
The Future of the AI Stack: Analyzing the Convergence of MLOps and Specialized Infrastructure
The artificial intelligence landscape is undergoing a period of rapid consolidation and vertical integration. The days of siloed development, where software tools and hardware infrastructure were chosen independently, are evolving. A significant development in this trend is the recent news of AI hyperscaler CoreWeave acquiring the leading MLOps platform, Weights & Biases. This move signals a paradigm shift, creating a tightly integrated, full-stack platform designed to streamline the entire machine learning lifecycle, from initial experimentation to large-scale production deployment. For developers, data scientists, and MLOps engineers, this convergence has profound implications, promising enhanced performance, simplified workflows, and a more cohesive development experience.
This article delves into the technical significance of this industry development. We will explore the core functionalities of an MLOps platform like Weights & Biases, demonstrate its practical application with code examples, and analyze how its integration with a specialized AI cloud provider creates a powerful synergy. We will cover how this impacts everything from training models with PyTorch News and TensorFlow News to deploying complex applications built with LangChain News and Hugging Face Transformers News, offering a comprehensive look at the future of the AI development stack.
Section 1: The Core Pillars: MLOps and GPU-Accelerated Cloud
To understand the impact of this convergence, it’s essential to first grasp the distinct yet complementary roles of MLOps platforms and specialized AI cloud infrastructure. They represent two critical pillars supporting modern AI development.
What is Weights & Biases? The MLOps Control Panel
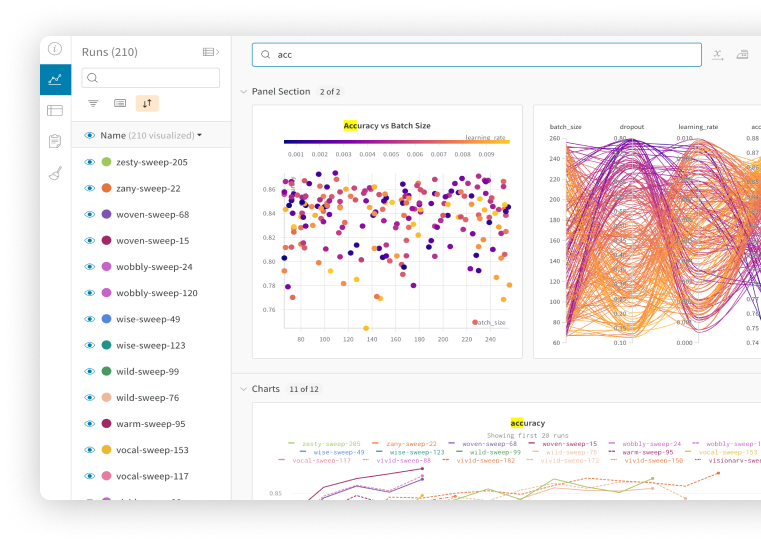
Weights & Biases (W&B) is a developer-first MLOps platform designed to be the system of record for machine learning projects. It addresses the chaotic nature of ML experimentation by providing tools for:
- Experiment Tracking: Automatically logging metrics (like loss and accuracy), hyperparameters, and system resource usage (GPU, CPU) during training runs.
- Data & Model Versioning: Using W&B Artifacts to store and version datasets, model weights, and even evaluation results, ensuring reproducibility and lineage.
- Hyperparameter Optimization: Running automated sweeps to systematically explore different hyperparameter combinations and find the optimal model configuration.
- Collaboration & Reporting: Creating interactive dashboards, visualizations, and reports to share findings with team members and stakeholders.
