
Revolutionizing Gen AI Orchestration: A Deep Dive into Amazon Bedrock’s Inline Code Nodes
The landscape of generative AI is evolving at a breakneck pace. While foundational models from providers mentioned in Anthropic News and Meta AI News grab headlines, the real challenge for developers often lies in the orchestration layer—the complex web of logic that connects these powerful models to data sources, APIs, and user inputs. Building robust applications, especially those employing Retrieval-Augmented Generation (RAG), has traditionally required stitching together services with frameworks like LangChain or LlamaIndex, demanding significant boilerplate code and infrastructure management. However, recent Amazon Bedrock News highlights a significant step towards simplifying this process. Amazon Bedrock Flows, a visual tool for orchestrating generative AI workflows, has introduced a game-changing feature: inline code nodes. This powerful addition bridges the critical gap between low-code visual design and the limitless flexibility of custom Python code, allowing developers to inject bespoke logic directly into their AI applications without ever leaving the Bedrock console. This article provides a comprehensive technical deep dive into this new capability, exploring its core concepts, practical implementations, advanced techniques, and best practices for production-ready applications.
What Are Inline Code Nodes in Bedrock Flows?
Amazon Bedrock Flows provide a visual canvas to build multi-step generative AI applications. You can drag and drop nodes representing different actions—such as invoking a model, querying a knowledge base, or gathering user input—and connect them to define the application’s logic. While this is incredibly powerful for standard workflows, it historically lacked a simple way to perform custom data manipulation or integration tasks. Before, any logic that didn’t fit a pre-built node required creating, deploying, and managing a separate AWS Lambda function, adding complexity and slowing down development. The inline code node directly addresses this limitation.
Moving Beyond Pre-built Blocks
An inline code node is essentially a lightweight, serverless Python environment that lives directly within your Bedrock Flow. It executes a Python function you write in the console, receiving inputs from upstream nodes and passing its outputs to downstream nodes. This unlocks a new level of dynamism that was previously difficult to achieve in a purely visual builder.
Consider these common scenarios where pre-built nodes fall short:
- Data Transformation: You need to reformat a date, parse a complex string from a user, or sanitize input before sending it to an LLM.
- Dynamic Prompting: You want to construct a highly specific prompt by combining user input with data fetched from an internal database or the results of a previous model call.
- Custom API Integration: Your application needs to pull real-time data, like weather or financial information, from a third-party REST API.
- Post-processing Logic: You need to validate the structure of JSON generated by a model, extract specific entities, or format the final output for a user interface built with Streamlit or Gradio.
The inline code node provides a simple, integrated solution for all these cases. It runs a Python function with a predefined handler, similar to a standard AWS Lambda function, and comes pre-packaged with essential libraries like boto3 (for AWS SDK access) and requests (for HTTP calls).
A First Look: The Basic Structure
Every inline code node is built around a `lambda_handler` function. This function receives an `event` dictionary containing the inputs from the nodes connected to it. Your code processes these inputs and returns a dictionary, which then becomes the output of the node. Here is a foundational example that takes a name and a city from its input and generates a personalized greeting.
import json
def lambda_handler(event, context):
"""
Processes input from a Bedrock Flow and returns a formatted greeting.
Expected input format from the previous node:
{
"name": "Alex",
"city": "Seattle"
}
"""
# Extract inputs from the event object.
# The actual data is nested under the input name.
# Let's assume the input node is named 'user_details'.
try:
user_name = event['user_details']['name']
user_city = event['user_details']['city']
# Perform custom logic
greeting = f"Hello, {user_name} from {user_city}! Welcome to our custom Bedrock Flow."
# The output of this node must be a dictionary.
# This dictionary will be passed to the next node in the flow.
result = {
"greeting_message": greeting
}
except KeyError as e:
# Basic error handling
result = {
"error": f"Missing expected input: {str(e)}"
}
return resultImplementing Inline Code for Real-World Scenarios
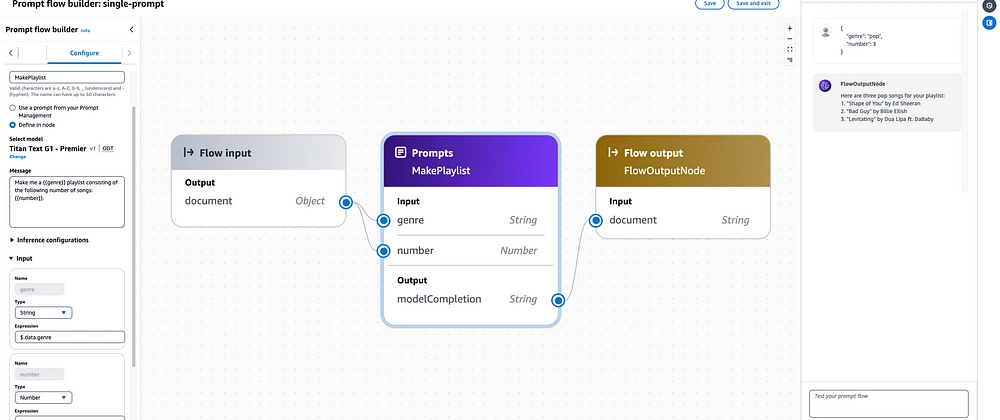
Let’s move beyond a simple greeting and explore a more practical, high-impact use case: enhancing a Retrieval-Augmented Generation (RAG) workflow. A common challenge in RAG systems built on vector databases like Pinecone, Milvus, or Weaviate is that raw user queries are often not optimized for semantic search. An inline code node can act as a powerful query transformation layer.
