configure in the UI
# Get suggested hyperparameters for this trial
lr = experiment.get_parameter("learning_rate")
batch_size = experiment.get_parameter("batch_size")
optimizer_type = experiment.get_parameter("optimizer_type")
print(f"--- Starting Trial ---")
print(f"Learning Rate: {lr}, Batch Size: {batch_size}, Optimizer: {optimizer_type}")
# --- Your model training logic here ---
# (e.g., build model, create dataloaders with `batch_size`, setup optimizer with `lr`)
# ...
# accuracy = train_and_evaluate_model(lr, batch_size, optimizer_type)
accuracy = 0.85 + (lr * 10) - (batch_size / 1000) # Dummy accuracy calculation
# ---
# Report the final metric back to the optimizer
experiment.log_metric("accuracy", accuracy)
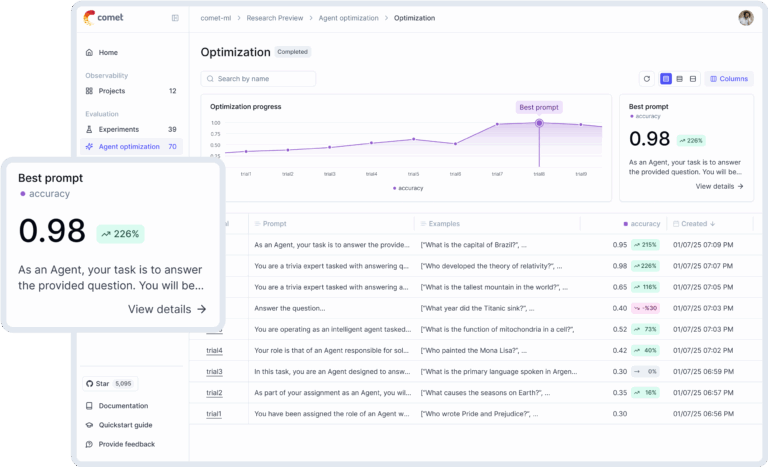
print(f"Trial Accuracy: {accuracy:.4f}\n")The Comet UI provides a dedicated view for optimization, showing which parameter combinations performed best and visualizing the search space. This is far more efficient than manual tuning and integrates seamlessly with the rest of the experiment tracking ecosystem, including tools like Ray News for distributed execution.
The Comet Model Registry
A trained model file is just an artifact. A production-ready model needs versioning, documentation, and stage management (e.g., `development`, `staging`, `production`). The Comet Model Registry provides this functionality. After logging a model from an experiment, you can “register” it, giving it a version number (e.g., `customer-churn-v1.2.0`).
This registry becomes the central hub for your deployment pipelines. A CI/CD system can query the registry to pull the latest model marked for “production” and deploy it using tools like Triton Inference Server on platforms like AWS SageMaker News or Azure Machine Learning News. This decouples the research and deployment phases, allowing data scientists to promote models without needing deep DevOps expertise.
Best Practices and The Broader AI Ecosystem
To maximize the benefits of Comet ML, it’s essential to follow best practices and understand how it fits into the broader AI landscape, which includes everything from LLM frameworks to vector databases.
Tips for Effective Experiment Management
- Consistent Naming Conventions: Establish clear naming schemes for your projects and experiments. Use tags (e.g., `baseline`, `feature-engineering-v2`, `final-candidate`) to easily filter and group experiments.
- Log Configuration Files: In addition to hyperparameters, log your entire configuration file (e.g., `config.yaml`) as an asset using `experiment.log_asset()`. This ensures perfect reproducibility.
- Leverage Custom Panels: The Comet UI is highly customizable. Create custom panels and visualizations to display the specific metrics and charts that are most important for your project.
- Integrate with CI/CD: Automate your model training and evaluation by triggering your scripts from a CI/CD pipeline (e.g., GitHub Actions, Jenkins). Set your Comet API key as a secret and run experiments on every commit to a specific branch.
Comet in the Age of LLMs and Generative AI
The rise of Large Language Models (LLMs) has introduced new MLOps challenges. The latest OpenAI News and Hugging Face News show a rapid pace of innovation, and tracking experiments in this domain is critical. Comet is adapting to this with features for LLM application development.
You can use Comet to log prompts, responses, and evaluation metrics when working with frameworks like LangChain News or LlamaIndex News. This is crucial for debugging complex chains and understanding how changes to prompts or retrieval mechanisms affect output quality. When fine-tuning models from sources like Mistral AI News or using frameworks like Hugging Face Transformers News, Comet can track the training process and store the resulting model adapters in its registry. For retrieval-augmented generation (RAG) systems, you can even log metadata about the documents retrieved from vector databases like Pinecone News, Milvus News, or Chroma News.
import comet_ml
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# This requires a specific integration or a manual logging approach
# For demonstration, we'll use a context manager for tracking
# Note: Official LLM support in tools like Comet is rapidly evolving.
# Always check the latest documentation.
experiment = comet_ml.Experiment(project_name="langchain-prompt-tracking")
# Log parameters related to the prompt/chain
experiment.log_parameter("model_name", "text-davinci-003")
experiment.log_parameter("temperature", 0.7)
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
template = "What is a good name for a company that makes {product}?"
prompt = PromptTemplate(template=template, input_variables=["product"])
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain and log the interaction
product_name = "colorful socks"
response = chain.run(product_name)
# Log the inputs and outputs as a dictionary or text
experiment.log_text(f"Input Product: {product_name}")
experiment.log_text(f"Generated Name: {response}")
experiment.log_others({
"prompt_template": template,
"input_variables": {"product": product_name},
"output": response
})
print(f"Prompt and response logged to Comet experiment: {experiment.get_key()}")This level of detailed logging helps teams iterate on prompts and RAG pipelines with the same rigor they apply to traditional model training. Comparing different prompts side-by-side in the Comet UI becomes a powerful tool for prompt engineering.
Conclusion: Your Path to Scalable MLOps
In the competitive world of AI, speed and reliability are paramount. Adopting a systematic approach to experiment tracking is no longer a “nice-to-have” but a foundational element of a successful machine learning practice. Platforms like Comet ML, and its alternatives discussed in MLflow News and Weights & Biases News, provide the essential infrastructure to build reproducible, collaborative, and scalable MLOps workflows.
By integrating Comet into your development lifecycle, you create a centralized, searchable history of all your modeling efforts. This empowers your team to learn from past work, avoid repeating mistakes, and confidently move models from research to production. From tracking simple Scikit-learn models to managing complex hyperparameter sweeps and logging LLM interactions, Comet provides a unified platform to accelerate your entire ML lifecycle. The next step is to integrate it into your own project—start small by tracking a single script, and gradually expand its use to build a truly robust and automated MLOps foundation.


