
Chroma News: Architecting a Real-Time, Semantically Aware News Platform with Vector Databases
In today’s hyper-connected world, we are inundated with a constant stream of information. The traditional news cycle has been replaced by a 24/7 firehose of articles, reports, and social media updates. For both consumers and analysts, navigating this deluge to find relevant, nuanced, and timely information is a monumental challenge. Keyword-based search, the long-standing paradigm for information retrieval, often falls short, failing to grasp the context, sentiment, and semantic relationships between topics. This is where the next generation of AI-powered information systems comes into play, fundamentally changing how we interact with news.
This article explores the architecture of a modern, AI-native news aggregation and analysis platform, which we’ll call “Chroma News.” We will perform a technical deep dive into how such a system can be built from the ground up, leveraging the power of large language models (LLMs), vector embeddings, and specialized vector databases like ChromaDB. We’ll move from core concepts to practical implementation, advanced features like Retrieval-Augmented Generation (RAG), and the MLOps best practices required to run such a system at scale. This blueprint isn’t just theoretical; it’s a guide to building applications that can understand and reason about vast quantities of unstructured text, a challenge at the heart of the latest developments from labs like Google DeepMind News and Meta AI News.
The Core Architecture: From Unstructured News to Vector Embeddings
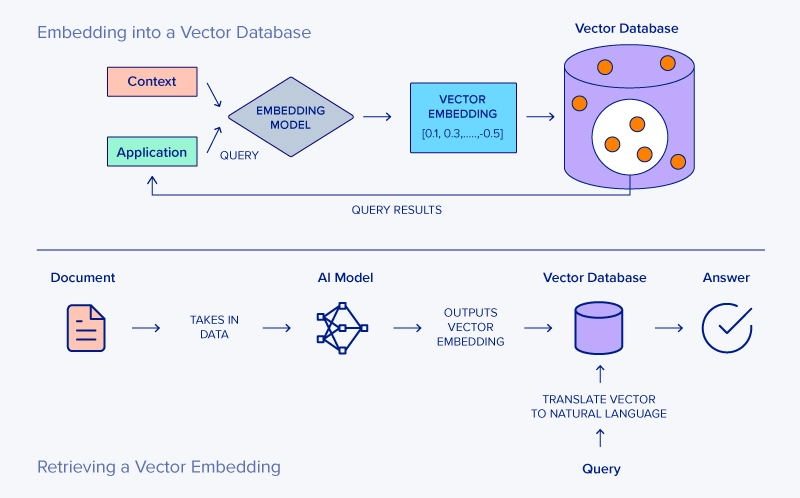
The foundational principle of any modern AI information system is the transformation of unstructured data—in this case, news articles—into a structured, machine-readable format. This process goes beyond simple keyword extraction; it aims to capture the underlying semantic meaning of the text. This is achieved through vector embeddings.
The Power of Embeddings
An embedding is a dense vector of floating-point numbers that represents a piece of text in a high-dimensional space. The magic of these vectors, generated by deep learning models, is that their proximity to one another in this vector space corresponds to their semantic similarity. For example, the headlines “NVIDIA Unveils New AI Chip” and “GPU Manufacturer Announces Next-Gen Silicon” would be mapped to vectors that are very close together, even though they share few common keywords. This allows for a much more intuitive and powerful form of search.
Creating these embeddings requires a sophisticated model. The open-source community, fueled by updates from Hugging Face Transformers News, provides a wealth of options, with the Sentence Transformers library being a popular choice. Alternatively, commercial APIs from providers covered in OpenAI News (e.g., text-embedding-3-large) or Cohere News offer state-of-the-art performance.
Introducing ChromaDB for Vector Storage
Once you have these vector embeddings, you need a specialized database to store and query them efficiently. A traditional relational database is not designed for finding the “nearest” vectors to a given query vector. This is where vector databases excel. They are purpose-built to perform highly efficient Approximate Nearest Neighbor (ANN) searches across millions or even billions of vectors.
