
Supercharge Your ML Workflow: A Technical Guide to the Amazon SageMaker Unified Studio
Introduction: A New Era for Collaborative AI Development
The modern machine learning landscape is a complex tapestry of disparate tools, platforms, and frameworks. Data scientists, ML engineers, and data analysts often find themselves navigating a fragmented workflow, juggling separate environments for data preparation, model training, experiment tracking, and deployment. This friction not only slows down innovation but also creates significant barriers to collaboration. In response to this challenge, the evolution of integrated development environments (IDEs) for machine learning has become a critical focal point. The latest AWS SageMaker News introduces a significant leap forward: a unified, collaborative studio experience designed to serve as the single pane of glass for the entire ML lifecycle.
This new iteration of Amazon SageMaker Studio reimagines the developer experience by centralizing everything from data exploration in familiar notebooks to production-grade code development in a VS Code-based editor. It’s built on the core principles of collaboration, flexibility, and integration, allowing teams to share resources, code, and environments seamlessly. Whether you’re fine-tuning a foundation model from Hugging Face, building a RAG application with Amazon Bedrock, or training a classic computer vision model with TensorFlow, this unified platform aims to streamline every step. This article provides a comprehensive technical deep dive into the new SageMaker Studio, exploring its core components, practical implementation, advanced generative AI workflows, and best practices for optimization.
Section 1: Core Concepts of the Unified Workspace
The fundamental shift with the new SageMaker Studio is the move from isolated, user-specific instances to a collaborative, project-centric model. This is architected around several key components that work in concert to create a cohesive development environment.
From Silos to Synergy: Introducing SageMaker Studio Spaces
At the heart of the new collaborative experience are SageMaker Studio Spaces. A Space is a shared environment where team members can access and work on the same set of resources, including code files, Jupyter notebooks, and data. Each Space has its own isolated storage and can be configured with specific compute resources and lifecycle policies. This is a paradigm shift from the classic model where each user had their own private home directory. Now, a team can spin up a Space for a specific project, clone a Git repository into it, and have all members work from the same codebase in real-time. This eliminates the “it works on my machine” problem and drastically simplifies environment setup and dependency management, a common pain point when working with complex libraries from the worlds of PyTorch News or TensorFlow News.
A Modern IDE: The Integrated Code Editor and Enhanced Notebooks
Acknowledging that modern ML development is more than just notebooks, the unified studio now includes a fully-featured Code Editor based on Visual Studio Code – Open Source. This provides developers with a familiar, powerful environment complete with extensions, integrated Git, a terminal, and robust debugging capabilities. You can now write, test, and debug production-level Python applications, infrastructure-as-code scripts, or even front-end code for a Streamlit or Gradio app directly within SageMaker.
The JupyterLab experience has also been enhanced, running as an application within the same unified interface. This allows for a seamless transition between exploratory data analysis in a notebook and modular code development in the editor. To get started, you can easily launch a training job directly from a script in the Code Editor using the SageMaker SDK.
import sagemaker
from sagemaker.pytorch import PyTorch
# Initialize a SageMaker session
sagemaker_session = sagemaker.Session()
role = sagemaker.get_execution_role()
bucket = sagemaker_session.default_bucket()
prefix = 'pytorch-training-job'
# Define the PyTorch Estimator
estimator = PyTorch(
entry_point='train.py', # Your training script
source_dir='./scripts', # Directory containing the script
role=role,
instance_count=1,
instance_type='ml.g4dn.xlarge', # A GPU instance for training
framework_version='2.1',
py_version='py310',
hyperparameters={
'epochs': 5,
'learning-rate': 0.001
}
)
# Start the training job
estimator.fit({'training': f's3://{bucket}/{prefix}/training_data'})
print(f"Training job {estimator.latest_training_job.name} started.")
print(f"Model artifacts will be saved to: {estimator.model_data}")Section 2: Practical Implementation: A Project Lifecycle Walkthrough
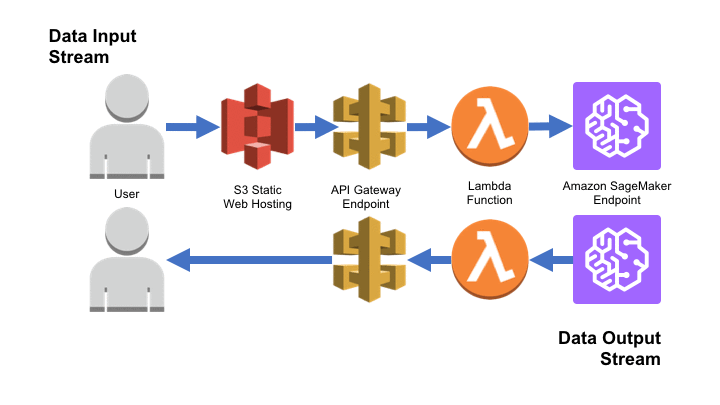
AWS SageMaker interface – Build a serverless frontend for an Amazon SageMaker endpoint …
Putting the concepts into practice reveals the true power of the unified studio. Let’s walk through a typical project lifecycle, from initial data exploration to model training, all within this new collaborative framework.
