
Deploying Custom LLMs with FastAPI: A Practical Guide for Production-Ready AI APIs
The journey of building a custom Large Language Model (LLM) doesn’t end when the training process completes. The true value is unlocked when the model is deployed as a robust, scalable, and efficient API that can be integrated into applications. While frameworks like Flask have long been staples for Python web development, the modern AI landscape demands more. This is where FastAPI shines, offering a powerful combination of high performance, asynchronous capabilities, and developer-friendly features that make it the ideal choice for serving demanding machine learning models.
Building an API for an LLM introduces unique challenges. Inference can be computationally expensive and time-consuming, potentially blocking server resources and leading to a poor user experience. Furthermore, ensuring data integrity for prompts and managing complex model lifecycles are critical for production readiness. FastAPI, built on top of Starlette for performance and Pydantic for data validation, directly addresses these challenges. This article provides a comprehensive guide to deploying your custom-trained LLMs using FastAPI, covering everything from basic setup and inference endpoints to advanced techniques like response streaming and production optimization. We will explore how to leverage the modern Python ecosystem, including insights from the latest Hugging Face Transformers News, to build APIs that are not just functional but also fast and scalable.
The Foundation: Why FastAPI for AI/ML Deployment?
Choosing the right web framework is a critical architectural decision. For AI and ML applications, especially those involving large models, the framework must be more than just a simple request-response handler. It needs to be a high-performance engine that minimizes overhead and maximizes resource utilization. FastAPI has rapidly become a favorite in the ML community for several key reasons.
The Need for Speed and Asynchronicity
LLM inference is a resource-intensive task. The last thing you want is for your web framework to be a bottleneck. FastAPI is one of the fastest Python frameworks available, with performance comparable to NodeJS and Go. This is because it’s built on Starlette, a lightweight ASGI (Asynchronous Server Gateway Interface) framework. Unlike traditional WSGI frameworks, ASGI supports asynchronous code, allowing for high concurrency.
Asynchronous support via async and await is a game-changer. While LLM inference itself is often a synchronous, CPU/GPU-bound task, an API server must handle many other I/O-bound operations, such as database queries, calls to other services, or simply managing thousands of concurrent network connections. By using async, FastAPI can handle these I/O-bound tasks efficiently without blocking, ensuring the server remains responsive even under heavy load. This is a crucial feature that sets it apart from older frameworks and is a constant topic in FastAPI News and development circles.
Data Validation and API Documentation with Pydantic
Every ML engineer knows the principle of “garbage in, garbage out.” Pydantic, a core dependency of FastAPI, enforces strict data validation using standard Python type hints. You define the expected structure of your request and response data as a Pydantic model, and FastAPI handles the rest. It automatically parses incoming JSON, validates it against your model, and raises clear, informative errors if the data is invalid. This eliminates a massive amount of boilerplate validation code and ensures your model only receives well-formed inputs.
A major bonus of this integration is the automatic, interactive API documentation. FastAPI generates an OpenAPI (formerly Swagger) schema from your Pydantic models and path operations. This gives you a rich, interactive UI at /docs where developers can explore your API endpoints, see the required data schemas, and even test them directly from the browser. This feature drastically simplifies API integration and is invaluable for team collaboration.

API architecture diagram – Ads-Guard architecture and mechanism showing how a classified Ad …
# main.py
from fastapi import FastAPI
from pydantic import BaseModel, Field
# Initialize the FastAPI app
app = FastAPI(
title="Custom LLM Inference API",
description="An API to serve a custom-trained LLM for text generation.",
version="1.0.0",
)
# Pydantic model for request validation
class TextGenerationRequest(BaseModel):
prompt: str = Field(
...,
min_length=10,
max_length=512,
example="Once upon a time in a land of code,"
)
max_new_tokens: int = Field(default=100, gt=0, le=512)
# Pydantic model for the response
class TextGenerationResponse(BaseModel):
generated_text: str
prompt_tokens: int
generated_tokens: int
@app.post("/generate", response_model=TextGenerationResponse)
def generate_text(request: TextGenerationRequest):
"""
A placeholder endpoint to demonstrate request/response handling.
The actual model logic will be added later.
"""
# Dummy logic for now
full_text = f"{request.prompt} ... and they coded happily ever after."
return TextGenerationResponse(
generated_text=full_text,
prompt_tokens=len(request.prompt.split()),
generated_tokens=len(full_text.split()) - len(request.prompt.split())
)Implementing the LLM Inference Endpoint
With the foundational structure in place, the next step is to integrate the actual machine learning model. This involves loading the model efficiently and building the core inference logic that will power the API endpoint.