For our “Chroma News” platform, we’ll focus on ChromaDB. It’s an open-source, developer-friendly vector database that can be run in-memory, on-disk, or in a client-server mode, making it ideal for everything from prototyping on Google Colab to full-scale production. While Chroma is our focus, the ecosystem is rich with alternatives like Pinecone News, Milvus News, Weaviate News, and Qdrant News, each with its own trade-offs in terms of scalability, features, and management overhead. The underlying principles, however, remain the same.
Here’s a practical example of creating embeddings for news headlines and storing them in a local ChromaDB instance.
# Step 1: Install necessary libraries
# pip install chromadb sentence-transformers
import chromadb
from sentence_transformers import SentenceTransformer
# Step 2: Initialize the embedding model and ChromaDB client
# Using a popular model from the Sentence Transformers library
model = SentenceTransformer('all-MiniLM-L6-v2')
client = chromadb.Client() # For in-memory storage
# Create or get a collection to store our news vectors
# A collection is similar to a table in a SQL database
collection = client.get_or_create_collection(name="news_headlines")
# Step 3: Sample news headlines to be processed
news_data = [
"OpenAI Launches 'Agent Store' for AI Agent Applications",
"UK's FCA Issues Regulatory Framework for AI in Financial Services",
"NVIDIA AI News: Hopper Architecture Pushes Inference Boundaries",
"Latest PyTorch News: 2.1 Release Focuses on Compiler Performance",
"Mistral AI News: Company Releases New Open-Source Large Language Model"
]
# Step 4: Generate embeddings for each headline
embeddings = model.encode(news_data)
# Step 5: Add the data to the ChromaDB collection
# We use the index as a simple ID here. In a real application,
# this would be a unique article ID from your database.
collection.add(
embeddings=embeddings,
documents=news_data,
ids=[f"id_{i}" for i in range(len(news_data))]
)
print(f"Successfully added {collection.count()} articles to the collection.")Building the Ingestion and Retrieval Pipeline
With the core components in place, the next step is to build a robust pipeline that can continuously ingest news from various sources and make it searchable. This involves data fetching, processing, and implementing the semantic query logic.
Data Ingestion and Processing
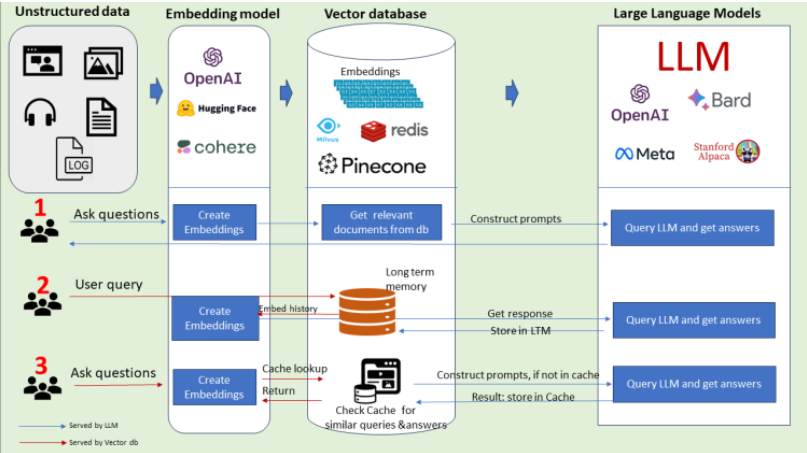
A real-world news platform needs to aggregate content from thousands of sources, such as news APIs (e.g., NewsAPI), RSS feeds, or direct web scraping. The raw data, often in HTML format, must be cleaned to extract the core article text. For long articles, a crucial step is “chunking”—breaking the text into smaller, semantically coherent pieces. This is important because embedding models have a fixed context window, and embedding smaller chunks often yields more precise search results.