At its heart, W&B integrates seamlessly into existing training scripts. Consider a standard model training loop in PyTorch. Integrating W&B requires just a few lines of code to capture a wealth of information that would otherwise be lost in terminal logs.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
import wandb
# 1. Initialize a new W&B run
wandb.init(
project="pytorch-mnist-example",
config={
"learning_rate": 0.01,
"architecture": "CNN",
"dataset": "MNIST",
"epochs": 10,
}
)
# Capture the config for this run
config = wandb.config
# Define a simple CNN model
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = torch.relu(x)
x = self.conv2(x)
x = torch.relu(x)
x = torch.max_pool2d(x, 2)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
output = torch.log_softmax(x, dim=1)
return output
# Setup data loaders, model, optimizer, etc.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST('../data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
model = SimpleCNN().to(device)
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
criterion = nn.CrossEntropyLoss()
# 2. Track the model with W&B
wandb.watch(model, log="all", log_freq=10)
# Training loop
for epoch in range(config.epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
# 3. Log metrics to W&B
wandb.log({"epoch": epoch, "loss": loss.item()})
print(f"Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.6f}")
# 4. Finish the run
wandb.finish()The Role of a Specialized AI Cloud
While W&B organizes the “what” and “why” of an experiment, a provider like CoreWeave supplies the “where” and “how.” Specialized AI clouds are built from the ground up for the unique demands of large-scale AI workloads. Unlike general-purpose clouds, they offer a highly optimized stack, including the latest NVIDIA AI News-making GPUs, low-latency networking, and high-performance storage, all crucial for training massive models from hubs like Hugging Face News or foundation models from labs like OpenAI News, Anthropic News, and Mistral AI News.
Section 2: The Synergy: A Vertically Integrated AI Development Platform
The acquisition of an MLOps leader by an infrastructure specialist creates a vertically integrated stack where the software and hardware layers are deeply intertwined. This synergy unlocks new efficiencies and capabilities that are difficult to achieve when using disparate services.

Streamlined Workflows and Optimized Performance
Imagine a scenario where your MLOps platform is native to your cloud provider. This eliminates friction points and opens up performance optimization opportunities:
- Pre-configured Environments: Developers can spin up compute instances with development tools like Google Colab News-style notebooks or VS Code, with W&B clients and necessary drivers (like CUDA) pre-installed and optimized for the underlying hardware.
- High-Speed Data Access: W&B Artifacts, which store datasets and model checkpoints, can reside on the same high-performance storage network as the compute nodes. This dramatically reduces data transfer times, a significant bottleneck when working with terabyte-scale datasets.
- Integrated Scheduling: Hyperparameter sweeps and distributed training jobs, managed through W&B, can be scheduled more intelligently by directly communicating with the infrastructure’s resource manager. This is especially powerful when using tools like Ray News or DeepSpeed News for large-scale training.
Automating Hyperparameter Tuning with W&B Sweeps
Hyperparameter tuning is a perfect example of a workflow that benefits from tight integration. W&B Sweeps automates the process of finding the best hyperparameters for a model. A developer defines a search space in a YAML file, and the W&B agent coordinates multiple runs to explore this space.
Here is an example of a sweep configuration file:
program: train.py
method: bayes
metric:
name: validation_accuracy
goal: maximize
parameters:
learning_rate:
distribution: uniform
min: 0.0001
max: 0.1
optimizer:
values: ["adam", "sgd"]
dropout:
distribution: uniform
min: 0.2
max: 0.5
batch_size:
values: [32, 64, 128]On an integrated platform, a developer could launch this sweep, and the system would automatically provision the necessary GPU instances, run the training jobs in parallel, and stream the results back to a central W&B dashboard for real-time analysis. This is a significant improvement over manually managing infrastructure on platforms like AWS SageMaker News or Azure Machine Learning News, where connecting the MLOps tool to the compute can require more configuration.
Section 3: Advanced Workflows and the Broader AI Ecosystem
The impact of this integration extends beyond basic training loops. It accelerates advanced workflows like model evaluation, CI/CD for ML, and production deployment, positioning the combined platform as a central hub in the AI ecosystem.
Model Registry and CI/CD for ML
A robust MLOps strategy requires a reliable system for versioning, promoting, and deploying models. W&B Artifacts serves as a model registry, providing a clear lineage from the code and data that produced a model to its performance on various evaluation sets.
Consider a workflow where a new model is trained. It can be logged as an Artifact, automatically triggering an evaluation pipeline. If the model passes predefined quality gates (e.g., accuracy > 98%), it can be promoted to a “production-ready” alias.
import wandb
import torch
# Assume 'model' is our trained PyTorch model
# and 'run' is our active W&B run object
# 1. Save the model state
model_path = "cnn_model.pth"
torch.save(model.state_dict(), model_path)
# 2. Create a W&B Artifact for the model
artifact = wandb.Artifact(
name='mnist-cnn',
type='model',
description='A simple CNN model for MNIST classification',
metadata={"architecture": "SimpleCNN", "framework": "PyTorch"}
)
artifact.add_file(model_path)
# 3. Log the artifact to the W&B project
run.log_artifact(artifact)
print("Model logged as an artifact to Weights & Biases.")
