
Building an AI-Powered News Insights Engine: A Deep Dive into Modern NLP and RAG Techniques
Introduction: From News Feeds to Actionable Intelligence
In today’s hyper-connected world, the sheer volume of news generated daily is staggering. For businesses, financial analysts, and researchers, this deluge of information represents both a monumental challenge and a massive opportunity. The ability to sift through this noise, identify relevant trends, and extract actionable insights in real-time is a significant competitive advantage. This is the domain of AI-powered news analysis, a field once dominated by proprietary systems like IBM Watson News. These platforms demonstrated the power of applying natural language processing (NLP) and machine learning to unstructured text data at scale.
However, the landscape has dramatically shifted. The proliferation of powerful open-source tools and models has democratized the ability to build sophisticated “Insights Engines.” Today, developers can construct systems that not only categorize and search news but also understand context, identify relationships between entities, and even answer complex questions about the data. This article provides a comprehensive technical blueprint for building such a system. We will explore the core architectural components, from data ingestion and NLP-driven feature extraction to implementing advanced semantic search with vector databases and creating conversational interfaces using Retrieval-Augmented Generation (RAG). This guide will equip you with the knowledge and practical code examples to transform raw news feeds into a dynamic source of strategic intelligence.
Section 1: The Architectural Blueprint of a News Insights Engine
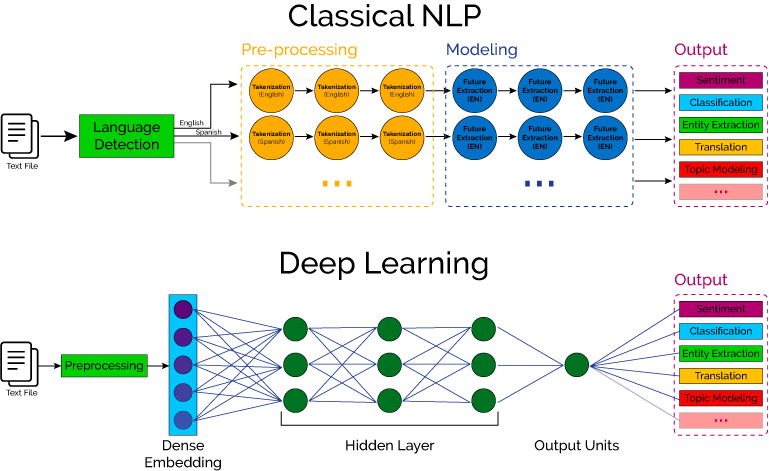
At its core, a news insights engine is a multi-stage pipeline that processes, enriches, and indexes text data to make it discoverable and useful. The initial stages are critical for building a solid foundation for all subsequent analysis. This involves not just fetching the data but also understanding its fundamental components through proven NLP techniques.
Data Ingestion and Preprocessing
The first step is to aggregate news content from various sources. This can be achieved through dedicated news APIs (e.g., NewsAPI, GDELT), RSS feeds, or custom web scrapers built with libraries like Scrapy or BeautifulSoup. Once acquired, the raw HTML or JSON data must be cleaned and parsed to extract the core text content, headlines, publication dates, and other relevant metadata. Preprocessing steps like sentence segmentation and removing boilerplate content are essential for ensuring data quality.
Core NLP Tasks: Entity Recognition and Sentiment Analysis
Once we have clean text, the enrichment process begins. A key task is Named Entity Recognition (NER), which involves identifying and categorizing key entities such as people, organizations, locations, and products mentioned in the text. This transforms an unstructured article into a structured set of data points. Modern NER models, particularly those available through the Hugging Face Transformers News ecosystem, offer state-of-the-art performance. These models, often built on architectures from Google DeepMind News or Meta AI News, can be fine-tuned for specific domains, like finance or sports, to improve accuracy.
The following Python code demonstrates how to use a pre-trained NER model from Hugging Face to extract entities from a sample news headline. This is a foundational step in understanding “who” and “what” an article is about.
# Ensure you have the required libraries installed:
# pip install torch transformers
from transformers import pipeline
# Load a pre-trained NER pipeline from Hugging Face
# This model is well-suited for general news content
ner_pipeline = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english", grouped_entities=True)
news_text = "IBM announced a new partnership with the Ultimate Fighting Championship (UFC) in Las Vegas to develop an AI-powered insights engine using its Watsonx platform."
