
Bridging LLMs and Structured Data: A Deep Dive into LlamaIndex for Advanced SQL Querying
The artificial intelligence landscape is rapidly evolving, with Large Language Models (LLMs) moving from novelties to essential components of the modern enterprise technology stack. While much of the initial focus has been on processing unstructured text, the real treasure trove of business intelligence often lies within structured databases. The central challenge has become: how can we empower non-technical users to converse with complex SQL databases using natural language? This is where LlamaIndex emerges as a critical data framework, providing the essential bridge between the conversational power of LLMs and the structured query language of databases. This article offers a comprehensive technical exploration of how to leverage LlamaIndex to build powerful, intuitive Text-to-SQL applications.
As developments in the AI space accelerate, with constant updates from sources like OpenAI News, Anthropic News, and Mistral AI News, the tools that connect these models to proprietary data are becoming increasingly vital. LlamaIndex, alongside frameworks like LangChain News, is at the forefront of this movement, offering sophisticated solutions for data ingestion, indexing, and querying. We will delve into the core concepts, provide practical implementation guides with SQL and Python code, explore advanced techniques for enhancing accuracy, and outline best practices for building robust, production-ready systems. This guide will equip you with the knowledge to transform your organization’s relationship with its data, making it more accessible and actionable than ever before.
Core Concepts: Translating Natural Language to SQL
At its heart, the Text-to-SQL capability of LlamaIndex is about translation. It takes a user’s question, posed in plain English, and translates it into a precise, executable SQL query. This process is far more sophisticated than simple keyword matching; it involves the LLM understanding the user’s intent, the database schema, and the relationships between different data entities. The primary component for this task in LlamaIndex is the NLSQLTableQueryEngine.
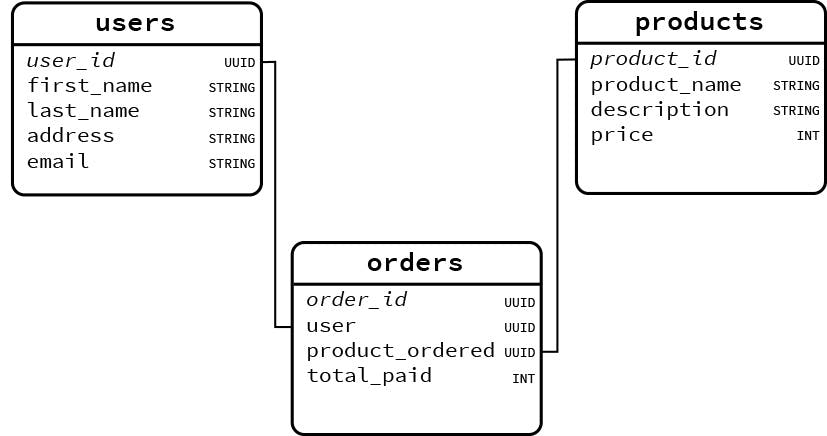
This engine works by first introspecting the database schema—the table names, column names, data types, and foreign key relationships. It then synthesizes this structural information into a context prompt that is provided to the LLM along with the user’s question. The LLM uses this combined context to generate the appropriate SQL query. To begin, let’s define a simple database schema that we will use throughout our examples. Imagine a corporate database with two tables: employees and departments.
-- SQL Schema for our demonstration
CREATE TABLE departments (
department_id INT PRIMARY KEY,
department_name VARCHAR(100) NOT NULL,
location VARCHAR(100)
);
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE,
job_title VARCHAR(50),
salary DECIMAL(10, 2),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id)
);
-- Insert some sample data
INSERT INTO departments (department_id, department_name, location) VALUES
(1, 'Engineering', 'Mountain View'),
(2, 'Human Resources', 'New York'),
(3, 'Sales', 'Chicago');
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date, job_title, salary, department_id) VALUES
(101, 'Alice', 'Williams', '[email protected]', '2021-06-15', 'Software Engineer', 95000.00, 1),
(102, 'Bob', 'Johnson', '[email protected]', '2020-08-01', 'Senior Engineer', 120000.00, 1),
(103, 'Charlie', 'Brown', '[email protected]', '2022-01-20', 'HR Manager', 85000.00, 2),
(104, 'Diana', 'Miller', '[email protected]', '2019-11-11', 'Sales Director', 150000.00, 3);With this schema, the LLM needs to understand that to find out which department an employee works in, it must join the employees table with the departments table using the department_id key. LlamaIndex facilitates this by packaging the schema information efficiently for the model. This core concept is what powers the entire Text-to-SQL workflow and is a foundational element in the broader landscape of AI tools, including platforms discussed in Azure AI News and Snowflake Cortex News.
