
Bridging the Gap: Unifying Experiment Management and GPU Orchestration for End-to-End MLOps
Introduction: The Two Pillars of a Scalable MLOps Lifecycle
In the rapidly evolving landscape of machine learning, moving from a promising model in a Jupyter notebook to a robust, production-grade application is a monumental challenge. This journey, often encapsulated by the term MLOps, rests on two fundamental pillars: meticulous experiment management and efficient resource orchestration. On one side, we have platforms that track every detail of the model development process—hyperparameters, metrics, code versions, and datasets. On the other, we have systems that manage the underlying hardware, particularly the scarce and expensive GPU resources required for training and inference. Historically, these two domains have operated in separate silos, creating a significant bottleneck for teams aiming to scale their AI initiatives. This disconnect forces data scientists to become part-time infrastructure engineers and IT teams to struggle with the unpredictable, bursty workloads of ML training.
The latest trends in the MLOps world, reflected in recent Comet ML News and developments from competitors, point towards a powerful convergence. By integrating experiment management platforms directly with GPU orchestration and scheduling systems, organizations can create a seamless, automated workflow that covers the entire ML lifecycle. This synergy allows data scientists to focus on building better models while the underlying infrastructure dynamically allocates resources, tracks progress, and streamlines the path to production. This article explores this critical integration, detailing how to combine the strengths of experiment tracking with powerful orchestration to build a truly efficient and scalable MLOps pipeline.
Section 1: Core Concepts – Experiment Tracking Meets Resource Management
To understand the power of this integration, it’s essential to first grasp the distinct roles of each component and why their separation creates friction in the MLOps lifecycle.
What is Experiment Management?
Experiment management platforms are the digital lab notebooks for modern data science. They provide a centralized system to automatically log, visualize, and compare machine learning experiments. Key features include:
- Metric & Parameter Logging: Automatically capturing training/validation loss, accuracy, F1-scores, learning rates, batch sizes, and other hyperparameters.
- Artifact Storage: Storing model weights, datasets, and visualizations associated with an experiment.
- Collaboration & Reproducibility: Enabling teams to share results, compare different approaches, and easily reproduce any past experiment.
* Code & Environment Tracking: Versioning the exact code (via Git integration), library dependencies (e.g., requirements.txt), and even Docker container images used for a run.
Platforms like Comet, MLflow, and Weights & Biases are leaders in this space. Integrating them into a training script is typically straightforward. For example, here’s how you might add Comet to a basic PyTorch training loop.
# main_train.py
import comet_ml
import torch
import torch.nn as nn
from torch.optim import SGD
# --- 1. Initialize Comet Experiment ---
# Best practice: Use environment variables for API keys
experiment = comet_ml.Experiment(
api_key="YOUR_API_KEY",
project_name="image-classification",
workspace="your-workspace",
)
# --- 2. Define Hyperparameters ---
hyper_params = {
"learning_rate": 0.01,
"batch_size": 64,
"epochs": 10,
"optimizer": "SGD"
}
experiment.log_parameters(hyper_params)
# --- Dummy Model and Data ---
model = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
optimizer = SGD(model.parameters(), lr=hyper_params["learning_rate"])
criterion = nn.CrossEntropyLoss()
dummy_loader = [(torch.randn(hyper_params["batch_size"], 784), torch.randint(0, 10, (hyper_params["batch_size"],))) for _ in range(100)]
# --- 3. Training Loop with Logging ---
model.train()
for epoch in range(hyper_params["epochs"]):
epoch_loss = 0
for i, (data, labels) in enumerate(dummy_loader):
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dummy_loader)
print(f"Epoch {epoch+1}/{hyper_params['epochs']}, Loss: {avg_loss:.4f}")
# Log metrics to Comet
experiment.log_metric("loss", avg_loss, step=epoch+1)
# --- 4. Log Model Artifact ---
experiment.log_model("final_model", "model.pth")
torch.save(model.state_dict(), "model.pth")
experiment.end()What is GPU Orchestration?
GPU orchestration platforms address the infrastructure side of MLOps. They sit on top of physical or cloud-based clusters (often managed by Kubernetes) and provide intelligent scheduling, resource pooling, and lifecycle management for ML workloads. Their primary goals are:
- Maximize Utilization: Prevent expensive GPUs from sitting idle by pooling them and allocating fractional or full GPUs to jobs as needed.
- Fair Scheduling: Implement queuing and priority systems to ensure teams and critical projects get timely access to resources.
- Simplified Interface: Abstract away the complexities of Kubernetes, allowing data scientists to submit jobs with simple CLI commands or YAML files without needing deep DevOps knowledge.
Tools like Run:ai, NVIDIA’s AI Enterprise, and open-source solutions like Kubeflow or Ray News on Kubernetes are prominent in this area. They manage the “where” and “how” of running the code that the experiment management system tracks.
