
RunPod Supercharges AI Inference with vLLM: A Deep Dive into High-Throughput LLM Serving
The landscape of artificial intelligence is defined by a relentless pursuit of performance. As Large Language Models (LLMs) grow in size and capability, the computational cost and complexity of serving them for real-time inference have become a primary bottleneck for developers and businesses. Announcing a significant development in this space, recent RunPod News highlights a powerful integration with vLLM, a state-of-the-art LLM inference and serving engine. This collaboration is set to redefine the standards for speed, efficiency, and cost-effectiveness in deploying AI models, marking a pivotal moment for anyone working with technologies from Hugging Face, Meta AI, or Mistral AI.
Traditionally, serving LLMs has been a trade-off between latency, throughput, and cost. Naive batching methods often lead to underutilized GPU resources, while complex memory management for the key-value (KV) cache results in fragmentation and performance degradation. vLLM directly addresses these challenges with its groundbreaking PagedAttention algorithm. By pairing this software innovation with RunPod’s robust and affordable GPU cloud infrastructure, developers now have a streamlined path to deploying highly optimized inference endpoints that can handle massive concurrent requests without breaking the bank. This article provides a comprehensive technical guide to understanding, implementing, and optimizing vLLM on the RunPod platform.
Understanding the Core Innovation: vLLM and PagedAttention
To appreciate the significance of the vLLM integration, it’s crucial to understand the fundamental problem it solves: memory management in LLM inference. This is a topic of constant discussion in the latest PyTorch News and NVIDIA AI News, as GPU memory is often the most critical limiting factor.
The LLM Inference Bottleneck: The KV Cache
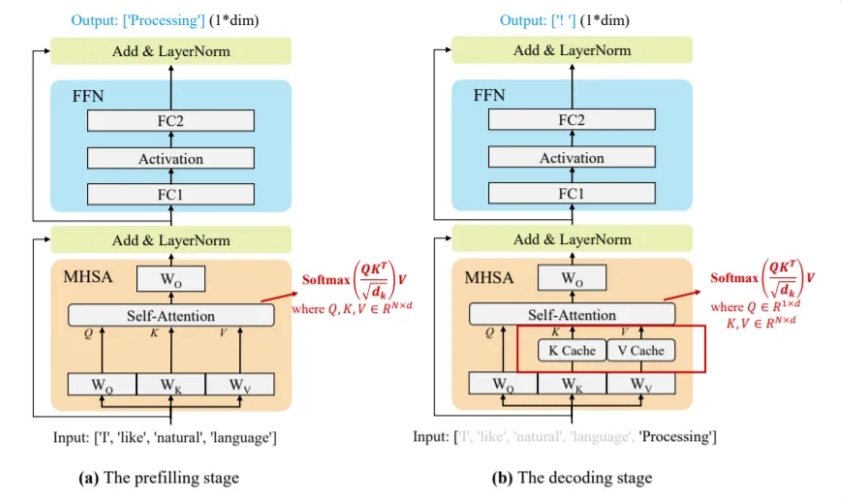
When an LLM generates text, it performs a process called autoregression. For each new token it produces, it must attend to all the previous tokens in the sequence. To avoid re-computing this attention information for the entire sequence at every step, the intermediate states—known as keys and values—are stored in a GPU memory buffer called the KV cache.
The size of this KV cache is dynamic and unpredictable. It depends on the sequence length of every request being processed. In a standard serving environment, like one you might build with a basic Flask or FastAPI server, memory for the entire maximum possible sequence length is often pre-allocated for each request. This leads to two major problems:
- Internal Fragmentation: If a request has a short sequence, a large portion of its pre-allocated memory block goes unused.
- External Fragmentation: Over time, as requests of varying sizes come and go, the contiguous memory space becomes broken up, making it impossible to fit new requests even if the total free memory is sufficient.
This inefficiency severely limits the number of requests that can be processed concurrently (the batch size), leading to low GPU utilization and high operational costs. This is a challenge that even advanced serving solutions like Triton Inference Server have worked to optimize.
vLLM’s Solution: PagedAttention
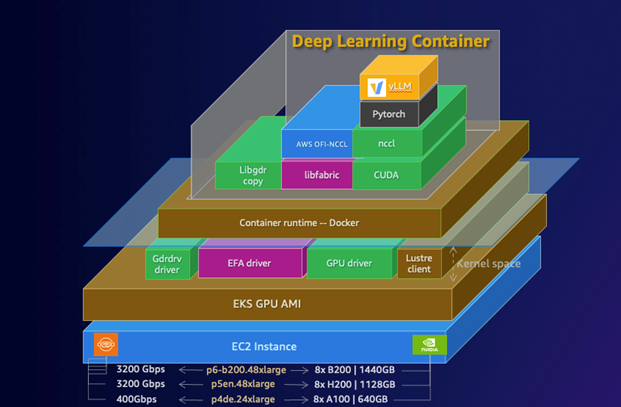
Inspired by virtual memory and paging in traditional operating systems, vLLM introduces PagedAttention. Instead of allocating a single, contiguous block of memory for each sequence, vLLM partitions the KV cache for every sequence into smaller, non-contiguous blocks (pages). This elegant solution allows for much more flexible and efficient memory management.