Orchestration frameworks like LangChain News and LlamaIndex News are invaluable here. They provide pre-built connectors for hundreds of data sources, document transformers for cleaning and chunking, and seamless integration with embedding models and vector stores. Using a framework like Haystack News can also streamline the creation of these complex data pipelines.
Semantic Search in Action
Once the data is ingested, the retrieval process is remarkably elegant. When a user submits a query (e.g., “What are the latest AI regulations in Europe?”), the pipeline performs the following steps:
- Embed the Query: The user’s query string is passed through the same embedding model used for the news articles.
- Query the Vector Database: The resulting query vector is sent to ChromaDB.
- Perform Similarity Search: ChromaDB searches the specified collection to find the vectors (and their associated document chunks) that are closest to the query vector in the high-dimensional space.
- Return Results: The top N most similar document chunks are returned to the user or a downstream application.
This code example demonstrates a function that encapsulates this retrieval logic.
# Assuming the collection from the previous example is already populated
# and the 'model' and 'collection' variables are in scope.
def find_relevant_news(query_text: str, top_k: int = 3):
"""
Finds the most relevant news articles for a given query.
Args:
query_text (str): The user's search query.
top_k (int): The number of top results to return.
Returns:
dict: A dictionary containing the most relevant documents.
"""
# 1. Embed the user's query
query_embedding = model.encode([query_text])
# 2. Query the collection in ChromaDB
results = collection.query(
query_embeddings=query_embedding,
n_results=top_k
)
return results
# Example Usage:
user_query = "What is the latest news on AI governance?"
relevant_articles = find_relevant_news(user_query)
# Print the results
print(f"Query: '{user_query}'\n")
print("Top Relevant Articles:")
for i, doc in enumerate(relevant_articles['documents'][0]):
print(f"{i+1}. {doc}")
# In a real app, you would also use the IDs and distances
# print(f" ID: {relevant_articles['ids'][0][i]}")
# print(f" Distance: {relevant_articles['distances'][0][i]}")Advanced Features: RAG, Summarization, and Trend Analysis
A truly intelligent news platform does more than just search. It synthesizes information, provides summaries, and uncovers hidden trends. This is where we combine the retrieval power of our vector database with the generative capabilities of LLMs.
Retrieval-Augmented Generation (RAG) for News Summaries
Retrieval-Augmented Generation (RAG) is a powerful technique that enhances the output of LLMs with fresh, external information. Instead of just asking an LLM (like one from Anthropic News or Mistral AI News) to answer a question from its internal knowledge, we first retrieve relevant context from our up-to-date “Chroma News” database. This context is then injected into the prompt, instructing the LLM to base its answer on the provided articles. This approach dramatically reduces hallucinations and ensures the generated summaries are timely and factually grounded in the latest news.
Tools like LangChain make building RAG chains straightforward. Debugging these multi-step interactions can be complex, which is where observability platforms like LangSmith become essential for tracking the flow of data from retrieval to generation.
Here is a simplified RAG implementation using the OpenAI API and our existing retrieval function.
# Step 1: Install OpenAI library
# pip install openai
import os
from openai import OpenAI
# It's best practice to use environment variables for API keys
# os.environ["OPENAI_API_KEY"] = "your-api-key"
client = OpenAI()
def generate_news_summary(query: str):
"""
Generates a summary of the latest news on a topic using RAG.