Section 2: The Integrated Workflow in Practice
The real power emerges when these two systems work in concert. A data scientist can define an experiment, and the orchestration layer automatically provisions the necessary environment and hardware, while the experiment management SDK, running inside the job, transparently reports back all the results.
Step 1: Containerizing the Training Script
The first step is to package the training code and its dependencies into a container. This ensures a consistent and reproducible environment, no matter where the code is run. A `Dockerfile` for our previous example would look like this:
# Use a base image with Python and PyTorch
FROM pytorch/pytorch:1.13.1-cuda11.6-cudnn8-runtime
# Set the working directory
WORKDIR /app
# Copy requirements file and install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the training script
COPY main_train.py .
# Define the command to run when the container starts
CMD ["python", "main_train.py"]The `requirements.txt` file would simply contain:
torch
comet_mlStep 2: Submitting the Job to the Orchestrator
Next, you submit this containerized application as a job to the orchestration platform. Instead of running `python main_train.py` locally, you use the orchestrator’s CLI. This is where you define resource requirements (e.g., 1 NVIDIA A100 GPU) and pass in necessary configurations, like the Comet API key, as environment variables. This is a crucial best practice for security, as it avoids hardcoding secrets in your code or container image.
Here is a conceptual example of a command to submit a job, similar to what you might use with a platform like Run:ai:
runai submit my-training-job \
--image my-docker-registry/my-pytorch-app:latest \
--gpu 1 \
-e COMET_API_KEY=$COMET_API_KEY \
-e COMET_PROJECT_NAME="image-classification-production" \
-e COMET_WORKSPACE="my-org" \
--command "python main_train.py"Notice how the Comet credentials and project details are passed as environment variables (`-e`). The Python script needs a slight modification to read these variables, making it more portable and secure.
# main_train_orchestrated.py
import comet_ml
import torch
import torch.nn as nn
import os # Import the os module
# --- 1. Initialize Comet Experiment from Environment Variables ---
# This is now robust and secure for orchestrated environments
experiment = comet_ml.Experiment(
api_key=os.environ.get("COMET_API_KEY"),
project_name=os.environ.get("COMET_PROJECT_NAME"),
workspace=os.environ.get("COMET_WORKSPACE"),
)
# ... rest of the training script remains the same ...
# --- Dummy Model and Data ---
hyper_params = {
"learning_rate": 0.01,
"batch_size": 64,
"epochs": 10
}
experiment.log_parameters(hyper_params)
model = nn.Sequential(nn.Linear(784, 128), nn.ReLU(), nn.Linear(128, 10))
optimizer = torch.optim.SGD(model.parameters(), lr=hyper_params["learning_rate"])
criterion = nn.CrossEntropyLoss()
dummy_loader = [(torch.randn(hyper_params["batch_size"], 784), torch.randint(0, 10, (hyper_params["batch_size"],))) for _ in range(100)]
# --- Training Loop with Logging ---
model.train()
for epoch in range(hyper_params["epochs"]):
epoch_loss = 0
for i, (data, labels) in enumerate(dummy_loader):
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(dummy_loader)
experiment.log_metric("loss", avg_loss, step=epoch+1)
experiment.end()Step 3: Monitoring and Iteration
Once the job is submitted, the orchestrator finds an available GPU, pulls the container image, and starts the training process. The data scientist can now go to the Comet UI and watch the metrics (loss, accuracy, etc.) stream in real-time. They can see which job on the cluster corresponds to which experiment line in their dashboard. If the experiment is not promising, they can kill the job via the orchestrator’s interface, immediately freeing up the GPU for another user or a more promising experiment. This tight feedback loop is a game-changer for productivity and resource efficiency.
Section 3: Advanced Techniques and Production Pathways
The integration extends far beyond simple training jobs. It forms the backbone of a mature MLOps pipeline, connecting experimentation directly to deployment and monitoring.
Automated Hyperparameter Optimization (HPO)
Most experiment management platforms, including Comet, offer HPO services (or “Sweeps”). An integrated workflow supercharges this process. You can define a search space for your hyperparameters (e.g., learning rate, number of layers) in the Comet UI. Comet’s optimizer then programmatically launches multiple jobs via the orchestration platform, each with a different hyperparameter combination. The orchestrator efficiently schedules these dozens or hundreds of jobs across the entire GPU cluster, and all results are neatly organized back in the Comet dashboard, allowing you to easily identify the top-performing model.
