
FAISS: A Deep Dive into High-Performance Vector Search for Modern AI
Introduction: The Engine Behind Modern Similarity Search
In the rapidly evolving landscape of artificial intelligence, the ability to efficiently search through vast, high-dimensional datasets has become a cornerstone technology. From powering recommendation engines and reverse image search to enabling the Retrieval-Augmented Generation (RAG) pipelines that enhance Large Language Models (LLMs), vector similarity search is the unsung hero. At the heart of this revolution is FAISS (Facebook AI Similarity Search), a library developed by Meta AI that provides unparalleled efficiency and flexibility for finding nearest neighbors in dense vector spaces. While many managed services like Pinecone News and Weaviate News have emerged, understanding the foundational power of a library like FAISS is crucial for any serious AI practitioner.
The core challenge FAISS addresses is the “curse of dimensionality.” As vectors representing data (like text, images, or audio) grow in dimension, calculating exact distances between all points becomes computationally prohibitive. FAISS brilliantly circumvents this by implementing Approximate Nearest Neighbor (ANN) search algorithms. It allows developers to make a calculated trade-off between search accuracy and speed, enabling queries over billions of vectors in milliseconds. This article provides a comprehensive technical guide to FAISS, exploring its core concepts, practical implementations, advanced techniques, and its vital role within the broader AI ecosystem, which includes updates from Meta AI News, Hugging Face News, and beyond.
Section 1: Core Concepts and Getting Started with FAISS
Before diving into complex indexing strategies, it’s essential to grasp the fundamental building blocks of FAISS. The entire library revolves around the concept of an `Index` object, which stores your vectors and provides methods for searching them.
Understanding Vector Embeddings and Search
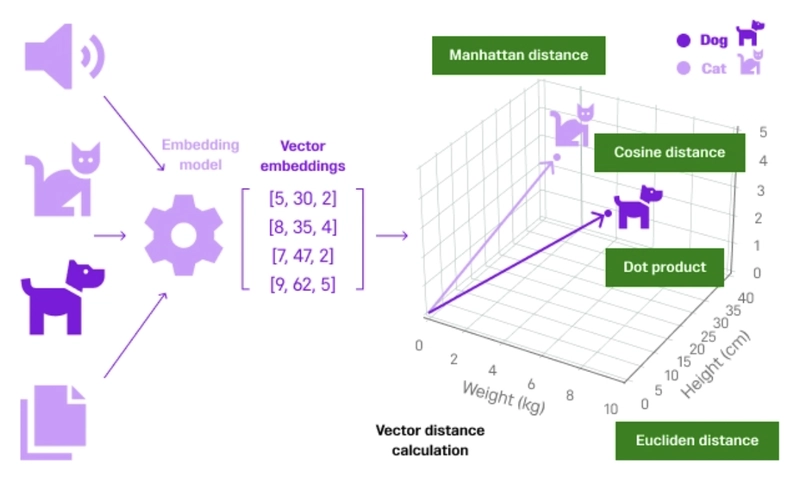
At its core, FAISS operates on numerical vectors, often called embeddings. These embeddings are generated by deep learning models, such as those developed using frameworks mentioned in PyTorch News or TensorFlow News, which convert complex data like text or images into a meaningful, high-dimensional numerical representation. For instance, the Sentence Transformers News library is a popular choice for creating high-quality text embeddings. The goal of similarity search is simple: given a query vector, find the vectors in your dataset that are “closest” to it, typically measured by L2 (Euclidean) distance or cosine similarity.
The Baseline: Exact Search with IndexFlatL2
The simplest index in FAISS is IndexFlatL2. It performs a brute-force, exhaustive search. For every query, it computes the L2 distance to every single vector in the index and returns the top-k closest ones. While this guarantees 100% accuracy, it’s also the slowest method and doesn’t scale to large datasets. However, it serves as an excellent baseline for understanding the API and for verifying the accuracy of more complex, approximate indexes.
Let’s see a practical example of creating a flat index, adding some data, and performing a search.
import numpy as np
import faiss
# 1. Set up the data
d = 64 # vector dimension
nb = 100000 # database size
nq = 1000 # number of queries
# Generate some random vectors for the database and queries
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000. # Add some structure
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000.
# 2. Build the index
index = faiss.IndexFlatL2(d)
print(f"Index is trained: {index.istrained}")
# 3. Add vectors to the index
index.add(xb)
print(f"Total vectors in index: {index.ntotal}")
# 4. Perform the search
k = 4 # We want to find the 4 nearest neighbors
D, I = index.search(xq, k) # D: distances, I: indices
# 5. Analyze results
print("Indices of nearest neighbors (first 5 queries):")
print(I[:5])
print("\\nDistances to nearest neighbors (first 5 queries):")
print(D[:5])In this example, we create a 64-dimensional index, populate it with 100,000 vectors, and then search for the 4 nearest neighbors for 1,000 query vectors. The output `I` contains the indices of the neighbors, and `D` contains the corresponding squared L2 distances.
