
Unlocking Scalable AI: PyTorch and Kubeflow Trainer Join Forces on Kubernetes
The machine learning landscape is in a constant state of flux, with groundbreaking developments announced almost daily. Keeping track of the latest PyTorch News, TensorFlow News, and innovations from labs like Google DeepMind News and Meta AI News is a full-time job. However, some updates have a more profound, practical impact on the day-to-day work of ML engineers than others. One such development is the official integration of the Kubeflow Trainer (specifically, the PyTorchJob operator) into the PyTorch Ecosystem. This move signals a significant step towards standardizing and simplifying the process of training large-scale PyTorch models on Kubernetes.
For years, scaling machine learning from a single GPU in a notebook to a distributed cluster has been a major MLOps challenge. While tools like Ray News and Dask News have offered powerful solutions, deploying them effectively requires significant infrastructure expertise. The new integration provides a Kubernetes-native, declarative approach to distributed PyTorch training, making it more accessible, reproducible, and manageable. This article provides a comprehensive technical deep dive into this powerful combination, exploring core concepts, practical implementation, advanced techniques, and best practices for leveraging PyTorch and Kubeflow on your Kubernetes clusters.
Understanding the Core Components: PyTorch, Kubernetes, and Kubeflow
Before diving into the implementation, it’s crucial to understand the three pillars of this integration: PyTorch’s distributed capabilities, the container orchestration power of Kubernetes, and the ML-specific extensions provided by Kubeflow.
PyTorch’s Distributed Training API
PyTorch has built-in support for distributed training through its torch.distributed package. The most common strategy is Distributed Data Parallel (DDP), where the model is replicated on each worker process, and each process is fed a different slice of the input data. During the backward pass, gradients are calculated locally and then synchronized and averaged across all processes before the model weights are updated. This ensures all model replicas remain identical.
To coordinate this, each process needs to know its role. This is managed through environment variables like WORLD_SIZE (total number of processes), RANK (unique ID of the current process), and MASTER_ADDR/MASTER_PORT (the address of the rank 0 process for initial handshaking). The Kubeflow PyTorchJob operator automates the injection of these variables, which is a major part of its value.
import os
import torch
import torch.distributed as dist
import torch.nn as nn
from torch.nn.parallel import DistributedDataParallel as DDP
def setup_distributed():
"""Initializes the distributed process group."""
dist.init_process_group(backend="nccl") # 'nccl' is recommended for NVIDIA GPUs
# The master address and port are set by the Kubeflow operator
print(f"Initialized process group with rank {dist.get_rank()} and world size {dist.get_world_size()}")
def cleanup_distributed():
"""Cleans up the distributed process group."""
dist.destroy_process_group()
def main():
setup_distributed()
# Get local rank from environment variables for device placement
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
device = torch.device("cuda", local_rank)
# Create a simple model and move it to the GPU
model = nn.Linear(10, 10).to(device)
# Wrap the model with DistributedDataParallel
ddp_model = DDP(model, device_ids=[local_rank])
print(f"Rank {dist.get_rank()} has initialized DDP model on device {device}.")
# --- Your training loop would go here ---
# optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.001)
# for epoch in range(num_epochs):
# # ... load data, forward pass, backward pass, optimizer.step()
# pass
# ----------------------------------------
cleanup_distributed()
if __name__ == "__main__":
main()Kubernetes and Kubeflow: The MLOps Foundation
Kubernetes has become the de facto standard for container orchestration. It provides a robust platform for deploying, scaling, and managing containerized applications. However, its generic nature means it lacks specific constructs for ML workloads. This is where Kubeflow comes in.
Kubeflow is an open-source ML toolkit for Kubernetes. It aims to make ML workflows on Kubernetes simple, portable, and scalable. It achieves this by providing Custom Resource Definitions (CRDs) for common ML tasks. The PyTorchJob CRD is one such resource, designed specifically to manage the lifecycle of a distributed PyTorch training job.
Implementing a Distributed Training Job with the PyTorchJob Operator
With the conceptual groundwork laid, let’s walk through the practical steps of defining and launching a distributed training job. The central piece of this process is the PyTorchJob YAML manifest.