# Process the text to extract entities
entities = ner_pipeline(news_text)
# Print the extracted entities
print("Extracted Entities:")
for entity in entities:
print(f"- Entity: {entity['word']}, Type: {entity['entity_group']}, Score: {entity['score']:.4f}")
# Example Output:
# Extracted Entities:
# - Entity: IBM, Type: ORG, Score: 0.9996
# - Entity: Ultimate Fighting Championship, Type: ORG, Score: 0.9953
# - Entity: UFC, Type: ORG, Score: 0.9989
# - Entity: Las Vegas, Type: LOC, Score: 0.9997
# - Entity: Watsonx, Type: MISC, Score: 0.9881Section 2: Implementing Semantic Search with Vector Databases
Traditional keyword search is limited. It fails when users search for concepts using different terminology than what’s in the source text. To build a true insights engine, we must move beyond keywords to semantic understanding. This is achieved by converting text into numerical representations called “embeddings” and searching for them in a specialized vector database.
From Keywords to Meaning: The Power of Embeddings
Embeddings are dense vectors that capture the semantic meaning of a piece of text. Models like those from the Sentence Transformers News library are specifically trained to produce embeddings where texts with similar meanings are located close to each other in vector space. This means a search for “corporate tech partnerships” could find the article from our previous example, even though it doesn’t contain that exact phrase. The underlying models are often built using frameworks like PyTorch News or TensorFlow News, leveraging advancements in transformer architectures.
Choosing a Vector Database
Once we have embeddings, we need an efficient way to store and search through millions or even billions of them. This is the role of a vector database. These databases are optimized for finding the “nearest neighbors” to a given query vector at high speed. Popular open-source options include:
- FAISS News: A library from Meta AI for efficient similarity search, ideal for in-memory, high-performance applications.
- Chroma News: An open-source embedding database designed to be simple to use and integrate into applications.
- Milvus News and Weaviate News: More robust, scalable, and production-oriented vector databases that offer features like filtering and cloud-native deployments.
- Managed solutions like Pinecone News provide a fully hosted service, abstracting away the operational complexity.
The following code shows how to generate embeddings for our news snippets and index them using FAISS for fast similarity search.
# Ensure you have the required libraries installed:
# pip install sentence-transformers faiss-cpu
from sentence_transformers import SentenceTransformer
import numpy as np
import faiss
# 1. Load a pre-trained sentence embedding model
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. Our collection of news documents (corpus)
documents = [
"IBM announced a new partnership with the Ultimate Fighting Championship (UFC) in Las Vegas.",
"NVIDIA revealed its latest Blackwell GPU architecture, promising a massive leap in AI training performance.",
"Google DeepMind's new AlphaFold 3 model can predict the structure of proteins with unprecedented accuracy.",
"The UFC is leveraging artificial intelligence to provide fans with deeper analytics and fight predictions."
]
# 3. Generate embeddings for all documents
print("Generating document embeddings...")
doc_embeddings = model.encode(documents)
doc_embeddings = np.array(doc_embeddings).astype('float32')
# 4. Build a FAISS index
embedding_dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dimension) # Using a simple L2 distance index
index.add(doc_embeddings)
print(f"FAISS index built with {index.ntotal} vectors.")
# 5. Perform a semantic search
query_text = "Which companies are using AI in sports?"
query_embedding = model.encode([query_text])
query_embedding = np.array(query_embedding).astype('float32')
# Search for the top 2 most similar documents
k = 2
distances, indices = index.search(query_embedding, k)
print(f"\nSearch results for: '{query_text}'")
for i, idx in enumerate(indices[0]):
print(f"{i+1}. Document: '{documents[idx]}' (Distance: {distances[0][i]:.4f})")
# Example Output:
# Search results for: 'Which companies are using AI in sports?'
# 1. Document: 'The UFC is leveraging artificial intelligence to provide fans with deeper analytics and fight predictions.' (Distance: 0.5831)
# 2. Document: 'IBM announced a new partnership with the Ultimate Fighting Championship (UFC) in Las Vegas.' (Distance: 0.8125)Section 3: Advanced Applications with Retrieval-Augmented Generation (RAG)
Semantic search is powerful, but the next frontier is creating systems that can synthesize information and provide direct, natural language answers. This is where Retrieval-Augmented Generation (RAG) comes in. RAG combines the retrieval power of our vector database with the generative capabilities of Large Language Models (LLMs) from providers like OpenAI News, Anthropic News, or open-source alternatives from Mistral AI News and Meta AI News (Llama).
Orchestrating the RAG Pipeline
A RAG pipeline works by first taking a user’s question, converting it into an embedding, and retrieving the most relevant news articles from the vector database (the “retrieval” step). Then, it feeds these retrieved articles as context, along with the original question, into an LLM. The LLM then generates a concise, human-like answer based *only* on the provided context (the “generation” step). This approach significantly reduces hallucinations and ensures answers are grounded in the source data.
Frameworks like LangChain News and LlamaIndex News are indispensable for building these pipelines. They provide high-level abstractions for connecting data sources, retrieval systems, and LLMs, dramatically simplifying development.