- Near-Zero Fragmentation: Since blocks are small and uniform, there is virtually no wasted memory, allowing the system to pack more requests onto the GPU.
- Efficient Memory Sharing: For complex decoding strategies like parallel sampling or beam search, where multiple candidate output sequences share a common prefix, PagedAttention allows these sequences to share the memory blocks for that common prefix, drastically reducing the memory footprint.
This core innovation enables vLLM to achieve significantly higher throughput—often 2x to 4x higher than standard Hugging Face Transformers implementations—making it a game-changer for production-grade LLM serving. Here is a basic example of how you might use the vLLM library in a Python script.
# main.py: A simple script to demonstrate vLLM's core API
from vllm import LLM, SamplingParams
# A list of prompts to process in a batch
prompts = [
"The best way to learn about AI is",
"San Francisco is a city known for",
"What is the capital of France?",
"Write a short story about a robot who discovers music.",
]
# Define the sampling parameters for generation
# These control the creativity and determinism of the output
sampling_params = SamplingParams(temperature=0.7, top_p=0.95, max_tokens=100)
# Initialize the LLM engine with a model from the Hugging Face Hub
# This could be a model from Mistral AI, Meta AI (Llama), etc.
# vLLM will automatically download the model if not cached.
print("Loading the LLM model...")
llm = LLM(model="mistralai/Mistral-7B-Instruct-v0.1")
print("Model loaded successfully.")
# Run the inference on the batch of prompts
print("Generating outputs...")
outputs = llm.generate(prompts, sampling_params)
print("Generation complete.")
# Print the generated text for each prompt
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"---")
print(f"Prompt: {prompt!r}")
print(f"Generated: {generated_text!r}")Deploying a vLLM Endpoint on RunPod Serverless
RunPod’s Serverless platform is an ideal environment for deploying vLLM. It provides auto-scaling, pay-per-second billing, and access to a wide range of high-performance GPUs. By containerizing our vLLM application, we can create a scalable and cost-effective inference API. This approach is becoming a standard practice, with similar platforms like Modal and Replicate also gaining traction.
Step 1: Create the Worker Handler
The RunPod Serverless environment works by invoking a handler function in your code for each incoming request. We need to create a Python script that initializes the vLLM engine once at startup and then uses it to process inference jobs.
# handler.py: The worker script for a RunPod Serverless endpoint
import runpod
from vllm import LLM, SamplingParams
# Initialize the LLM engine globally on worker start
# This ensures the model is loaded into GPU memory only once.
llm = LLM(model="mistralai/Mistral-7B-Instruct-v0.1", trust_remote_code=True)
def handler(job):
"""
The handler function that will be called by the RunPod serverless worker.
"""
job_input = job['input']
# Validate and extract prompts from the job input
if 'prompts' not in job_input:
return {"error": "Missing 'prompts' in input"}
prompts = job_input['prompts']
# Extract sampling parameters or use defaults
# This allows users to customize generation per API call
temperature = job_input.get('temperature', 0.7)
top_p = job_input.get('top_p', 0.95)
max_tokens = job_input.get('max_tokens', 256)
sampling_params = SamplingParams(
temperature=temperature,
top_p=top_p,
max_tokens=max_tokens
)
# Run inference and generate outputs
outputs = llm.generate(prompts, sampling_params)
# Format the results to be returned as JSON
results = []
for output in outputs:
results.append({
"prompt": output.prompt,
"text": output.outputs[0].text
})
return {"results": results}
# Start the RunPod serverless worker
runpod.serverless.start({"handler": handler})Step 2: Define the Docker Environment
Next, we need a `Dockerfile` to package our application and its dependencies. This file tells RunPod how to build the container image that will run our worker. It specifies the base image (which should include CUDA and PyTorch), copies our code, and installs the necessary Python packages like `runpod` and `vllm`.
# Use the official RunPod PyTorch image as a base
FROM runpod/pytorch:2.1.0-cuda12.1.1-devel-ubuntu22.04
# Set the working directory inside the container
WORKDIR /app
# Install system dependencies if needed (e.g., git)
RUN apt-get update && apt-get install -y git
# Install Python dependencies
# We install vllm directly from pip.
# Ensure versions are compatible with the CUDA version in the base image.
RUN pip install --upgrade pip
RUN pip install runpod vllm==0.2.6
# Copy the handler script into the container
COPY handler.py .