"""
# 1. Retrieve relevant news articles (the "R" in RAG)
retrieved_context = find_relevant_news(query, top_k=5)
context_str = "\n\n".join(retrieved_context['documents'][0])
# 2. Construct a prompt with the retrieved context
system_prompt = "You are a helpful AI news assistant. Your task is to synthesize the provided news articles into a concise summary. Base your answer only on the information given in the context."
user_prompt = f"""
Context from recent news articles:
---
{context_str}
---
Based on the context above, please provide a summary of the latest developments regarding the query: "{query}"
"""
# 3. Generate the summary using an LLM (the "G" in RAG)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.5,
)
return response.choices[0].message.content
# Example usage:
summary_query = "What is the latest from OpenAI and the FCA on AI?"
generated_summary = generate_news_summary(summary_query)
print(generated_summary)Topic Clustering and Trend Detection
The vector space itself is a rich source of insight. By applying unsupervised machine learning algorithms like K-Means or DBSCAN to the article embeddings, we can automatically discover clusters of related news stories. A dense, rapidly growing cluster might indicate a breaking news event or a trending topic. This allows the “Chroma News” platform to surface emerging narratives without any manual curation, providing a real-time pulse on global events.
MLOps, Scaling, and Best Practices
Transitioning a “Chroma News” prototype from a notebook to a production-grade service requires careful consideration of the MLOps lifecycle, scalability, and performance optimization.
Model and Data Lifecycle Management
The performance of the entire system hinges on the quality of the embedding model. As new and improved models are released, you’ll need a systematic way to evaluate and deploy them. Experiment tracking tools like MLflow News, Weights & Biases News, or Comet ML are critical for logging metrics, managing model versions, and ensuring reproducibility. Similarly, the data in your vector database must be versioned and managed, with clear strategies for updating and expiring old articles.
Scaling for Production
As the volume of news and user traffic grows, the system must scale. This involves several key areas:
- Vector Database: Move from an in-memory Chroma instance to its client-server deployment model, which can be scaled independently. Connecting to it is a simple change in the client initialization.
- Embedding Service: The process of encoding text into vectors can be a bottleneck. This can be scaled horizontally using distributed computing frameworks like Ray News or Dask News, or by deploying the embedding model as a dedicated microservice on high-performance inference servers like NVIDIA AI News‘s Triton Inference Server.
- LLM Inference: For the RAG component, optimizing LLM serving is crucial for latency and cost. Open-source tools like vLLM News or Ollama News provide high-throughput inference. Alternatively, managed services like Amazon Bedrock News, Azure AI News, or platforms like Modal News and Replicate News can handle the complexities of GPU provisioning and scaling.
- Cloud Infrastructure: Leveraging managed cloud platforms like AWS SageMaker, Google’s Vertex AI News, or Azure Machine Learning can provide the robust infrastructure needed for training, deployment, and monitoring.
Connecting to a production, server-based ChromaDB instance is straightforward:
import chromadb
# To connect to a ChromaDB instance running on a server
# (e.g., in a Docker container or on a cloud VM)
# Replace 'your-chroma-server-ip' with the actual IP address or hostname.
production_client = chromadb.HttpClient(host='your-chroma-server-ip', port=8000)
# You can now interact with collections on the server just like with a local client
production_collection = production_client.get_collection(name="news_headlines")
print(f"Connected to production ChromaDB. Collection count: {production_collection.count()}")
# The find_relevant_news and other functions can be adapted to use this client.Conclusion: The Future of Information Consumption
We’ve journeyed through the architecture of “Chroma News,” a conceptual but highly practical blueprint for the next generation of AI-powered information platforms. By transforming unstructured news into meaningful vector embeddings and leveraging the speed of vector databases like ChromaDB, we can move beyond simple keyword matching to true semantic understanding. The addition of Retrieval-Augmented Generation (RAG) elevates the system from a search engine to a knowledge synthesis tool, capable of delivering concise, accurate, and timely summaries.
The technologies underpinning this revolution—from frameworks like PyTorch News and TensorFlow News that build the models, to the platforms like Hugging Face that distribute them, and the databases like Chroma that serve them—are evolving at a breakneck pace. As models become more powerful and tools more accessible, the ability to build sophisticated, context-aware applications is no longer limited to a few large tech labs. The future of news and information retrieval will be personalized, contextual, and deeply intelligent, and the principles outlined here are the key to building it.