Here is an example of a simple RAG implementation using LangChain to build a Q&A system over our indexed news articles.
# Ensure you have the required libraries installed:
# pip install langchain sentence-transformers faiss-cpu transformers torch
from langchain.chains import RetrievalQA
from langchain.vectorstores import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.llms import HuggingFacePipeline
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# Use the same documents and FAISS index setup from the previous example
# For simplicity, we'll recreate it here within the LangChain context.
documents = [
"IBM announced a new partnership with the Ultimate Fighting Championship (UFC) in Las Vegas.",
"NVIDIA revealed its latest Blackwell GPU architecture, promising a massive leap in AI training performance.",
"Google DeepMind's new AlphaFold 3 model can predict the structure of proteins with unprecedented accuracy.",
"The UFC is leveraging artificial intelligence to provide fans with deeper analytics and fight predictions."
]
# 1. Setup embeddings and vector store
embeddings = HuggingFaceEmbeddings(model_name='all-MiniLM-L6-v2')
vector_store = FAISS.from_texts(documents, embeddings)
# 2. Setup a local LLM for generation (e.g., a small model from Hugging Face)
# This avoids API keys for a self-contained example. In production, you might use OpenAI or Anthropic.
model_name = "gpt2" # Using a smaller model for demonstration
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
llm_pipeline = pipeline("text-generation", model=model, tokenizer=tokenizer, max_new_tokens=100)
llm = HuggingFacePipeline(pipeline=llm_pipeline)
# 3. Create the RetrievalQA chain
# This chain combines the retriever (our vector store) and the LLM
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # "stuff" puts all retrieved docs into the context
retriever=vector_store.as_retriever()
)
# 4. Ask a question
question = "What is the UFC doing with AI?"
response = qa_chain.run(question)
print(f"Question: {question}")
print(f"Answer: {response}")
# The LLM will synthesize an answer based on the retrieved documents:
# "The UFC is leveraging artificial intelligence to provide fans with deeper analytics and fight predictions. They also have a partnership with IBM."Section 4: MLOps, Optimization, and Best Practices
Building a prototype is one thing; deploying a robust, scalable, and reliable insights engine is another. This requires a focus on MLOps (Machine Learning Operations), model optimization, and scalable infrastructure.
Production-Ready Models and Serving
The models used for embeddings and generation must be optimized for low-latency inference. Formats like ONNX News or tools like NVIDIA AI News‘s TensorRT News can significantly accelerate model performance. These optimized models can then be deployed on dedicated inference servers like Triton Inference Server News, which can handle concurrent requests efficiently and manage multiple models. For edge or CPU-based deployments, Intel’s OpenVINO News toolkit is an excellent choice.
Experiment Tracking and Scalability
As you fine-tune models or experiment with different RAG prompting strategies, it’s crucial to track your work. Tools like MLflow News, Weights & Biases News, and Comet ML News are essential for logging experiments, managing model versions, and ensuring reproducibility. When the workload grows, you’ll need to scale your data processing and model inference. Distributed computing frameworks like Ray News or Dask News can parallelize embedding generation across multiple machines. For a fully managed experience, cloud platforms like AWS SageMaker News, Google’s Vertex AI News, and Azure Machine Learning News provide end-to-end infrastructure for training, deploying, and managing ML models at scale.
Best Practices and Considerations
- Data Freshness: News data is time-sensitive. Implement a robust data pipeline that continuously ingests and indexes new articles to keep your insights engine current.
- Chunking Strategy: For long articles, breaking them into smaller, overlapping chunks before embedding can improve retrieval accuracy. Experiment with different chunk sizes.
- Evaluation: Continuously evaluate the performance of your RAG system. Use frameworks like LangSmith News to trace and debug LLM calls and retrieval steps.
–Hybrid Search: Combine semantic search with traditional keyword search (like BM25) to get the best of both worlds. This can improve performance on queries with specific acronyms or codes.
Conclusion: The Future of News Consumption
We have journeyed from the conceptual foundation of a news insights engine to the practical implementation of its core components. By combining modern NLP techniques for entity extraction, vector databases for powerful semantic search, and RAG pipelines for conversational Q&A, we can build systems that rival the capabilities of established platforms. The open-source ecosystem, with contributions from the Hugging Face News community and frameworks like LangChain News, has made these advanced AI technologies more accessible than ever.
The key takeaway is the paradigm shift from passive information consumption to active, intelligent interaction with data. The next step is to start building. Begin with a specific domain of news, set up a data ingestion pipeline, and experiment with the code examples provided. As you iterate, you can explore more advanced techniques like fine-tuning your own embedding models, integrating knowledge graphs, and deploying your application with a user-friendly interface using tools like Streamlit News or Gradio News. The era of AI-driven intelligence is here, and the tools to harness it are at your fingertips.