Pre-processing User Queries for Better Retrieval
Imagine a user asks a short, ambiguous question like “bedrock costs.” A semantic search on this phrase might pull up documents about geology instead of AWS pricing. We can use an inline code node to rephrase this into a more specific, descriptive question that is more likely to find relevant documents in our knowledge base. This technique is a cornerstone of advanced systems developed with tools from the latest LangChain News and is now easily achievable within Bedrock.
In our flow, the architecture would look like this: Input Node -> Inline Code Node (Query Transformer) -> Knowledge Base Node -> Model Node -> Output Node. The code node takes the raw query and enriches it.
import json
def lambda_handler(event, context):
"""
Transforms a concise user query into a more descriptive question
to improve retrieval accuracy from a knowledge base.
Expected input from a node named 'user_query':
{
"query": "bedrock costs"
}
"""
try:
raw_query = event['user_query']['query']
# Simple rule-based transformation logic.
# In a more advanced setup, you could even make a small LLM call here
# to perform the rephrasing (a "query rewriting" pattern).
# Example of adding context and framing it as a question
if "cost" in raw_query or "pricing" in raw_query:
transformed_query = f"What is the detailed pricing model for the {raw_query.replace('costs', '').strip()} service?"
elif "how to" in raw_query:
transformed_query = f"Provide a step-by-step guide on {raw_query}."
else:
# Default to a more general question format
transformed_query = f"Can you provide detailed information about {raw_query}?"
result = {
"enhanced_query": transformed_query
}
except KeyError:
result = {
"error": "Input 'query' not found in the event from 'user_query' node."
}
return resultThis `enhanced_query` is then fed into the Bedrock Knowledge Base node, which performs its vector search using this much-improved text. The quality of the retrieved context will be significantly higher, leading to a more accurate and relevant final answer from the LLM, whether it’s a model from Cohere, AI21 Labs, or one featured in recent Mistral AI News.
Unlocking Advanced Workflows with Custom Code
The true power of inline code nodes is realized when you use them to break out of the self-contained Bedrock ecosystem and interact with the outside world. This transforms your flow from a simple document Q&A bot into a dynamic, agent-like application capable of performing actions.
Calling External APIs for Real-Time Data Enrichment
Suppose you are building an AI financial assistant. A user might ask, “What is the current stock price for NVDA and what are the latest headlines about it?” Your knowledge base might have historical data, but it won’t have the real-time price. An inline code node can call an external financial data API to fetch this live information and inject it directly into the prompt for the LLM.
import json
import requests # This library is available in the inline code node runtime
import os
# Best practice: Store API keys in a secure way, e.g., AWS Secrets Manager
# For this example, we'll use an environment variable placeholder.
API_KEY = os.environ.get("FINANCIAL_API_KEY", "your_default_key")
API_ENDPOINT = "https://api.example-financial-data.com/v1/quote"
def lambda_handler(event, context):
"""
Fetches the latest stock price for a given ticker symbol from an external API.
Expected input from a node named 'ticker_input':
{
"ticker": "NVDA"
}
"""
try:
ticker = event['ticker_input']['ticker']
params = {
"symbol": ticker,
"apikey": API_KEY
}
# Make the external API call with a timeout
response = requests.get(API_ENDPOINT, params=params, timeout=5)
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
data = response.json()
price = data.get("price")
if price:
result = {
"ticker": ticker,
"current_price": price,
"status": "success"
}
else:
result = {
"ticker": ticker,
"error": "Price not found in API response.",
"status": "failed"
}
except requests.exceptions.RequestException as e:
result = {
"ticker": ticker,
"error": f"API request failed: {str(e)}",
"status": "failed"
}
except KeyError:
result = {
"error": "Input 'ticker' not found.",
"status": "failed"
}
return resultThe output of this node (e.g., `{“ticker”: “NVDA”, “current_price”: 905.25, “status”: “success”}`) can be combined with context from a knowledge base and passed to a model like Anthropic’s Claude 3 to generate a comprehensive answer. This pattern is fundamental to building agents and is a key topic in the broader AI landscape, often covered in OpenAI News and Google DeepMind News.