Loading and Managing the Model Lifecycle
Loading a large language model from disk into memory is a slow and resource-intensive operation. It should never be done within the request-response cycle. The model should be loaded once when the application starts and then held in memory to serve all subsequent requests. FastAPI provides a clean way to manage this using startup and shutdown events.
We can define an event handler with the @app.on_event("startup") decorator. This function will be executed when the FastAPI application launches, making it the perfect place to load our model and tokenizer from a library like Hugging Face Transformers News. We can store these objects in a global dictionary or a dedicated state management class to make them accessible to our API endpoints. This approach is far more efficient than loading the model on every request and is a standard practice for deploying any serious ML model, whether it’s from PyTorch News or TensorFlow News.
Building the Core Inference Logic
Now we can replace the placeholder logic in our /generate endpoint with the actual model inference code. The process typically involves three steps:
- Tokenization: The input prompt string is converted into a sequence of numerical tokens using the model’s tokenizer.
- Generation: The tokenized input is fed into the model, which generates a sequence of new output tokens.
- Decoding: The output tokens are converted back into a human-readable string.
The following example demonstrates how to load a model at startup and use it within an endpoint. For simplicity, we use distilgpt2, a smaller version of GPT-2, but the same principle applies to your custom-trained model.
# main_with_model.py
import torch
from fastapi import FastAPI
from pydantic import BaseModel, Field
from transformers import AutoModelForCausalLM, AutoTokenizer
# --- App and Pydantic Models (same as before) ---
app = FastAPI(title="Custom LLM Inference API")
class TextGenerationRequest(BaseModel):
prompt: str = Field(..., min_length=10, max_length=512)
max_new_tokens: int = Field(default=100, gt=0, le=512)
class TextGenerationResponse(BaseModel):
generated_text: str
# --- Model Loading and Management ---
# Use a dictionary to store the model and tokenizer
model_cache = {}
@app.on_event("startup")
def load_model():
"""
Load the ML model and tokenizer at application startup.
"""
print("Loading model and tokenizer...")
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
model_cache["tokenizer"] = tokenizer
model_cache["model"] = model
model_cache["device"] = device
print("Model and tokenizer loaded successfully.")
@app.post("/generate", response_model=TextGenerationResponse)
def generate_text(request: TextGenerationRequest):
"""
Generate text using the loaded LLM.
"""
tokenizer = model_cache["tokenizer"]
model = model_cache["model"]
device = model_cache["device"]
# 1. Tokenize the input prompt
inputs = tokenizer(request.prompt, return_tensors="pt").to(device)
# 2. Generate new tokens
outputs = model.generate(
**inputs,
max_new_tokens=request.max_new_tokens,
pad_token_id=tokenizer.eos_token_id # Avoid warning
)
# 3. Decode the generated tokens
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return TextGenerationResponse(generated_text=generated_text)Advanced Techniques for Production LLM APIs
A basic inference endpoint is a great start, but production environments demand more sophistication to ensure responsiveness and a good user experience. Let’s explore two advanced techniques: running inference asynchronously and streaming responses.
Asynchronous Inference to Prevent Blocking
A critical pitfall to avoid is running a long, CPU/GPU-bound task like LLM inference directly in an async def route. This will block the server’s event loop, preventing it from handling any other requests until the inference is complete. The application will feel frozen.
API architecture diagram – Architecture Overview: intent is translated and injected into the …
The correct approach is to run the synchronous, blocking model code in a separate thread pool. FastAPI makes this incredibly simple with fastapi.concurrency.run_in_threadpool. By wrapping the synchronous inference call in this function and awaiting it, you delegate the blocking work to a worker thread, freeing the main event loop to remain responsive. Tools like Ray News and Dask News offer more advanced distributed execution, but for a single-server deployment, FastAPI’s built-in concurrency tools are often sufficient.
Streaming Responses for Real-Time Generation
Waiting 30 seconds for a full paragraph to be generated is a poor user experience. A much better approach is to stream the response back to the client token by token, just like you see in applications like ChatGPT. This provides immediate feedback and feels much more interactive.
FastAPI supports this natively with the StreamingResponse class. The process involves creating an asynchronous generator function that yields parts of the response as they become available. We can use a streamer object, like the TextIteratorStreamer from the Hugging Face Transformers News library, to get tokens from the model as they are generated in a separate thread, and then yield them from our async generator.
# main_streaming.py
import torch
import asyncio
from fastapi import FastAPI
from pydantic import BaseModel, Field
from starlette.responses import StreamingResponse
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer
from threading import Thread
# --- App, Models, and Model Loading (same as before) ---
app = FastAPI(title="Streaming LLM Inference API")
model_cache = {}
class TextGenerationRequest(BaseModel):
prompt: str = Field(..., min_length=10, max_length=512)
max_new_tokens: int = Field(default=256, gt=0, le=512)
@app.on_event("startup")
def load_model():
print("Loading model...")
