
Mastering Pinecone: A Developer’s Guide to Embedding and Upserting Data
Introduction to Vector Databases and Pinecone
In the rapidly evolving landscape of artificial intelligence, vector databases have emerged as a cornerstone technology for building sophisticated applications like semantic search, recommendation engines, and Retrieval-Augmented Generation (RAG) systems. Unlike traditional databases that store and query structured data, vector databases are optimized for storing, managing, and searching high-dimensional vector embeddings. These embeddings are numerical representations of unstructured data—such as text, images, or audio—that capture semantic meaning. This allows for powerful similarity searches, finding items that are conceptually related rather than just lexically identical.
Pinecone is a leading managed vector database service that simplifies the process of building and scaling these AI-powered applications. It provides a highly performant, scalable, and easy-to-use API for developers. However, as with any powerful tool, mastering its core operations is key to unlocking its full potential. A common hurdle for developers, especially those new to the ecosystem, is understanding the precise workflow for generating embeddings and correctly formatting data for the `upsert` operation. This article provides a comprehensive, practical guide to mastering this fundamental process, moving from core concepts to advanced techniques and best practices. We’ll explore how to seamlessly integrate popular embedding models and frameworks, ensuring your journey with Pinecone is both successful and efficient. This guide is essential for anyone following the latest in Pinecone News and the broader AI infrastructure space, including developments from LangChain News and LlamaIndex News.
Section 1: Core Concepts – From Raw Data to Pinecone-Ready Vectors
Before we can store anything in Pinecone, we must first convert our raw data into vector embeddings. This process is the foundation of any vector search application. The choice of embedding model is critical, as it directly influences the quality and relevance of your search results. The AI community is constantly innovating, with frequent updates in Hugging Face Transformers News and Sentence Transformers News providing new and improved models.
What are Embeddings?
An embedding is a dense vector of floating-point numbers that represents a piece of data. For text, an embedding model reads a sentence or paragraph and outputs a vector that encapsulates its semantic meaning. Two pieces of text with similar meanings will have vectors that are “close” to each other in the high-dimensional vector space, typically measured by cosine similarity or Euclidean distance. Popular libraries like sentence-transformers, built on top of PyTorch and TensorFlow, make generating these embeddings incredibly straightforward.
Setting Up Your Environment and Initializing Pinecone
First, you need to set up your Python environment and install the necessary libraries. You’ll also need your Pinecone API key and environment name, which you can find in your Pinecone console.
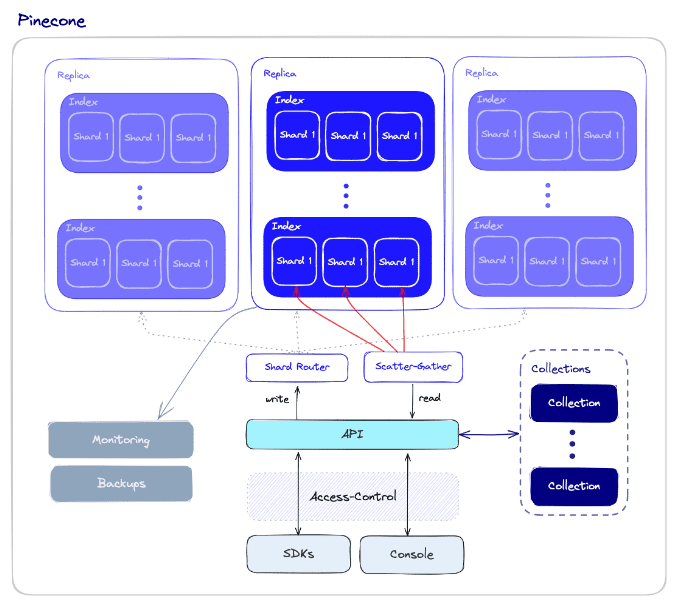
This initial code block demonstrates the complete setup: installing libraries, importing them, initializing the Pinecone client, and creating a new index if one doesn’t already exist. A critical step is ensuring the `dimension` of your Pinecone index matches the output dimension of your chosen embedding model. For example, the popular `all-MiniLM-L6-v2` model produces 384-dimensional vectors.
# Step 1: Install necessary libraries
# !pip install -qU pinecone-client sentence-transformers
import os
from pinecone import Pinecone, ServerlessSpec
from sentence_transformers import SentenceTransformer
from getpass import getpass
# Step 2: Initialize Pinecone
# It's best practice to use environment variables for keys
# PINECONE_API_KEY = os.environ.get("PINECONE_API_KEY") or getpass("Enter your Pinecone API Key: ")
# PINECONE_ENVIRONMENT = os.environ.get("PINECONE_ENVIRONMENT") or getpass("Enter your Pinecone Environment: ")
# For this example, we'll hardcode them. Replace with your actual credentials.
PINECONE_API_KEY = "YOUR_API_KEY"
PINECONE_ENVIRONMENT = "YOUR_ENVIRONMENT"
pc = Pinecone(api_key=PINECONE_API_KEY)
# Step 3: Define index name and check if it exists
index_name = "technical-article-index"
if index_name not in pc.list_indexes().names():
print(f"Creating index '{index_name}'...")
pc.create_index(
name=index_name,
dimension=384, # Dimension of the all-MiniLM-L6-v2 model
metric='cosine',
spec=ServerlessSpec(
cloud='aws',
region='us-west-2'
)
)
print("Index created successfully.")
else:
print(f"Index '{index_name}' already exists.")
