
How to Build an Interactive AI Agent with Streamlit and LLM Function Calling
Introduction: Beyond Text Generation to Actionable AI
Large Language Models (LLMs) have fundamentally changed our interaction with technology. We’ve moved beyond simple chatbots to sophisticated AI that can understand, reason, and generate human-like text. However, the true revolution begins when these models can do more than just talk—when they can take action. This is the world of “function calling,” or tool use, a paradigm that empowers LLMs to interact with external systems, APIs, and databases. By translating natural language requests into executable code, LLMs can fetch real-time data, control smart devices, or perform complex calculations, transforming them from passive text generators into active, problem-solving agents.
Building a user-friendly interface for these powerful agents is crucial for their adoption. This is where Streamlit shines. As a Python framework designed for rapid development of data and AI applications, Streamlit allows developers to create interactive web UIs with minimal code. It’s the perfect partner for an LLM agent, providing the conversational front-end that makes complex backend operations accessible. In this comprehensive guide, we will walk through the process of building a Streamlit application that leverages an LLM’s function-calling capabilities to create a dynamic and interactive AI agent that can call custom tools in response to user prompts.
Understanding the Core Components: LLMs, Tools, and Streamlit
Before diving into the code, it’s essential to understand the three pillars of our application: the Language Model that provides the reasoning engine, the tools (functions) it can use, and the Streamlit framework that presents it all to the user. This combination is a frequent topic in recent Streamlit News and AI development circles.
What is Function Calling?
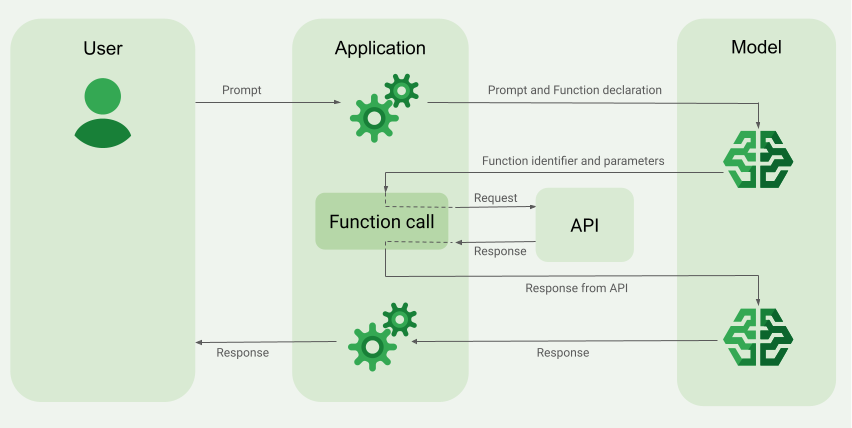
Function calling is a mechanism that allows an LLM to request the execution of a specific function when it determines that an external tool is needed to fulfill a user’s request. The process is a multi-step conversation between your application and the model:
- User Prompt: The user asks a question like, “What’s the weather like in Tokyo?”
- Model Analysis: The LLM receives the prompt along with a list of available “tools” (e.g., a
get_weatherfunction). It analyzes the prompt and recognizes that it needs to use the weather tool. - Function Call Generation: Instead of answering directly, the model generates a structured JSON object specifying the function to call (
get_weather) and the required arguments ({"location": "Tokyo"}). - Application Execution: Your Python application receives this JSON, parses it, and executes the actual
get_weather("Tokyo")function. - Result Submission: The return value from the function (e.g., “The weather in Tokyo is 25°C and sunny.”) is sent back to the LLM.
- Final Response: The LLM uses this new information to formulate a natural, human-readable response to the user, such as, “The current weather in Tokyo is 25°C and sunny.”
This elegant loop, a major focus of recent OpenAI News and Anthropic News, allows the LLM to access live data and perform actions without being explicitly trained on how to execute the code itself.
Choosing Your LLM and Frameworks
Several models excel at function calling, including OpenAI’s GPT series, Google’s Gemini, and Anthropic’s Claude 3 family. Open-source alternatives like Llama 3 and models from Mistral AI are also becoming increasingly capable, especially when served through high-performance inference engines like vLLM News or platforms like Groq, Replicate, or a local Ollama News setup. For orchestrating the complex logic of agentic workflows, frameworks featured in LangChain News and LlamaIndex News provide powerful abstractions that can significantly simplify development.
Why Streamlit for the UI?