Dynamic Routing with Conditional Logic
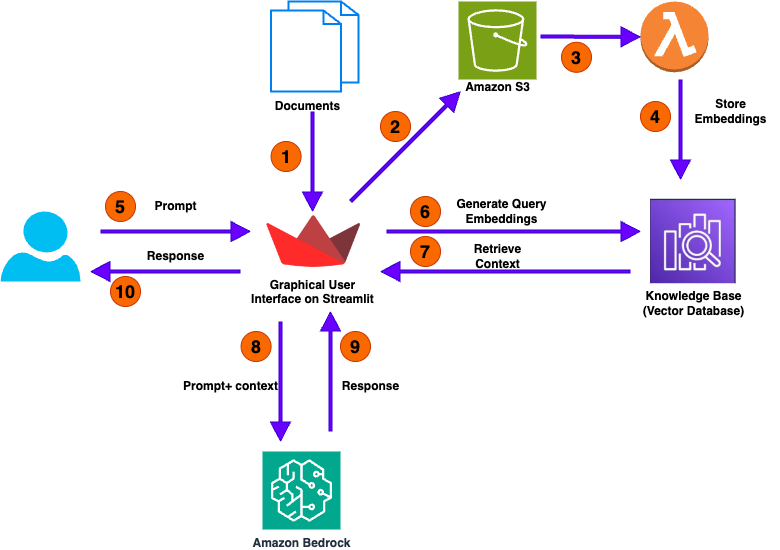
More complex applications require routing logic. Imagine a customer service bot that needs to handle queries about billing, technical support, or sales. Each of these topics might be best served by a different knowledge base or a different specialized LLM. An inline code node can act as a central router.
The node can analyze the user’s query for keywords and output a routing decision. This output can then be connected to a “Condition” node in Bedrock Flows, which directs the workflow down the appropriate path. This mirrors the functionality of “Router Chains” in frameworks like LangChain but is implemented visually.
import json
def lambda_handler(event, context):
"""
Analyzes a user query and determines the appropriate path for processing.
Expected input from a node named 'initial_query':
{
"query": "I can't log in to my account."
}
"""
query = event['initial_query']['query'].lower()
# Simple keyword-based routing logic
if any(keyword in query for keyword in ["billing", "invoice", "price", "cost"]):
route = "SALES_KB"
elif any(keyword in query for keyword in ["error", "can't log in", "broken", "bug"]):
route = "TECH_SUPPORT_KB"
else:
route = "GENERAL_KB"
return {
"routing_decision": route,
"original_query": query
}From Prototype to Production: Best Practices and Optimization
While inline code nodes are incredibly versatile, using them effectively in production requires adhering to best practices for performance, security, and maintainability.
Know When to Use a Full Lambda Function
Inline code nodes are perfect for short, self-contained logic. However, if your code becomes very complex, requires external Python libraries not included in the runtime (e.g., NumPy, Pandas), or needs to be reused across multiple flows, you should use a dedicated AWS Lambda function node instead. The inline environment is not designed for heavy compute tasks that would be better suited for frameworks like PyTorch or TensorFlow running on a service like AWS SageMaker or an environment managed by Ray.
Security and Secrets Management
Never hardcode sensitive information like API keys, database credentials, or other secrets directly in your inline code. This is a major security risk. The correct approach is to store these secrets in AWS Secrets Manager and use the provided `boto3` library to fetch them at runtime. This ensures your code remains secure and portable.
Robust Error Handling and Logging
Your code will inevitably encounter errors—API endpoints might be down, or inputs might be malformed. Wrap your logic in `try…except` blocks to gracefully handle these failures. A well-designed node should return a clear error message in its output, which can be used by downstream nodes to inform the user or trigger a fallback action. Use `print()` statements within your code for debugging; these logs are automatically sent to Amazon CloudWatch, allowing you to monitor execution and troubleshoot issues, a practice similar to using tools like LangSmith or Weights & Biases for observability.
import json
import requests
import boto3 # Use boto3 to fetch secrets
def get_secret(secret_name):
"""Fetches a secret from AWS Secrets Manager."""
client = boto3.client('secretsmanager')
try:
response = client.get_secret_value(SecretId=secret_name)
return response['SecretString']
except Exception as e:
print(f"Error fetching secret: {e}")
raise e
def lambda_handler(event, context):
"""
A more robust version of the API calling node with error handling and secrets management.
"""
try:
# Fetch API key securely
api_key = get_secret("my_financial_api_key_secret")
ticker = event['ticker_input']['ticker']
# ... (rest of the API call logic with try...except for requests)
response = requests.get(..., timeout=5)
response.raise_for_status()
# ... process response ...
result = {"status": "success", "data": ...}
except Exception as e:
# Catch-all for any unexpected errors
print(f"An error occurred: {str(e)}")
result = {
"status": "failed",
"error": "An internal error occurred. Please try again later."
}
return resultConclusion: The Future of AI Application Development
The introduction of inline code nodes in Amazon Bedrock Flows is more than just an incremental update; it represents a fundamental shift in how developers can build and orchestrate generative AI applications. By seamlessly blending a visual, low-code interface with the power of custom Python, AWS is democratizing the creation of sophisticated, agent-like systems. This feature drastically reduces development time, eliminates the need for managing separate serverless functions for simple tasks, and empowers developers to integrate real-time data and custom logic with unprecedented ease. As the AI ecosystem continues to mature, we see a similar trend across platforms, with related developments in Azure AI News and Vertex AI News. The future belongs to hybrid development environments that offer both high-level abstractions and low-level control. We encourage you to explore this new capability in your own projects, experiment with custom data processing and API integrations, and discover how it can accelerate your journey from prototype to a production-grade generative AI application.