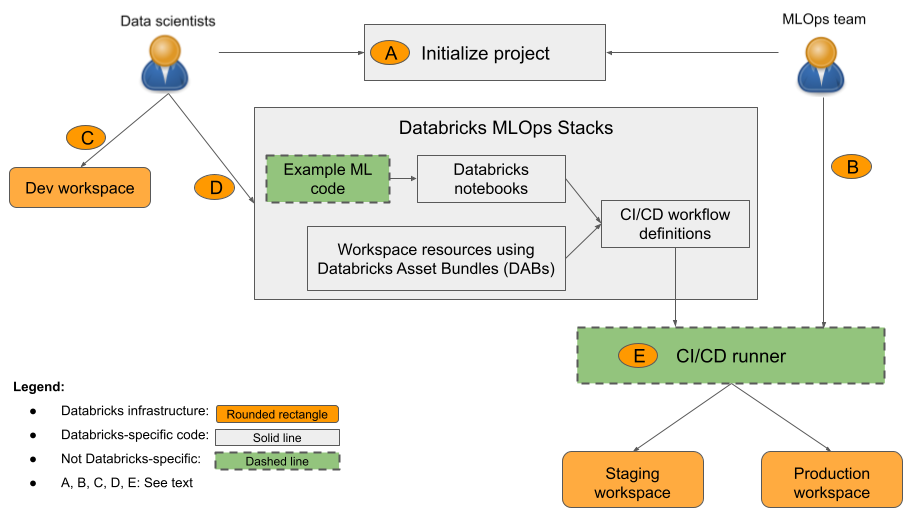
From Experiment to Model Registry
Once a successful experiment is complete, the next step is to promote the resulting model artifact for production use. This is where a Model Registry comes in. Comet, like other platforms, provides a registry to version, stage (e.g., `development`, `staging`, `production`), and document models. Within your training script, you can add logic to evaluate the model and, if it meets a certain performance threshold, automatically register it.
This triggers the next phase of the MLOps pipeline. A CI/CD system (like Jenkins or GitLab CI) can be configured to listen for new models in the registry. Upon a new registration, it can automatically trigger a new job on the orchestration platform to run integration tests, perform security scans, and finally deploy the model to an inference server like Triton Inference Server News or a cloud endpoint like AWS SageMaker News.
Production Model Monitoring
The journey doesn’t end at deployment. The same platform used for tracking training experiments can also be used for production monitoring. By instrumenting your live inference service with the Comet SDK, you can monitor for data drift, concept drift, and performance degradation. When the orchestrator scales your inference service up or down based on traffic, Comet can track the performance across all running instances. If a model’s performance dips below a threshold, alerts can be triggered, automatically notifying the team or even kicking off a new retraining job on the orchestrated cluster, thus closing the MLOps loop.
Section 4: Best Practices and Optimization
To maximize the benefits of this integrated approach, consider the following best practices.
Standardize Environments with Custom Base Images
Instead of having every data scientist build their `Dockerfile` from scratch, create and maintain a set of blessed, pre-configured base container images. These images should include common libraries (TensorFlow News, PyTorch News, Hugging Face Transformers News), the company’s standard data access clients, and the Comet SDK. This reduces boilerplate, ensures consistency, and improves security.
Leverage Dynamic Resource Allocation
Encourage the use of fractional GPUs for tasks that don’t require a full device, such as data preprocessing, small-scale experiments, or running inference with smaller models. Modern orchestration platforms excel at this, effectively multiplying the number of available resources and drastically reducing queue times for developers.
Integrate with CI/CD for Full Automation
Use CI/CD pipelines to automate the entire workflow. A push to a Git repository should trigger a CI job that builds the Docker image, pushes it to a registry, and then uses the orchestrator’s CLI to submit the training job. This creates a fully auditable and reproducible “GitOps” or “Code-to-Cluster” workflow.
Manage Secrets Securely
As shown in the examples, never hardcode API keys or other secrets. Use the secret management capabilities of your orchestration platform (e.g., Kubernetes Secrets) and inject them into your job containers as environment variables at runtime. This is a critical security measure.
Conclusion: A Unified Future for MLOps
The convergence of experiment management and resource orchestration represents a significant leap forward in MLOps maturity. By breaking down the silos between data science and IT operations, this integrated approach creates a powerful, flywheel effect. Data scientists are empowered to run more experiments and iterate faster, freed from the complexities of infrastructure management. MLOps engineers can build robust, automated pipelines that seamlessly transition models from research to production. Most importantly, the organization as a whole benefits from dramatically improved GPU utilization, faster time-to-market for AI products, and a fully reproducible, auditable, and scalable machine learning lifecycle.
As you evaluate your MLOps stack, consider not just the features of individual tools, but how they connect to form a cohesive ecosystem. The synergy between platforms like Comet and orchestration systems is no longer a “nice-to-have” but a foundational requirement for any organization serious about scaling its AI and machine learning initiatives. The latest Comet ML News and industry trends confirm that this unified strategy is the future of production-grade AI.