Practical Implementation: Building Your First SQL Query Engine
Let’s move from theory to practice. Building a basic Text-to-SQL query engine with LlamaIndex is remarkably straightforward. The first step is to establish a connection to your database. LlamaIndex uses SQLAlchemy, a popular Python SQL toolkit and Object-Relational Mapper, to interact with a wide variety of database backends. For this example, we’ll use an in-memory SQLite database for simplicity, but the same code works for PostgreSQL, MySQL, and others with a simple connection string change.
You will need to install the necessary libraries:

pip install llama-index sqlalchemy openaiNext, we’ll write the Python code to set up the database engine, connect LlamaIndex to it, and initialize the query engine. We’ll use OpenAI’s GPT-3.5 Turbo as our LLM, but you could easily swap this with models from other providers like Cohere or local models via tools like Ollama News.
import os
from sqlalchemy import (
create_engine,
text
)
from llama_index.core import SQLDatabase
from llama_index.core.query_engine import NLSQLTableQueryEngine
from llama_index.llms.openai import OpenAI
# Set your OpenAI API key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
# Create an in-memory SQLite database
engine = create_engine("sqlite:///:memory:")
# --- Populate the database with our schema and data ---
sql_schema_script = """
CREATE TABLE departments (
department_id INT PRIMARY KEY,
department_name VARCHAR(100) NOT NULL,
location VARCHAR(100)
);
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE,
job_title VARCHAR(50),
salary DECIMAL(10, 2),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id)
);
INSERT INTO departments (department_id, department_name, location) VALUES
(1, 'Engineering', 'Mountain View'),
(2, 'Human Resources', 'New York'),
(3, 'Sales', 'Chicago');
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date, job_title, salary, department_id) VALUES
(101, 'Alice', 'Williams', '[email protected]', '2021-06-15', 'Software Engineer', 95000.00, 1),
(102, 'Bob', 'Johnson', '[email protected]', '2020-08-01', 'Senior Engineer', 120000.00, 1),
(103, 'Charlie', 'Brown', '[email protected]', '2022-01-20', 'HR Manager', 85000.00, 2),
(104, 'Diana', 'Miller', '[email protected]', '2019-11-11', 'Sales Director', 150000.00, 3);
"""
with engine.connect() as connection:
for statement in sql_schema_script.strip().split(';'):
if statement.strip():
connection.execute(text(statement))
# --- LlamaIndex Setup ---
sql_database = SQLDatabase(engine, include_tables=["employees", "departments"])
# Initialize the LLM
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Create the query engine
query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["employees", "departments"],
llm=llm
)
# --- Query the engine ---
question = "How many employees work in the Engineering department?"
response = query_engine.query(question)
print("Question:", question)
print("SQL Query Generated:", response.metadata['sql_query'])
print("Natural Language Response:", str(response))
When you run this code, LlamaIndex will generate a SQL query similar to SELECT count(*) FROM employees e JOIN departments d ON e.department_id = d.department_id WHERE d.department_name = 'Engineering', execute it against the database, and then synthesize the result into a human-readable answer like “There are 2 employees working in the Engineering department.” This transparency is a key feature, allowing developers to debug and verify the logic generated by the LLM, a crucial step for building trust in the system. This approach is fundamental to creating modern data applications, a trend also seen in tools like Streamlit News and Gradio News which provide front-ends for such back-end engines.
Advanced Techniques: Improving Accuracy with Rich Context
While the basic engine is powerful, real-world databases are often messy. They contain cryptic column names (e.g., emp_stat), encoded values (‘A’ for ‘Active’), or complex business logic that isn’t obvious from the schema alone. To handle these cases, you must provide the LLM with richer context. LlamaIndex offers powerful ways to inject this domain-specific knowledge directly into the context.
One of the most effective methods is to provide explicit text descriptions for tables and columns. This acts as a “cheat sheet” for the LLM, guiding it to generate more accurate queries. Let’s imagine our schema is slightly more complex, with an employee status column and a less obvious naming convention.
