Scaling Data Analytics to Petabytes: A Deep Dive into Dask and RAPIDS cuDF
In the era of big data, data scientists and machine learning engineers frequently encounter datasets that are too large to fit into the memory of a single machine. Traditional tools like Pandas, while excellent for in-memory analytics, quickly become a bottleneck when faced with tens or hundreds of gigabytes of data. This challenge has spurred the development of powerful distributed computing frameworks. Among the most promising solutions in the Python ecosystem is the combination of Dask for parallel execution and RAPIDS cuDF for GPU-accelerated data manipulation.
Dask provides a flexible library for parallel computing in Python, extending familiar APIs like NumPy and Pandas to work on larger-than-memory datasets across multiple cores or machines. RAPIDS cuDF, part of the NVIDIA AI ecosystem, reimagines the DataFrame on the GPU, offering a Pandas-like API that leverages the massive parallelism of modern GPUs for unprecedented data processing speed. When combined, Dask and cuDF create a formidable toolchain that allows users to scale their data analytics workflows seamlessly from a single GPU to a multi-node cluster, all without leaving the comfort of the Python environment. This article provides a comprehensive technical guide to harnessing the power of Dask cuDF for high-performance data science.
The Power Couple: Understanding Dask and cuDF
To fully appreciate the synergy between Dask and cuDF, it’s essential to understand what each component brings to the table. They are not just tools but a paradigm shift in how we approach large-scale data processing in Python, a topic frequently discussed in the latest Dask News and NVIDIA AI News.
What is Dask? The Engine of Parallelism
At its core, Dask is a dynamic task scheduler. It works by breaking down large computations into smaller, manageable tasks and arranging them into a dependency graph. These tasks are then executed in parallel across available resources, whether it’s the multiple cores on your laptop or a distributed cluster of machines. A key feature of Dask is its “lazy evaluation” model. When you write Dask code, you are not immediately executing the computation; you are building a task graph. The computation is only triggered when you explicitly call a method like .compute().
For data scientists, the most relevant component is the Dask DataFrame. A Dask DataFrame is a large, virtual DataFrame composed of many smaller cuDF (or Pandas) DataFrames, called partitions. This partitioning allows Dask to operate on datasets that don’t fit into memory, processing one partition at a time or many in parallel.
Introducing RAPIDS cuDF: DataFrames on Steroids
RAPIDS cuDF is a Python GPU DataFrame library built on the Apache Arrow columnar memory format. Its primary goal is to provide a Pandas-like API that executes operations on NVIDIA GPUs. Because GPUs are designed with thousands of cores, they can perform many identical operations simultaneously (SIMD – Single Instruction, Multiple Data). This makes them exceptionally well-suited for the vectorized, columnar operations common in data analytics, such as filtering, arithmetic, and aggregations. By moving data and computation to the GPU, cuDF can achieve speedups of 10-100x over equivalent CPU-based workflows with Pandas.
Dask + cuDF: The Ultimate Synergy
When Dask orchestrates cuDF DataFrames, it creates a dask_cudf.DataFrame. In this setup, each partition of the Dask DataFrame is a cuDF DataFrame residing in the memory of a specific GPU. Dask manages the distribution of these partitions and schedules the execution of cuDF operations across one or more GPUs. This powerful combination allows you to:

- Process datasets that are larger than the memory of a single GPU.
- Leverage multiple GPUs on a single machine or across a cluster.
- Maintain a familiar, high-level API for complex, distributed computations.
import cudf
import dask_cudf
import numpy as np
# Create a single cuDF DataFrame on the GPU
gdf = cudf.DataFrame({
'x': np.random.randint(0, 100, size=10000),
'y': np.random.rand(10000)
})
# Create a Dask cuDF DataFrame from the cuDF DataFrame
# In a real scenario, you'd typically read from files
# npartitions=4 means Dask will split this into 4 partitions
ddf = dask_cudf.from_cudf(gdf, npartitions=4)
# The Dask DataFrame is a collection of cuDF DataFrames
print(f"Type of the Dask DataFrame: {type(ddf)}")
print(f"Type of a single partition: {type(ddf.get_partition(0).compute())}")
# Describe the structure of the Dask DataFrame
print(ddf)Getting Hands-On: A Practical Implementation Guide
Theory is one thing, but the real power of Dask cuDF becomes apparent through practical application. This section walks through setting up your environment and performing common data manipulation tasks. Platforms like those featured in Google Colab News and Kaggle News often provide free access to GPUs, making it easy to get started.