# Later, you can promote this model in the W&B UI or via the API
# For example, adding an alias like 'production' or 'best-accuracy'
# api = wandb.Api()
# artifact = api.artifact('my-team/my-project/mnist-cnn:latest')
# artifact.aliases.append('production')
# artifact.save()This CI/CD pipeline becomes more powerful on an integrated platform. The “production” alias could trigger a deployment process that packages the model using a standard format like ONNX News and deploys it to an inference endpoint powered by NVIDIA’s Triton Inference Server News, all running on the same underlying cloud infrastructure. This reduces latency and simplifies the operational overhead compared to stitching together services from different vendors, such as MLflow News for tracking, Vertex AI News for serving, and a separate storage solution.
Powering the RAG and Generative AI Stack
The modern generative AI stack, particularly for Retrieval-Augmented Generation (RAG) applications, involves many moving parts. Frameworks like LangChain News and LlamaIndex News orchestrate calls to large language models, retrieve data from vector databases (like Pinecone News, Milvus News, or Chroma News), and process the results. Tracking the quality, cost, and latency of these complex chains is a significant challenge that MLOps tools are beginning to address with features like LangSmith News. By integrating W&B, developers can trace and debug these intricate pipelines, and the underlying infrastructure can provide optimized hosting for vector databases and LLM inference using tools like vLLM News.
Section 4: Best Practices and Future Considerations
As the industry moves towards these integrated platforms, developers should adapt their practices to maximize the benefits while being mindful of the potential trade-offs.
Embrace Reproducibility and Automation

The core promise of a platform like W&B is reproducibility. To leverage this, developers should:
- Log Everything: Don’t just log final metrics. Use W&B to log hyperparameters, code versions (via Git integration), system metrics, and, most importantly, link the exact data and model versions using Artifacts.
- Automate Evaluation: Create standardized evaluation jobs that run automatically when a new model artifact is logged. This ensures consistent and unbiased model comparison.
- Use Configuration Files: Define experiments and sweeps using configuration files (like YAML) rather than hardcoding parameters in scripts. This makes it easier to reproduce runs and launch new experiments.
Consider the Ecosystem and Portability
While vertical integration offers immense benefits, it also raises questions about vendor lock-in. A key best practice is to build for portability:
- Standardized Formats: Whenever possible, save models in open formats like ONNX News or Hugging Face’s `safetensors`. This provides an exit path if you need to migrate to a different serving environment.
- Containerize Your Code: Use Docker to package your training and inference code. This ensures that your application runs consistently across different environments, whether on-premise or on other clouds like Amazon Bedrock News or Azure AI News.
- Abstract Your MLOps Client: While W&B’s client is lightweight, consider wrapping its calls (`wandb.log`, `wandb.init`) in your own helper functions. This could make it easier to switch to another MLOps tool like Comet ML News or ClearML News in the future if necessary.
The competition in this space is fierce, with major cloud providers and startups all building comprehensive solutions. Keeping an eye on developments from Google DeepMind News, Meta AI News, and the offerings on Snowflake Cortex News will be crucial for making informed architectural decisions.
Conclusion: A New Era for AI Development
The convergence of a top-tier MLOps platform with a specialized AI cloud provider is more than just a business acquisition; it’s a technical statement about the future of AI development. It points to a world where the software layer that manages model development and the hardware layer that executes it are fused into a single, optimized, and cohesive platform. For developers, this means less time spent on infrastructure management and more time focused on building and iterating on models. The ability to seamlessly track an experiment, automate hyperparameter tuning, version datasets, and deploy models within one environment represents a significant leap in productivity.
As this integrated stack matures, we can expect to see even deeper optimizations that further accelerate the pace of innovation. This move sets a new standard for what a full-stack AI platform can be, challenging other players in the ecosystem, from major cloud providers to open-source tool maintainers, to deliver similarly streamlined and powerful developer experiences.