# Connect to the index
index = pc.Index(index_name)
# Step 4: Initialize the embedding model
# This is a popular, high-performance model from Hugging Face
model = SentenceTransformer('all-MiniLM-L6-v2')
print("Setup complete. Pinecone index and embedding model are ready.")
print(index.describe_index_stats())Section 2: The Upsert Operation Demystified
The `upsert` operation is how you add or update vectors in your Pinecone index. While the concept is simple, the exact data structure required by the API can be a point of confusion. Getting this format right is crucial for successful data ingestion. The latest Pinecone News often highlights improvements to the SDKs that make these operations more intuitive, but understanding the underlying structure remains vital.
The Anatomy of an Upsert Request
The Pinecone `index.upsert()` method expects a list of vectors to be uploaded. Each item in this list must be a tuple containing three elements in a specific order: `(id, vector, metadata)`.
- ID (string): A unique identifier for your vector. This is how you will reference, update, or delete the vector later. It’s crucial that these IDs are unique within your index (or namespace).
- Vector (list of floats): The actual embedding generated by your model. Its dimensionality must match the one specified when the index was created.
- Metadata (dictionary): An optional dictionary of key-value pairs associated with the vector. This is incredibly powerful for filtering queries. For example, you could store the source document name, a publication date, or category tags. Query results can then be filtered based on this metadata before the vector similarity search is even performed, making your application much more powerful.
A Simple, Practical Upsert Example
Let’s take a few sentences, generate their embeddings, and upsert them into our index. This example clearly illustrates the required `(id, vector, metadata)` tuple format.
# Assume 'index' and 'model' are already initialized from the previous step
# Data we want to embed and upsert
documents = [
{"id": "doc1", "text": "Pinecone is a vector database for AI applications.", "source": "official-docs"},
{"id": "doc2", "text": "Sentence Transformers makes generating embeddings easy.", "source": "hugging-face"},
{"id": "doc3", "text": "LangChain and LlamaIndex integrate with Pinecone.", "source": "community-blog"}
]
# Prepare data for upserting
vectors_to_upsert = []
for doc in documents:
# Generate the embedding
embedding = model.encode(doc["text"]).tolist()
# Create the metadata dictionary
metadata = {"text": doc["text"], "source": doc["source"]}
# Append the tuple to our list
vectors_to_upsert.append((doc["id"], embedding, metadata))
# Perform the upsert operation
print("Upserting vectors into Pinecone...")
index.upsert(vectors=vectors_to_upsert)
# Check the index statistics to confirm the upsert
print("Upsert complete.")
print(index.describe_index_stats())
# Example of a simple query
query_text = "What is Pinecone?"
query_vector = model.encode(query_text).tolist()
query_results = index.query(
vector=query_vector,
top_k=2,
include_metadata=True
)
print("\nQuery Results:")
for result in query_results['matches']:
print(f" - ID: {result['id']}, Score: {result['score']:.4f}, Text: {result['metadata']['text']}")This example demonstrates the end-to-end flow for a small number of documents. However, real-world applications often involve thousands or millions of records, which requires a more robust approach.
Section 3: Advanced Techniques – Batch Processing and Namespaces
When working with large datasets, upserting vectors one by one is highly inefficient and can lead to performance issues or API rate limiting. The solution is to process data in batches. Furthermore, Pinecone offers a feature called “namespaces” to partition vectors within a single index, which is essential for multi-tenant applications or for logically separating different datasets.

Efficient Data Ingestion with Batching
The `upsert` method is designed to handle multiple vectors at once. The best practice is to group your data into batches (e.g., 100 or 200 records at a time) and send them in a single API call. This significantly reduces network overhead and improves ingestion speed. The following code provides a reusable helper function to handle this batching process gracefully.
import pandas as pd
from tqdm.auto import tqdm # For a nice progress bar
# Assume 'index' and 'model' are initialized
# Create a larger dummy dataset using pandas
data = {
'id': [f'data_{i}' for i in range(500)],
'content': [f'This is sample document number {i} about various AI topics.' for i in range(500)],
'category': ['tech' if i % 2 == 0 else 'science' for i in range(500)]
}
df = pd.DataFrame(data)
def batch_generator(data_frame, batch_size=100):
"""Yields batches of data from a pandas DataFrame."""
for i in range(0, len(data_frame), batch_size):
yield data_frame.iloc[i:i + batch_size]
print("Starting batch upsert process for 500 documents...")