Using Table and Column Context
We can create a dictionary to hold our custom context and pass it to the query engine. This helps the model understand nuances that are impossible to infer from the schema alone. This technique is especially important when dealing with legacy databases or complex data warehouses, a common challenge discussed in news from the Apache Spark MLlib News and DataRobot News communities.
from sqlalchemy import create_engine, text
from llama_index.core import SQLDatabase
from llama_index.core.indices.struct_store.sql_query import NLSQLTableQueryEngine
from llama_index.llms.openai import OpenAI
# Assume 'engine' is already created and populated as in the previous example
# --- LlamaIndex Advanced Setup with Context ---
sql_database = SQLDatabase(engine, include_tables=["employees", "departments"])
llm = OpenAI(model="gpt-4-turbo", temperature=0) # Using a more powerful model for complex tasks
# Define rich context for the tables
table_details = {
"employees": (
"This table contains information about all company employees. "
"The 'salary' column is in USD and represents the annual gross salary. "
"Use a JOIN with the 'departments' table to find department names."
),
"departments": (
"This table lists all company departments and their primary office location."
),
}
query_engine = NLSQLTableQueryEngine(
sql_database=sql_database,
tables=["employees", "departments"],
llm=llm,
context_str_by_table=table_details, # Pass the context here
)
# --- Query the engine with a more complex question ---
question = "What is the average salary for employees in the Mountain View office?"
response = query_engine.query(question)
print("Question:", question)
print("SQL Query Generated:", response.metadata['sql_query'])
print("Natural Language Response:", str(response))
# Example of another complex query
question_2 = "List the names of employees hired before 2021 who are not in the Sales department."
response_2 = query_engine.query(question_2)
print("\nQuestion:", question_2)
print("SQL Query Generated:", response_2.metadata['sql_query'])
print("Natural Language Response:", str(response_2))
In this advanced example, the context provided in table_details helps the LLM understand the relationship between employee salary and department location, even though there’s no direct link in the employees table. It correctly infers that it needs to join employees with departments and then filter by the location column. This ability to inject human knowledge is what elevates LlamaIndex from a simple tool to a powerful framework for building sophisticated data analysis applications, rivaling capabilities seen in platforms from AWS SageMaker News and Vertex AI News.
Best Practices and Production Considerations
Deploying a Text-to-SQL system into a production environment requires careful consideration of security, performance, and reliability. Here are some essential best practices to follow:
Security is Paramount
Never connect an LLM-powered query engine to your production database with write permissions. There is always a risk, however small, of the LLM generating a destructive query (e.g., DROP TABLE) or a query that modifies data unintentionally. Always use a dedicated, read-only database user for the application. For an even higher level of security, consider setting up a read replica of your database and pointing the application to it, completely isolating it from your primary production instance.
Optimize for Performance and Cost
LLM API calls can be slow and expensive. Implement a caching layer (like Redis or Memcached) to store the results of frequently asked questions. If a user asks the same question twice, you can serve the cached response instantly without hitting the LLM or the database. Furthermore, choose your model wisely. While a powerful model from Google DeepMind News like Gemini or OpenAI’s GPT-4 might produce more accurate SQL, a smaller, fine-tuned model could offer a better balance of performance and cost for your specific use case.

Monitoring and Logging
Log every question, the generated SQL, and the final response. This data is invaluable for debugging issues and identifying patterns of failure. Tools like LangSmith News or open-source libraries like MLflow News can be used to track the performance of your LLM application over time. This continuous monitoring allows you to refine your prompts, update your table context, and improve the overall accuracy and reliability of the system.
Conclusion and Next Steps
LlamaIndex provides a robust and remarkably accessible framework for bridging the gap between human language and structured SQL databases. By intelligently packaging schema information and allowing for the injection of rich, domain-specific context, it empowers developers to build powerful applications that democratize data access. We’ve journeyed from the core concepts of Text-to-SQL translation to a practical implementation and explored advanced techniques for handling real-world complexity. The journey doesn’t end here; the ecosystem of AI tools, including vector databases like Pinecone News and Chroma News, can be combined with LlamaIndex to query both structured and unstructured data simultaneously.
As enterprises continue to invest in AI infrastructure, frameworks like LlamaIndex will become the standard for building the next generation of data-driven applications. The key takeaway is to start small, prioritize security, and iteratively enhance your system with better context and monitoring. By following these principles, you can unlock the immense value hidden within your databases and empower your entire organization to make smarter, data-informed decisions.