While you could build a backend with FastAPI News or Flask, Streamlit offers unparalleled speed for creating interactive UIs. Its simple, script-like structure and built-in widgets are perfect for building chat interfaces. Crucially, its session state management (st.session_state) makes it easy to maintain conversational history, which is essential for any chatbot or AI agent. It provides a faster path to a working prototype than alternatives often discussed in Gradio News or Chainlit News.
Let’s start with a basic Streamlit app structure to get our feet wet.
import streamlit as st
# Set the title of the app
st.title("My First AI Agent App")
# A simple text input widget
user_input = st.text_input("Ask me anything!")
if user_input:
# For now, we'll just echo the input
st.write(f"You asked: {user_input}")Step-by-Step: Building Your First Tool-Using Agent
Now, let’s build the core logic of our agent. We’ll define a set of tools, create the schemas that describe them to the LLM, and implement the main interaction loop that handles the conversation.
Defining Your Tools and Their Schemas
First, we need some Python functions that our agent can call. These are our “tools.” Let’s create two simple tools: one to get the current weather and another to get the latest headlines on a topic. For this example, we’ll use placeholder functions, but in a real-world application, these would call external APIs.
Next, and most importantly, we must describe these functions to the LLM using a specific format, typically JSON Schema. This schema tells the model the function’s name, its purpose, and the parameters it accepts, including their types and descriptions. A clear description is critical for the model to know when and how to use the tool.
import json
# 1. Define the actual Python functions (our tools)
def get_current_weather(location: str, unit: str = "celsius"):
"""
Get the current weather in a given location.
Args:
location (str): The city and state, e.g., "San Francisco, CA"
unit (str): The unit of temperature, either "celsius" or "fahrenheit"
"""
# In a real app, this would call a weather API
weather_info = {
"location": location,
"temperature": "22",
"unit": unit,
"forecast": ["sunny", "windy"],
}
return json.dumps(weather_info)
def get_latest_news(topic: str):
"""
Get the latest news headlines for a given topic.
Args:
topic (str): The topic to search for news, e.g., "AI" or "NVIDIA AI News"
"""
# In a real app, this would call a news API
news_info = {
"topic": topic,
"headlines": [
f"Major breakthrough in {topic} announced.",
f"New developments in {topic} are changing the industry.",
]
}
return json.dumps(news_info)
# 2. Create a dictionary to map tool names to functions
available_tools = {
"get_current_weather": get_current_weather,
"get_latest_news": get_latest_news,
}
# 3. Define the schemas for the LLM
tools_schemas = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
},
},
{
"type": "function",
"function": {
"name": "get_latest_news",
"description": "Get the latest news headlines for a given topic",
"parameters": {
"type": "object",
"properties": {
"topic": {
"type": "string",
"description": "The topic to search for news, e.g., 'AI research' or 'PyTorch News'",
},
},
"required": ["topic"],
},
},
}
]This code defines our functions and creates the corresponding schemas. The schemas are highly detailed, which helps the LLM make accurate and reliable function calls. The quality of your function descriptions is a key part of prompt engineering for tool use.
Integrating the Agent into a Streamlit UI
With our tools defined, we can now build the full Streamlit application. This involves setting up the chat interface, managing the conversation history using st.session_state, and implementing the core logic that communicates with the LLM and executes tool calls.
Managing Conversational State and Building the Chat Interface
A conversation is a sequence of messages. We need to store this history so that the LLM has context for follow-up questions. Streamlit’s st.session_state is a dictionary-like object that persists across reruns, making it perfect for this task. We’ll initialize a list called messages in the session state to hold the conversation. The UI will then iterate through this list to display the chat history and use st.chat_input to get new user input.
The following example puts everything together. It uses the OpenAI Python client, but the logic is adaptable to any API that supports function calling. Remember to set your API key as a Streamlit secret.
import streamlit as st
import openai
import json
# --- Tool Definitions (from the previous section) ---
def get_current_weather(location: str, unit: str = "celsius"):
"""Get the current weather in a given location."""
weather_info = {
"location": location, "temperature": "22", "unit": unit,
"forecast": ["sunny", "windy"],
}
return json.dumps(weather_info)
def get_latest_news(topic: str):
"""Get the latest news headlines for a given topic."""
news_info = {
"topic": topic, "headlines": [f"Major breakthrough in {topic} announced.", f"New developments in {topic} are changing the industry."]