# Process and upsert in batches
for batch_df in tqdm(batch_generator(df, batch_size=100), total=len(df)//100):
# Get the text content for the current batch
texts_to_embed = batch_df['content'].tolist()
# Generate embeddings for the batch
embeddings = model.encode(texts_to_embed)
# Prepare the data in the required (id, vector, metadata) format
vectors_to_upsert = []
for i, row in batch_df.iterrows():
vector_id = row['id']
vector_embedding = embeddings[batch_df.index.get_loc(i)].tolist()
vector_metadata = {
"text": row['content'],
"category": row['category']
}
vectors_to_upsert.append((vector_id, vector_embedding, vector_metadata))
# Upsert the batch to Pinecone
index.upsert(vectors=vectors_to_upsert)
print("\nBatch upsert complete.")
print(index.describe_index_stats())Using Namespaces for Data Isolation
Namespaces act like virtual partitions within your index. You can upsert data into a specific namespace and later query only that namespace. This is perfect for scenarios where you need to separate data for different users, customers, or document sources without the overhead of creating multiple indexes. Using namespaces is as simple as adding the `namespace` parameter to your `upsert` and `query` calls.
# Assume 'index' and 'model' are initialized
# Data for two different "users" or "sources"
user_a_doc = ("user_a_doc1", model.encode("Information relevant to user A").tolist(), {"user": "A"})
user_b_doc = ("user_b_doc1", model.encode("Completely different info for user B").tolist(), {"user": "B"})
# Upsert into different namespaces
print("Upserting into namespace 'user-a-space'...")
index.upsert(vectors=[user_a_doc], namespace="user-a-space")
print("Upserting into namespace 'user-b-space'...")
index.upsert(vectors=[user_b_doc], namespace="user-b-space")
# Querying a specific namespace
query_vector = model.encode("Data for user A").tolist()
print("\nQuerying namespace 'user-a-space':")
results_a = index.query(
vector=query_vector,
top_k=1,
namespace="user-a-space",
include_metadata=True
)
print(results_a['matches']) # Should return user_a_doc1
print("\nQuerying namespace 'user-b-space':")
results_b = index.query(
vector=query_vector,
top_k=1,
namespace="user-b-space",
include_metadata=True
)
print(results_b['matches']) # Should return an empty or irrelevant resultSection 4: Best Practices, Optimization, and Common Pitfalls
Following best practices ensures your Pinecone-powered application is robust, scalable, and cost-effective. The AI ecosystem, with constant OpenAI News, Google DeepMind News, and Meta AI News, is always pushing the boundaries, and optimizing your vector database is key to keeping up.
Key Considerations for Production
- ID Management: Always use stable, unique, and meaningful IDs. A common practice is to use the primary key of the source data from your main database. This makes it easy to link back to the original content. Avoid using random or sequential IDs that have no external meaning.
- Metadata Optimization: While metadata is powerful, it’s not a replacement for a primary database. Keep it concise and focused on attributes you need for filtering. Storing entire document texts in metadata can increase latency. The best practice is to store a snippet or summary and use the ID to fetch the full content from another data store.
- Dimensionality Mismatch: A frequent error is a mismatch between the embedding model’s output dimension and the index’s configured dimension. This will cause an API error. Always double-check your model’s documentation (e.g., on Hugging Face) and ensure your `pc.create_index` call uses the correct value.
- Monitoring and Scaling: Regularly check your index stats in the Pinecone console. Monitor the `vector_count` to ensure your upserts are succeeding. For production workloads, choose the appropriate pod size and type, and be prepared to scale up as your data grows.
- Error Handling: Network requests can fail. Wrap your `upsert` calls in `try…except` blocks to catch potential exceptions and implement a retry mechanism for transient errors.
By keeping these points in mind, you can avoid common pitfalls and build a more resilient system. Staying updated with news from platforms like AWS SageMaker News and Azure AI News can also provide insights into deploying and managing AI infrastructure at scale.
Conclusion and Next Steps
We have journeyed through the essential process of preparing data, generating embeddings, and successfully upserting it into Pinecone. By understanding the core `(id, vector, metadata)` data structure and implementing efficient batching strategies, you can overcome the most common hurdles developers face. The key takeaways are clear: choose the right embedding model, ensure your index dimensions match, structure your data correctly, and always process in batches for performance.
With this foundation, you are now well-equipped to build powerful AI applications. Your next steps could involve exploring more advanced querying techniques like hybrid search (combining keyword and vector search), integrating Pinecone into higher-level frameworks like LangChain or LlamaIndex to build complex RAG pipelines, or experimenting with different embedding models from providers like OpenAI, Cohere, or the open-source community. The world of vector search is vast and exciting, and by mastering these fundamentals, you are ready to innovate and build the next generation of intelligent applications.