Setting Up a Collaborative Project
The journey begins with setting up a SageMaker Domain and adding users. From there, an administrator or team lead can create a shared Space for a new project. During creation, you can attach a Git repository URL, and SageMaker will automatically clone it into the Space’s shared EFS storage. Users added to the Space can then launch the Code Editor or JupyterLab application and immediately see the project files. This tight Git integration is crucial for version control and aligns with MLOps best practices, ensuring that all work is traceable and reproducible. This integrated approach stands as a compelling alternative to workflows on other platforms like Google Colab or Kaggle News, bringing enterprise-grade governance to the development process.
Interactive Data Exploration and Preprocessing
Once inside the Space, a data scientist can start a Jupyter notebook to explore the dataset. The SageMaker SDK, combined with libraries like Pandas and Boto3, makes it trivial to access data stored in Amazon S3. The underlying compute instance can be chosen on-demand, allowing you to use a cost-effective CPU instance for data wrangling and switch to a more powerful GPU instance later for training.
This example demonstrates loading data from S3 within a SageMaker notebook, a common first step in any ML project.
import boto3
import pandas as pd
import sagemaker
# Get the default S3 bucket for the SageMaker session
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket()
data_key = 'raw-data/customer-churn.csv'
data_location = f's3://{bucket}/{data_key}'
# Example: Download data from S3 to the local environment for analysis
s3_client = boto3.client('s3')
local_file_path = 'customer-churn-local.csv'
s3_client.download_file(bucket, data_key, local_file_path)
# Load the data into a pandas DataFrame
df = pd.read_csv(local_file_path)
# Perform some initial data exploration
print("Dataset Information:")
df.info()
print("\nFirst 5 rows of the dataset:")
print(df.head())
# After preprocessing, you can upload the processed data back to S3
processed_key = 'processed-data/churn-processed.csv'
df.to_csv(f's3://{bucket}/{processed_key}', index=False)
print(f"\nProcessed data uploaded to s3://{bucket}/{processed_key}")Training Models with Hugging Face and Other Frameworks
With preprocessed data ready, you can move on to model training. SageMaker Studio provides deep integration with leading frameworks. The latest Hugging Face Transformers News highlights the importance of easy-to-use training infrastructure, and SageMaker delivers this through its dedicated Hugging Face Deep Learning Containers (DLCs). You can define a `HuggingFace` estimator in your script, specify your model, hyperparameters, and training data, and launch a managed training job without ever leaving the IDE. This managed approach handles the complexities of provisioning compute, installing dependencies, and storing model artifacts, freeing up the developer to focus on the model itself.
Section 3: Advanced Techniques and Generative AI Workflows
The unified studio truly shines when tackling complex, modern ML challenges, particularly in the realm of generative AI. It serves as an ideal control plane for building sophisticated applications that leverage foundation models and vector databases.
Fine-Tuning Foundation Models from Hugging Face and Beyond

AWS SageMaker interface – Securing all Amazon SageMaker API calls with AWS PrivateLink …
Fine-tuning large language models (LLMs) from providers like Mistral AI, Meta AI (e.g., Llama models), or those on the Hugging Face Hub is a resource-intensive task. SageMaker Studio simplifies this by providing easy access to powerful GPU instances (like NVIDIA’s A100s or H100s) and optimized training environments. Using the SageMaker SDK, you can configure a distributed training job using libraries like DeepSpeed or FSDP with just a few lines of code. This integration is a key part of the latest NVIDIA AI News, which emphasizes making large-scale training accessible.
The following code snippet illustrates how to set up a fine-tuning job for a Hugging Face model. This script would be run from the Code Editor or a notebook within your SageMaker Space.
from sagemaker.huggingface import HuggingFace
import sagemaker
role = sagemaker.get_execution_role()
# S3 location of your training data
s3_input_train = "s3://your-bucket/path/to/training-data"
# Hyperparameters for the fine-tuning script
hyperparameters = {
'model_name_or_path': 'distilbert-base-uncased',
'output_dir': '/opt/ml/model',
'num_train_epochs': 3,
'per_device_train_batch_size': 16,
'learning_rate': 2e-5,
}
# Define the Hugging Face Estimator
huggingface_estimator = HuggingFace(
entry_point='run_glue.py', # Your fine-tuning script (e.g., from HF examples)
source_dir='./scripts/text-classification',
instance_type='ml.p3.2xlarge', # A powerful GPU instance
instance_count=1,
role=role,
framework_version='1.13.1', # Transformers version
pytorch_version='1.9.1', # PyTorch version
py_version='py38',
hyperparameters=hyperparameters
)
# Launch the fine-tuning job
huggingface_estimator.fit({'train': s3_input_train})
print(f"Fine-tuning job started. Model artifacts will be at: {huggingface_estimator.model_data}")Building RAG Applications with Amazon Bedrock and Vector Databases
Beyond fine-tuning, SageMaker Studio is the perfect environment for developing Retrieval-Augmented Generation (RAG) applications. You can use a SageMaker notebook to orchestrate the entire workflow:
- Use a sentence transformer model from Sentence Transformers News to generate embeddings for your document corpus.