}
return json.dumps(news_info)
# --- Main Application Logic ---
st.title("🤖 AI Agent with Function Calling")
st.caption("Powered by Streamlit and OpenAI")
# Set up OpenAI client
client = openai.OpenAI(api_key=st.secrets["OPENAI_API_KEY"])
# Initialize session state for messages if not already present
if "messages" not in st.session_state:
st.session_state.messages = []
# Display past messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Get user input
if prompt := st.chat_input("What's the weather in London or the latest TensorFlow News?"):
# Add user message to session state and display it
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# --- Core Agent Logic ---
# 1. Send the conversation and available functions to the model
response = client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=st.session_state.messages,
tools=tools_schemas,
tool_choice="auto",
)
response_message = response.choices[0].message
# 2. Check if the model wants to call a tool
if response_message.tool_calls:
# Add the assistant's response (the tool call request) to the history
st.session_state.messages.append(response_message)
# Map tool names to functions
available_tools = {
"get_current_weather": get_current_weather,
"get_latest_news": get_latest_news,
}
# 3. Execute the tool calls
for tool_call in response_message.tool_calls:
function_name = tool_call.function.name
function_to_call = available_tools[function_name]
function_args = json.loads(tool_call.function.arguments)
# Call the function with the provided arguments
function_response = function_to_call(**function_args)
# Add the tool's response to the conversation history
st.session_state.messages.append(
{
"tool_call_id": tool_call.id,
"role": "tool",
"name": function_name,
"content": function_response,
}
)
# 4. Send the tool response back to the model for a final summary
second_response = client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=st.session_state.messages,
)
final_message = second_response.choices[0].message
st.session_state.messages.append(final_message)
with st.chat_message("assistant"):
st.markdown(final_message.content)
else:
# The model responded directly without a tool call
st.session_state.messages.append(response_message)
with st.chat_message("assistant"):
st.markdown(response_message.content)Advanced Techniques and Best Practices
Building a basic agent is a great start, but creating a robust, production-ready application requires more nuance. Here are some best practices and advanced techniques to consider.
Error Handling and Fallbacks
What happens if an API call fails or a tool encounters an unexpected error? Your application should handle this gracefully. Wrap your tool execution in try...except blocks. If an error occurs, you can report it back to the LLM. The model is often smart enough to understand the error and inform the user, or even try a different approach.
Caching for Performance and Cost Savings

API calls, especially to LLMs and external services, can be slow and costly. Streamlit’s caching primitives are invaluable for optimization. You can use @st.cache_data to cache the results of functions that return data, like our tool functions. This means if the user asks the same question twice (e.g., “What’s the weather in Tokyo?”), the API won’t be called a second time; instead, the cached result will be returned instantly. For resources that should be loaded only once, like a machine learning model, use @st.cache_resource.
Here is how you can add caching and error handling to a tool:
import streamlit as st
import requests # Example for a real API call
import json
@st.cache_data(ttl=600) # Cache the result for 10 minutes (600 seconds)
def get_current_weather_with_caching(location: str, unit: str = "celsius"):
"""
Get the current weather in a given location with error handling and caching.
"""
try:
# In a real app, you would make an API call here.
# This is a placeholder for that logic.
if location.lower() == "error city":
raise requests.exceptions.RequestException("API connection failed")
weather_info = {
"location": location,
"temperature": "22",
"unit": unit,
"forecast": ["sunny", "windy"],
}
return json.dumps(weather_info)
except Exception as e:
# If an error occurs, return a descriptive error message.
# The LLM can use this to inform the user.
error_message = {"error": f"Failed to get weather for {location}", "details": str(e)}
return json.dumps(error_message)
# You would then map "get_current_weather" to this new, robust function.
Deployment and Scaling
Once your application is ready, you can deploy it easily using Streamlit Community Cloud. For more complex needs, you can containerize your app and deploy it on cloud platforms, a topic frequently covered in Azure AI News or in discussions around AWS SageMaker News. For scaling LLM inference, especially for open-source models, solutions like Modal News, Anyscale Ray, or using dedicated hardware discussed in NVIDIA AI News can provide the necessary performance. Integrating with MLOps platforms like MLflow or Weights & Biases, often featured in MLflow News, can also help track experiments and model performance.
Conclusion: The Future is Interactive
We’ve journeyed from the concept of LLM function calling to building a fully functional, interactive AI agent with a Streamlit front-end. You’ve learned how to define tools, describe them to an LLM, manage conversational state, and implement the core logic that enables your AI to take action in the real world. By incorporating best practices like error handling and caching, you can create applications that are not only powerful but also robust and efficient.
The fusion of conversational AI with tool use is one of the most exciting frontiers in technology. As models become more capable and frameworks like Streamlit make development more accessible, we will see a new generation of AI applications that are more helpful, dynamic, and integrated into our daily workflows. The next step is yours: experiment with different tools, connect to your own APIs, explore more advanced agentic architectures, and build the next great AI application.