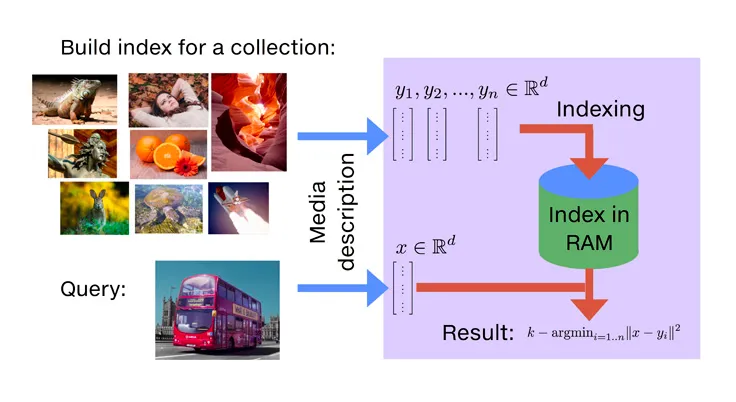
Section 2: Scaling Up with Partition-Based Indexing
Brute-force search quickly becomes impractical. To handle millions or billions of vectors, FAISS employs clever partitioning strategies. The most common is using Voronoi cells, implemented in indexes like `IndexIVFFlat`.
The Inverted File (IVF) Principle
The “IVF” in `IndexIVFFlat` stands for Inverted File. The core idea is to partition the vector space into `nlist` cells (or clusters). Each vector in the database is assigned to its nearest cell centroid. During a search, instead of comparing the query vector to all vectors, we first identify the closest cell centroids and then only search within those few cells. This dramatically reduces the number of distance calculations.
Training and the Speed/Accuracy Trade-off
Unlike `IndexFlatL2`, an IVF index requires a `train` step. During training, FAISS runs a k-Means clustering algorithm on a representative sample of the data to find the optimal positions for the `nlist` centroids. The key parameters to tune are:
nlist: The number of cells to partition the data into. A good starting point is `sqrt(N)` where N is the number of vectors.nprobe: The number of cells to visit during a search. A higher `nprobe` increases accuracy at the cost of speed. Setting `nprobe = nlist` makes the search exhaustive again.
Here’s how to implement an `IndexIVFFlat` index.
import numpy as np
import faiss
# Set up the data (same as before)
d = 64
nb = 100000
nq = 1000
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
# 1. Define the index structure
nlist = 100 # Number of Voronoi cells (clusters)
quantizer = faiss.IndexFlatL2(d) # The base index for cell centroids
index = faiss.IndexIVFFlat(quantizer, d, nlist)
# 2. Train the index
# FAISS needs a representative sample of vectors to learn the partitions
print(f"Training the index...")
index.train(xb)
print(f"Index is trained: {index.istrained}")
# 3. Add vectors to the index
index.add(xb)
print(f"Total vectors in index: {index.ntotal}")
# 4. Perform the search with nprobe
k = 4
index.nprobe = 10 # Visit 10 closest cells
D, I = index.search(xq, k)
# 5. Analyze results
print("Indices of nearest neighbors (first 5 queries):")
print(I[:5])By only searching within 10 of the 100 cells, this query will be roughly 10 times faster than the brute-force `IndexFlatL2` search, with a minimal loss in accuracy for most datasets.
Section 3: Advanced Techniques for Massive-Scale Datasets
For datasets scaling to billions of vectors or with strict memory constraints, even `IndexIVFFlat` can be insufficient. FAISS offers further optimization through vector compression, most notably Product Quantization (PQ).
Compressing Vectors with Product Quantization (PQ)
Product Quantization is a technique that compresses high-dimensional vectors into short codes, drastically reducing memory footprint and accelerating distance computations. It works by:
- Splitting each vector into `m` sub-vectors.
- Running a separate k-Means algorithm on each set of sub-vectors to create a small codebook (typically with 256 centroids, or `nbits=8`).
- Representing each sub-vector by the ID of its closest centroid in the codebook.
An original 128-dimensional float32 vector (512 bytes) can be compressed down to just 16 bytes using `m=16` and `nbits=8`. The `IndexIVFPQ` combines the IVF partitioning scheme with PQ compression on the stored vectors.