- Store these embeddings in a managed vector database like Pinecone, Weaviate, or an open-source solution like Milvus or Qdrant running on AWS infrastructure.
- Write application logic that queries the vector database to retrieve relevant context.
- Pass that context along with the user’s prompt to a powerful foundation model via Amazon Bedrock News, which provides API access to models from Anthropic, Cohere, Stability AI, and more.
Frameworks like LangChain News and LlamaIndex News can be easily installed and used within the Studio environment to accelerate the development of these complex chains.
Section 4: Best Practices and Optimization
To maximize the benefits of the new SageMaker Studio, it’s essential to follow best practices for cost management, reproducibility, and performance.
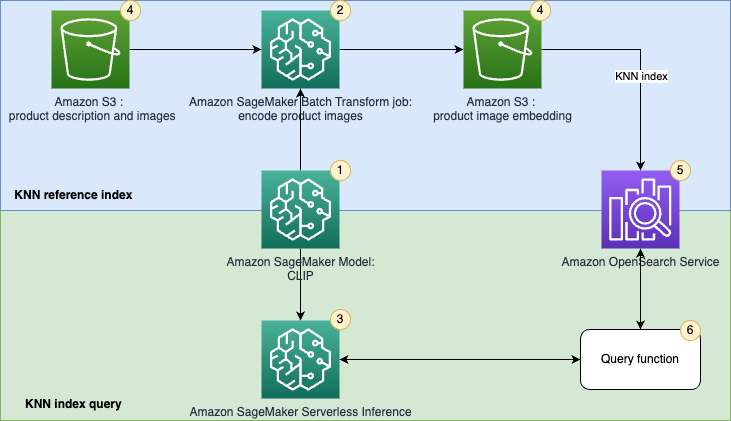
AWS SageMaker interface – Implement unified text and image search with a CLIP model using …
Managing Costs and Compute Resources
- Right-Sizing Instances: Always choose the most appropriate compute instance for your current task. Use smaller, CPU-based instances for coding and data prep, and only switch to expensive GPU instances when actively training or running inference.
- Lifecycle Configurations: Implement lifecycle configurations to automatically shut down apps and instances after a period of inactivity. This is a crucial step to prevent runaway costs.
- Leverage Managed Spot Training: For training jobs that can tolerate interruptions, use SageMaker’s Managed Spot Training to save up to 90% on compute costs.
Ensuring Reproducibility and Governance
- Version Everything with Git: The native Git integration in the Code Editor should be used extensively. Commit your code, notebooks, and configuration files regularly to ensure a complete history of your project.
- Codify Workflows with SageMaker Pipelines: For production-grade workflows, transition from notebooks to SageMaker Pipelines. This allows you to define your entire ML process as a directed acyclic graph (DAG), making it fully automated and reproducible.
- Integrate Experiment Tracking: While SageMaker has its own experiment tracking, you can also integrate third-party tools. The latest MLflow News and Weights & Biases News show a trend towards platform-agnostic tracking, which can be implemented by running their client libraries from the Studio terminal.
Optimizing for Inference
Once a model is trained, SageMaker Studio can be used to prepare it for deployment. This involves optimizing the model for low latency and high throughput. You can use open standards like ONNX News or tools like TensorRT to compile and quantize your model. For deployment, SageMaker offers a variety of hosting options, including real-time endpoints that can be backed by high-performance servers like the Triton Inference Server, ensuring your application can scale to meet demand.
Conclusion: The Future of Integrated ML Development
The new Amazon SageMaker Unified Studio represents a significant step towards solving the fragmentation problem in machine learning development. By providing a single, collaborative hub that integrates a professional-grade code editor, enhanced notebooks, and seamless access to the entire AWS ecosystem, it empowers teams to build faster and more efficiently. This unified approach directly addresses the needs of modern AI development, from traditional machine learning to complex generative AI applications built with Amazon Bedrock.
As the ML landscape continues to evolve, with constant developments from Google DeepMind News, Meta AI News, and the open-source community, having a flexible and powerful development platform is no longer a luxury but a necessity. Compared to offerings like Vertex AI or Azure Machine Learning News, SageMaker’s deep focus on a unified, VS Code-based IDE for the full ML lifecycle is a compelling differentiator. For teams looking to streamline their workflows, enhance collaboration, and accelerate their path from idea to production, exploring the new SageMaker Studio is a worthwhile and strategic next step.