# Command to run the worker when the container starts
CMD ["python", "-u", "handler.py"]With these two files, you can create a new Serverless Endpoint in the RunPod dashboard. You’ll point it to your code repository, and RunPod will automatically build the Docker image and deploy it. Once active, you’ll have a highly performant API endpoint ready to serve inference requests at scale.
Advanced Techniques and Real-World Applications
Beyond basic batch inference, the combination of vLLM and RunPod unlocks more sophisticated applications. As seen in the latest LangChain News and LlamaIndex News, building responsive and complex AI systems requires advanced serving capabilities.
Implementing Streaming for Conversational AI
For chatbots and other interactive applications, waiting for the full response to be generated can lead to a poor user experience. Streaming tokens back to the client as they are generated is essential. vLLM natively supports this, and we can adapt our RunPod handler to leverage it.
A streaming handler would use a generator function to yield results back to the RunPod infrastructure, which then streams them to the client. This is crucial for building applications with front-end frameworks like Streamlit, Gradio, or Chainlit.
# handler_streaming.py: A modified handler for streaming responses
import runpod
import time
from vllm import LLM, SamplingParams, AsyncLLMEngine
from vllm.engine.arg_utils import AsyncEngineArgs
# Use the Async engine for efficient streaming
engine_args = AsyncEngineArgs(model="mistralai/Mistral-7B-Instruct-v0.1")
engine = AsyncLLMEngine.from_engine_args(engine_args)
async def handler_streaming(job):
"""
A streaming handler for RunPod Serverless.
"""
job_input = job['input']
prompt = job_input.get('prompt')
if not prompt:
yield {"error": "Missing 'prompt' in input"}
return
sampling_params = SamplingParams(
temperature=job_input.get('temperature', 0.7),
top_p=job_input.get('top_p', 0.95),
max_tokens=job_input.get('max_tokens', 1024)
)
request_id = f"rp-{int(time.time())}"
results_generator = engine.generate(prompt, sampling_params, request_id)
# Stream tokens as they are generated
async for request_output in results_generator:
# For simplicity, we yield the new text chunk
# In a real app, you might send just the delta
yield {"text": request_output.outputs[0].text}
# Start the worker with the async handler
runpod.serverless.start({"handler": handler_streaming})Integration with RAG Pipelines
The high-throughput endpoint you create on RunPod is a perfect component for a Retrieval-Augmented Generation (RAG) system. Frameworks like LangChain or LlamaIndex can orchestrate the process: a user query is first used to retrieve relevant documents from a vector database (such as those featured in Pinecone News or Milvus News), and then these documents are passed along with the original query as context to your vLLM endpoint. The speed of vLLM ensures that the generation step does not become a bottleneck in the overall RAG pipeline, enabling fast and contextually-aware responses.
Best Practices and Optimization
To get the most out of your RunPod and vLLM deployment, consider the following best practices, which are often discussed in forums related to AWS SageMaker and Azure Machine Learning.
- GPU Selection: Choose the right GPU for your model. Larger models (70B+) will require high-memory GPUs like the A100 80GB or H100. For smaller models (7B-13B), more cost-effective GPUs like the L40S or RTX A6000 can provide an excellent price-to-performance ratio.
- Quantization: vLLM supports various quantization techniques like AWQ and GPTQ. Using a quantized model can significantly reduce the memory footprint, allowing you to run larger models on smaller GPUs or achieve even higher batch sizes, further reducing costs.
- Cold Start Management: In a serverless environment, cold starts can introduce latency. You can mitigate this on RunPod by setting a minimum number of active workers. This keeps a certain number of GPUs “warm” and ready to process requests instantly, which is critical for latency-sensitive applications.
- Monitoring: Keep a close eye on your endpoint’s metrics in the RunPod dashboard. Monitor GPU utilization, memory usage, and request throughput. If your GPU utilization is consistently low, it may indicate that your batch sizes are too small or that the workload is not high enough to benefit from a powerful GPU. Tools like Weights & Biases or Comet ML can be used for more in-depth performance logging and experiment tracking.
Conclusion: The Future of Scalable AI Inference
The strategic integration of vLLM into the RunPod ecosystem represents a significant leap forward for the AI community. By democratizing access to high-throughput, low-cost LLM inference, this partnership empowers developers, startups, and enterprises to build and deploy the next generation of AI applications without the prohibitive costs and engineering overheads of the past. The combination of vLLM’s PagedAttention algorithm and RunPod’s scalable, on-demand GPU infrastructure creates a powerful synergy that directly addresses the most pressing challenges in production AI.
As we see in ongoing OpenAI News and Google DeepMind News, the frontier of AI continues to expand at an incredible pace. The tools and platforms that make these powerful models accessible and practical are just as important as the models themselves. The latest RunPod News confirms its position as a critical enabler in this ecosystem. For developers looking to serve LLMs efficiently, exploring the vLLM integration on RunPod is no longer just an option—it is a strategic imperative for building scalable, responsive, and economically viable AI products.