Using the Index Factory for Complex Indexes
Building complex indexes like `IndexIVFPQ` manually can be verbose. FAISS provides a powerful `index_factory` function that uses a string-based syntax to construct sophisticated index pipelines. This is the recommended way to create advanced indexes.
import numpy as np
import faiss
# Set up the data
d = 128 # A more realistic dimension for embeddings
nb = 200000
nq = 1000
np.random.seed(1234)
xb = np.random.random((nb, d)).astype('float32')
xq = np.random.random((nq, d)).astype('float32')
# 1. Use the index_factory to build a complex index
# IVF with 1024 cells, vectors compressed into 16 sub-quantizers of 8 bits each
nlist = 1024
m = 16 # Number of sub-quantizers
nbits = 8 # bits per sub-quantizer
index_key = f"IVF{nlist},PQ{m}x{nbits}"
index = faiss.index_factory(d, index_key)
print(f"Building index: {index_key}")
# 2. Train the index
print("Training...")
index.train(xb)
# 3. Add vectors
print("Adding vectors...")
index.add(xb)
print(f"Total vectors: {index.ntotal}")
# 4. Search
k = 5
index.nprobe = 16 # Search in 16 cells
D, I = index.search(xq, k)
print("\\nIndices of nearest neighbors (first 5 queries):")
print(I[:5])This `IVF1024,PQ16x8` index is incredibly memory-efficient and fast, making it suitable for billion-scale search. Other powerful index types like HNSW (Hierarchical Navigable Small World) are also available and offer excellent performance, especially for lower-latency requirements. The latest FAISS News often includes performance benchmarks and new combinations of these techniques.
Section 4: Best Practices, Optimization, and Ecosystem Integration
Building an effective FAISS-powered system goes beyond just writing the code. It involves strategic choices about index selection, parameter tuning, and integration with the broader AI and MLOps ecosystem.
Choosing the Right Index
- For small datasets (<1M vectors) or perfect accuracy: Use
IndexFlatL2. - For large datasets with a good balance of speed and accuracy: Start with
IndexIVFFlat. A good rule of thumb fornlistis between4*sqrt(N)and16*sqrt(N). - For very large datasets or memory constraints: Use
IndexIVFPQ. It offers the best memory compression. - For low-latency search where memory is less of a concern: Consider
IndexHNSWFlat, which often provides superior speed-accuracy trade-offs.
GPU Acceleration
One of FAISS’s killer features is its seamless GPU support, which is a major topic in NVIDIA AI News. You can accelerate training and searching by orders of magnitude by converting an index to a GPU resource. This is especially useful for batch processing or re-indexing large collections.
# Assuming 'index' is a CPU-based FAISS index
if faiss.get_num_gpus() > 0:
print("Moving index to GPU...")
res = faiss.StandardGpuResources() # Use a single GPU
gpu_index = faiss.index_cpu_to_gpu(res, 0, index) # Move to GPU 0
# Now, search operations on gpu_index will be much faster
# D, I = gpu_index.search(xq, k)
else:
print("No GPU found.")FAISS in the Modern AI Stack
FAISS is rarely used in isolation. It’s a foundational component in many modern AI systems:
- Retrieval-Augmented Generation (RAG): Frameworks like those highlighted in LangChain News and LlamaIndex News use FAISS as a vector store to retrieve relevant documents. These documents are then fed as context to LLMs from providers mentioned in OpenAI News, Anthropic News, or open-source models like Llama from Meta AI News and those from Mistral AI News.
- Vector Databases: While FAISS is a library, full-fledged vector databases like Milvus News, Chroma News, and Qdrant News often use FAISS as one of their core indexing engines, adding features like metadata filtering, scalability, and a database-like API on top.
- MLOps and Deployment: When building a production system, you’ll generate embeddings using models deployed on platforms like AWS SageMaker News, Google’s Vertex AI News, or Azure Machine Learning News. The FAISS index itself can be part of a larger application served via FastAPI News and deployed using tools like Triton Inference Server News for high-throughput inference. Experiment tracking for tuning FAISS parameters (like `nlist`, `nprobe`) can be managed with tools from Weights & Biases News or MLflow News.
Conclusion: The Enduring Relevance of FAISS
FAISS remains a cornerstone of high-performance similarity search, providing the speed, scalability, and granular control that production AI systems demand. By understanding its core components—from the simple `IndexFlatL2` to the highly optimized `IndexIVFPQ`—developers can build powerful search capabilities tailored to their specific needs. We’ve seen how to choose the right index, tune its parameters for the optimal speed-accuracy trade-off, and leverage GPU acceleration for massive performance gains.
As the AI world continues to be driven by advancements from Google DeepMind News and innovations in frameworks like JAX, the need for efficient vector search will only grow. Whether you are building a RAG system with the latest open-source models, creating a recommendation engine, or exploring novel applications of semantic search, mastering FAISS is a critical skill. It is the foundational library that empowers developers to turn billions of high-dimensional vectors from abstract data points into a searchable, intelligent, and responsive knowledge base.