Crafting the PyTorchJob Manifest

The PyTorchJob manifest is a declarative file that tells Kubernetes and the Kubeflow operator what you want to run. It specifies the number of workers, the container image to use, the commands to execute, and the resources required.
A typical manifest has two main parts under pytorchReplicaSpecs:
- Master: A single replica (
replicas: 1) that is designated asrank 0. It’s responsible for coordinating the initial setup and often handles tasks like checkpointing or logging. - Worker: One or more replicas that perform the bulk of the computation. The operator assigns them ranks from 1 to N-1.
Here is a complete example of a PyTorchJob manifest. This file defines a job with one master and three workers, for a total of four parallel processes (WORLD_SIZE=4).
apiVersion: "kubeflow.org/v1"
kind: "PyTorchJob"
metadata:
name: "pytorch-distributed-cifar10"
namespace: "kubeflow-user"
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: OnFailure
template:
spec:
containers:
- name: pytorch
image: your-docker-registry/pytorch-distributed-trainer:v1.0
args:
- "--epochs=10"
- "--learning-rate=0.01"
resources:
limits:
nvidia.com/gpu: 1
Worker:
replicas: 3
restartPolicy: OnFailure
template:
spec:
containers:
- name: pytorch
image: your-docker-registry/pytorch-distributed-trainer:v1.0
args:
- "--epochs=10"
- "--learning-rate=0.01"
resources:
limits:
nvidia.com/gpu: 1To launch this job, you first need a container image (e.g., your-docker-registry/pytorch-distributed-trainer:v1.0) that contains your Python training script and all its dependencies. Once you have built and pushed the image, you can apply the manifest to your cluster using kubectl:
# Apply the YAML manifest to the cluster
kubectl apply -f pytorchjob.yaml -n kubeflow-user
# Check the status of the PyTorchJob
kubectl get pytorchjob pytorch-distributed-cifar10 -n kubeflow-user
# Check the underlying pods that were created
kubectl get pods -l training.kubeflow.org/job-name=pytorch-distributed-cifar10 -n kubeflow-userThe operator will then create the necessary Pods, Services, and automatically inject the environment variables (MASTER_ADDR, MASTER_PORT, WORLD_SIZE, RANK) into each container, allowing the torch.distributed.init_process_group function to work seamlessly.
Advanced Techniques and MLOps Integration
Beyond basic training jobs, the Kubeflow integration enables more sophisticated MLOps workflows. This is where you can connect your training to the broader ecosystem of tools mentioned in MLflow News or Weights & Biases News.
Hyperparameter Tuning and Experiment Tracking
You can integrate hyperparameter optimization tools like Optuna or frameworks from the AutoML News space. The tuning framework would programmatically generate and apply multiple PyTorchJob manifests, each with different command-line arguments (e.g., learning rate, batch size).
To track these experiments, you can modify your training script to log metrics to a centralized platform. This is essential for comparing runs and selecting the best model. Integrating a tool like Weights & Biases is straightforward.
import wandb
import os
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# ... (setup_distributed and other functions) ...
def training_loop(ddp_model, train_loader):
# Initialize W&B only on the master process (rank 0)
if dist.get_rank() == 0:
wandb.init(
project="kubeflow-pytorch-demo",
config={
"learning_rate": 0.01,
"epochs": 10,
"world_size": dist.get_world_size(),
}
)
optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.01)
for epoch in range(10):
# ... training logic ...
loss = ... # calculate loss
# Log metrics only from the master process
if dist.get_rank() == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
wandb.log({"loss": loss.item(), "epoch": epoch})
if dist.get_rank() == 0:
wandb.finish()
# ... (main function to call the training_loop) ...This ensures that metrics are logged only once per step/epoch, avoiding redundant data and potential race conditions. This simple addition transforms a standalone training job into a trackable component of a larger MLOps strategy, similar to what you would expect from managed platforms like AWS SageMaker or Vertex AI.
Gang Scheduling for All-or-Nothing Execution
A common pitfall in distributed training is when only some of the required pods can be scheduled due to resource constraints. The job might start but will hang indefinitely because not all workers are present. To prevent this, you can use a “gang scheduler” like the one provided by the Volcano project. This ensures that a job is only started once all of its required resources (e.g., 4 GPUs) are simultaneously available, preventing resource deadlocks. You can enable this by adding a scheduler name to your pod templates in the YAML file.