Setting Up Your Environment
The recommended way to install Dask, cuDF, and the entire RAPIDS suite is through Conda. This ensures all the necessary CUDA toolkit dependencies are correctly managed.
First, create and activate a new conda environment:
conda create -n rapids-24.06 -c rapidsai -c conda-forge \
-c nvidia rapids=24.06 python=3.10 cudatoolkit=12.0
conda activate rapids-24.06This single command installs everything you need, including Dask, cuDF, and other RAPIDS libraries like cuML for machine learning.
Data Loading and Basic Operations
The most common entry point for a Dask cuDF workflow is reading data from a distributed file system like S3, GCS, or your local disk. For optimal performance, it’s highly recommended to use a column-oriented file format like Apache Parquet.
Let’s see how to read a Parquet file and perform a simple calculation. Notice how the code mirrors the Pandas API.
import dask_cudf
import dask.distributed
# It's a best practice to start a Dask cluster
# LocalCUDACluster sets up a scheduler and workers on the GPUs of a single machine
cluster = dask.distributed.LocalCUDACluster()
client = dask.distributed.Client(cluster)
# Create a sample dataset (for demonstration purposes)
# In a real-world scenario, you would have a large dataset already
import pandas as pd
df = pd.DataFrame({
'category': ['A', 'B', 'C'] * 1000000,
'value': range(3000000)
})
df.to_parquet('sample_data.parquet', engine='pyarrow', index=False)
# Read the Parquet file into a Dask cuDF DataFrame
# Dask automatically infers a reasonable number of partitions
ddf = dask_cudf.read_parquet('sample_data.parquet')
# This is a lazy operation; it just builds the task graph
mean_value = ddf['value'].mean()
print("Task graph for the mean calculation:")
print(mean_value)
# The .compute() method triggers the actual execution on the GPUs
result = mean_value.compute()
print(f"\nThe computed mean value is: {result}")
# Don't forget to close the client and cluster
client.close()
cluster.close()In this example, ddf['value'].mean() doesn’t immediately calculate the mean. Instead, it creates a graph of tasks: “read each partition of the Parquet file,” “get the ‘value’ column from each partition,” “calculate the sum and count for each partition,” and finally, “aggregate the sums and counts to compute the final mean.” The entire graph is executed in parallel across the GPUs only when .compute() is called.
Advanced Techniques and Real-World Applications
Beyond basic aggregations, Dask cuDF excels in complex data preparation and integration with machine learning pipelines. This is where it truly shines, connecting data engineering with advanced analytics and forming a critical component in modern MLOps stacks, often discussed alongside tools from MLflow News or platforms like AWS SageMaker News.
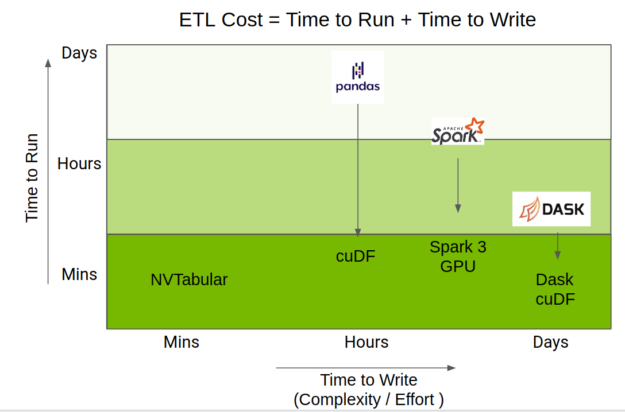
Complex Transformations: GroupBy and Joins
Operations like groupby-aggregate are computationally intensive and benefit immensely from GPU acceleration. Dask distributes the groupby operation by performing it on each partition locally first and then shuffling the intermediate results between workers to compute the final aggregation.
import dask_cudf
import dask.distributed
# Assuming client and cluster are running
client = dask.distributed.Client()
# Read the data created in the previous example
ddf = dask_cudf.read_parquet('sample_data.parquet')
# Perform a groupby-aggregation
# This is a lazy operation
grouped_data = ddf.groupby('category').agg({
'value': ['mean', 'std', 'count']
}).reset_index()
print("Task graph for the groupby operation:")
print(grouped_data)
# Execute the computation
result_agg = grouped_data.compute()
print("\nAggregated results:")
print(result_agg)
# Clean up
client.close()Integration with GPU-Accelerated Machine Learning
The RAPIDS ecosystem is more than just cuDF. It includes cuML, a library of GPU-accelerated machine learning algorithms with a Scikit-learn-like API. Dask cuDF DataFrames can be passed directly to Dask-enabled cuML models, allowing you to build end-to-end, GPU-native machine learning pipelines without ever moving data back to the CPU.