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
model_cache.update({"tokenizer": tokenizer, "model": model, "device": device})
print("Model loaded.")
# --- Streaming Endpoint ---
async def text_generation_stream(prompt: str, max_new_tokens: int):
"""Asynchronous generator for streaming LLM output."""
tokenizer = model_cache["tokenizer"]
model = model_cache["model"]
device = model_cache["device"]
# Use TextIteratorStreamer for token-by-token streaming
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
inputs = tokenizer(prompt, return_tensors="pt").to(device)
generation_kwargs = dict(**inputs, streamer=streamer, max_new_tokens=max_new_tokens)
# Run model.generate in a separate thread
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
# Yield tokens as they become available
for new_text in streamer:
yield new_text
await asyncio.sleep(0.01) # Small sleep to prevent tight loop
@app.post("/stream-generate")
async def stream_generate(request: TextGenerationRequest):
"""
Endpoint to generate text with a streaming response.
"""
generator = text_generation_stream(request.prompt, request.max_new_tokens)
return StreamingResponse(generator, media_type="text/plain")Best Practices and Optimization
Deploying a model in production requires thinking beyond the API code. It involves optimizing performance, ensuring reliability, and integrating with the broader MLOps ecosystem.
Performance Optimization
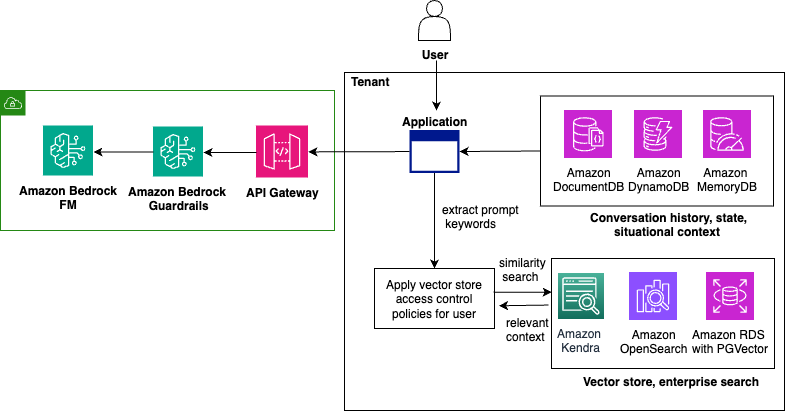
API architecture diagram – Build a multi-tenant generative AI environment for your enterprise …
To maximize throughput and minimize latency, consider these optimization strategies:
- Model Quantization: Techniques like 8-bit or 4-bit quantization significantly reduce the model’s memory footprint and can speed up inference, especially on consumer hardware. Libraries like
bitsandbytesmake this accessible. - Specialized Inference Engines: For high-throughput scenarios, generic PyTorch or TensorFlow runtimes may not be enough. Tools like NVIDIA’s Triton Inference Server News, TensorRT News, and open-source libraries like vLLM News are designed for optimized inference. FastAPI can act as a smart proxy or API gateway in front of these powerful backends.
- Dynamic Batching: Grouping multiple incoming requests into a single batch for processing on the GPU can dramatically improve hardware utilization. This is a complex pattern to implement manually but is a built-in feature of many dedicated inference servers.
MLOps and the Broader Ecosystem
A production API is part of a larger system. Integrating with MLOps tools is crucial for long-term maintainability.
- Experiment Tracking and Model Versioning: Tools like MLflow News or Weights & Biases News help track which model version is deployed.
- Monitoring and Observability: For LLMs, specialized tools are emerging. LangSmith News provides excellent tracing capabilities to debug complex chains and agent interactions.
- Containerization and Deployment: Package your FastAPI application and its dependencies into a Docker container for consistent, portable deployments. This container can then be deployed on cloud platforms like AWS SageMaker News, Azure Machine Learning News, or Google’s Vertex AI News, which handle scaling and infrastructure management.
Conclusion
FastAPI provides a modern, high-performance, and developer-friendly foundation for deploying custom Large Language Models. By leveraging its asynchronous capabilities, Pydantic-powered data validation, and easy integration with the Python AI ecosystem, you can build robust, production-ready APIs that are both scalable and easy to maintain. We’ve journeyed from a basic endpoint to an advanced, streaming implementation, demonstrating how FastAPI addresses the unique challenges of serving LLMs.
The key takeaways are clear: load models at startup, use thread pools for blocking inference calls to keep the server responsive, and implement streaming for a superior user experience. As you move to production, remember to explore the rich ecosystem of optimization tools like vLLM News and MLOps platforms like MLflow News. With FastAPI as your API layer, you are well-equipped to turn your custom-trained models into powerful, accessible, and valuable applications.