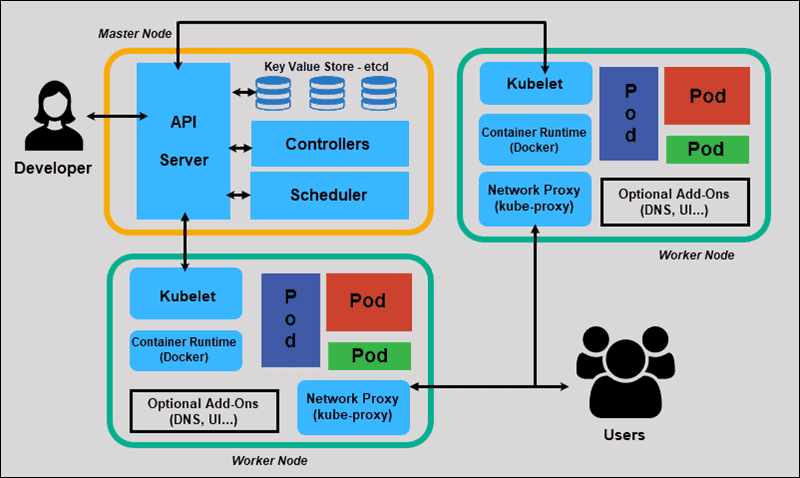
Best Practices and Optimization
To move from experimentation to production, consider the following best practices for running PyTorch on Kubernetes.
1. Optimize Your Docker Images
Large Docker images slow down pod startup times, especially on large clusters. Use multi-stage builds to create a lean final image. Start with a build stage to install dependencies, then copy only the necessary artifacts (your code, Python packages) into a minimal base image like nvidia/pytorch:2.1.0-cuda11.8-runtime.
2. Manage Data Efficiently
Getting data to your training pods is critical. For small datasets, you can bake them into the Docker image, but this is not scalable. For larger datasets, use Kubernetes Persistent Volumes (PVs) backed by network storage (like NFS, S3 via FUSE, or a cloud provider’s block storage). This allows multiple pods to access the same shared dataset without duplicating it.
3. Set Resource Requests and Limits
Always specify CPU, memory, and GPU requests and limits in your PyTorchJob manifest. This allows the Kubernetes scheduler to make intelligent decisions about where to place your pods and ensures your training jobs don’t consume more resources than allocated, which is crucial for maintaining cluster stability.
4. Implement Robust Logging and Monitoring
Configure your training script to output structured logs (e.g., JSON). This makes them easily parsable by cluster-level logging solutions like the EFK (Elasticsearch, Fluentd, Kibana) stack. Monitor GPU utilization and memory with tools like the DCGM Exporter for Prometheus to detect performance bottlenecks or underutilized resources.
5. Plan for Model Serving
Training is only half the battle. Once your model is trained and saved, you need a strategy for serving it. You can leverage tools like Triton Inference Server, which is designed for high-performance inference and can be easily deployed on Kubernetes. For modern LLMs, frameworks highlighted in vLLM News and deployment platforms like Modal or Replicate offer specialized solutions that can also be adapted to run on a private Kubernetes cluster.
Conclusion: A New Era for Scalable PyTorch
The official inclusion of the Kubeflow Trainer in the PyTorch ecosystem is more than just a minor update; it’s a powerful endorsement of a standardized, cloud-native approach to MLOps. This integration significantly lowers the barrier to entry for scaling PyTorch workloads, empowering teams to move from single-node experiments to multi-node distributed training with confidence and ease.
By combining the flexibility of PyTorch, the scalability of Kubernetes, and the ML-native abstractions of Kubeflow, developers now have a first-class, open-source toolkit for building production-grade training pipelines. As the AI world continues to evolve with trends from OpenAI News, Hugging Face Transformers News, and beyond, having a robust and scalable foundation for training is no longer a luxury but a necessity. This collaboration ensures that the PyTorch community is well-equipped to tackle the next generation of AI challenges.