This seamless integration is a game-changer, bridging the gap between data preparation and model training. It’s a key development that often features in PyTorch News and TensorFlow News, as data preprocessing is a critical precursor to deep learning workflows.
import dask_cudf
import dask.distributed
from cuml.dask.cluster import KMeans
from cuml.dask.datasets import make_blobs
# Assuming client and cluster are running
client = dask.distributed.Client()
# Generate a large sample dataset directly on the GPUs
X, y = make_blobs(n_samples=1000000,
n_features=20,
centers=5,
n_parts=4, # Distribute across 4 partitions
random_state=42)
print("Dataset created with Dask arrays.")
print(f"Number of partitions: {X.npartitions}")
# Initialize a Dask-enabled KMeans model from cuML
# The model will train in a distributed fashion across the GPUs
kmeans_model = KMeans(n_clusters=5, random_state=42)
kmeans_model.fit(X)
print("\nKMeans model training complete.")
print("Cluster centers found:")
# The cluster centers are a small result, so we can compute() them to view
print(kmeans_model.cluster_centers_)
# Clean up
client.close()Best Practices, Pitfalls, and Optimization
To get the most out of Dask cuDF, it’s crucial to follow best practices and be aware of common pitfalls. These tips are essential for building robust and performant data pipelines.
Best Practices
- Use Columnar File Formats: Always prefer Apache Parquet or ORC. They allow Dask to read only the necessary columns, significantly reducing I/O.
- Mind Your Partitions: The size and number of partitions are critical. Aim for partition sizes between 100MB and 1GB. Too many small partitions create scheduler overhead, while too few large partitions can lead to memory issues and limit parallelism. Use
ddf.repartition()if necessary, but be aware it can trigger an expensive data shuffle. - Chain Operations: Leverage Dask’s lazy evaluation by chaining as many operations as possible before calling
.compute(). This allows Dask’s optimizer to build a more efficient execution graph. - Persist Intermediate Results: If you need to reuse an intermediate result multiple times, use
client.persist(). This computes the result and keeps it distributed in GPU memory, avoiding redundant computation.
Common Pitfalls
- Expensive Shuffles: Operations that require comparing data across all partitions, such as setting a new, unsorted index (
set_index) or certain types of joins, trigger a “shuffle.” This involves moving large amounts of data between GPUs and can be a major bottleneck. Visualize your task graph with the Dask dashboard to identify these steps. - CPU-GPU Data Transfer: Moving data between the host (CPU) and the device (GPU) is slow. The goal of a Dask cuDF pipeline is to keep data on the GPU from start to finish. Avoid mixing Pandas and cuDF operations unnecessarily.
- Using
.compute()Too Early: Calling.compute()on a large intermediate result can pull all the data back to the client’s memory, causing an out-of-memory error. Only call.compute()on small, final results.
For more advanced monitoring and optimization, tools featured in Weights & Biases News or ClearML News can be integrated to track experiment metrics, while frameworks discussed in Ray News offer alternative approaches to distributed execution that can complement Dask in larger systems.
Conclusion: The Future of Scalable Data Science
The combination of Dask and RAPIDS cuDF represents a significant leap forward for the Python data science ecosystem. It provides a scalable, high-performance, and user-friendly solution for tackling larger-than-memory datasets, effectively democratizing GPU-accelerated computing for data analytics. By adhering to a familiar Pandas-like API, it lowers the barrier to entry for distributed computing, allowing data scientists to focus on solving problems rather than managing complex infrastructure.
The key takeaways are clear: Dask provides the intelligent scheduling and distributed execution engine, while cuDF delivers raw computational speed by leveraging GPU parallelism. Together, they enable you to build end-to-end pipelines—from data ingestion and ETL to machine learning—that run entirely on GPUs, delivering orders-of-magnitude performance improvements over traditional CPU-based workflows.
As datasets continue to grow, mastering tools like Dask and cuDF will become an essential skill. The next step is to explore them for yourself. Start with a project on a platform like Kaggle or Google Colab, dive into the rich documentation provided by the Dask and RAPIDS communities, and begin scaling your data science workflows to new heights.


