
Next-Gen Audio Synthesis: Engineering Responsible Music AI with Stability AI Models
Introduction
The landscape of Generative AI is undergoing a seismic shift. While much of the past two years has been dominated by Large Language Models (LLMs)—a domain frequently covered in OpenAI News, Anthropic News, and Cohere News—the frontier is rapidly expanding into high-fidelity multimedia synthesis. Specifically, the domain of AI-generated music and audio is experiencing a renaissance, moving from experimental noise to production-grade composition tools. At the forefront of this evolution is the push for “Responsible AI,” a paradigm that emphasizes the ethical sourcing of training data, the protection of intellectual property, and the creation of tools that empower rather than replace human creativity.
Recent developments in Stability AI News highlight a strategic pivot towards collaborating with major rights holders to build models trained on licensed, high-quality datasets. This approach contrasts sharply with early “scrape-everything” methodologies. For developers and machine learning engineers, this signals a new era of architecture where model performance is inextricably linked to data provenance. Unlike Mistral AI News or Llama 3 updates that focus on textual reasoning, audio generation requires handling continuous waveforms, complex temporal dependencies, and high sampling rates.
In this comprehensive guide, we will explore the technical underpinnings of modern audio diffusion models, how to implement them using Python, and the engineering best practices for deploying responsible, high-fidelity music generation tools. We will also touch upon how this integrates with the broader ecosystem, including Hugging Face News and cloud infrastructure like AWS SageMaker News.
Section 1: The Architecture of Latent Diffusion for Audio
To understand how we generate responsible music, we must look under the hood of Latent Diffusion Models (LDMs). While Google DeepMind News often covers their proprietary models like Lyria, open-weight models from Stability AI usually follow a specific architectural pattern involving autoencoders and diffusion transformers (DiT) or U-Nets.
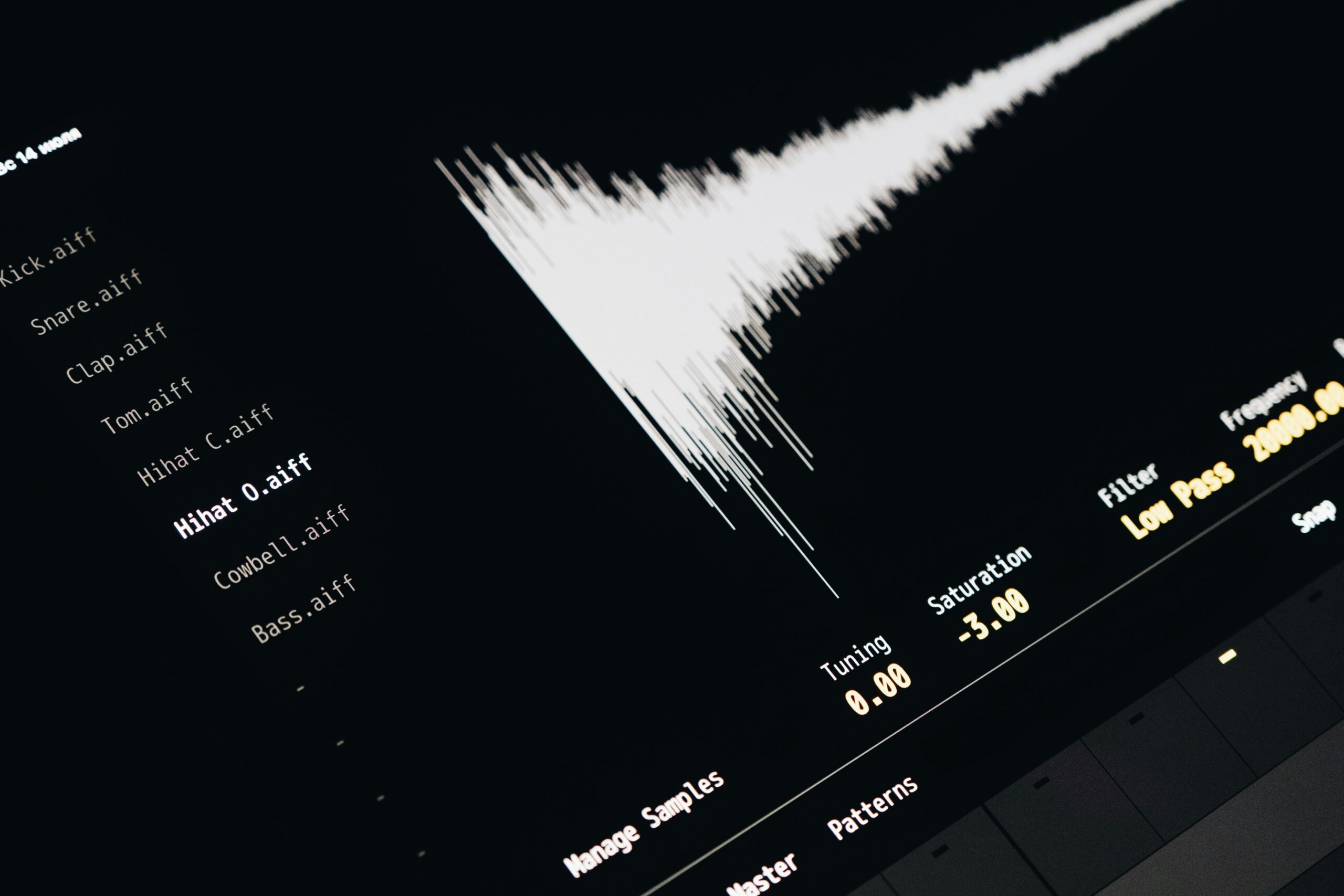
From Spectrograms to Latent Spaces
Audio is heavy. A standard 44.1kHz stereo file contains 88,200 data points per second. Training a diffusion model directly on raw waveforms is computationally prohibitive. Therefore, modern architectures utilize a Variational Autoencoder (VAE) to compress raw audio into a lower-dimensional “latent space.”
The process generally works as follows:
- Compression: The VAE compresses the audio into a latent representation.
- Conditioning: Text prompts are encoded using models like CLAP (Contrastive Language-Audio Pretraining) or T5 (often discussed in Hugging Face Transformers News).
- Diffusion: A U-Net or Transformer removes noise from the latent representation, guided by the text conditioning.
- Reconstruction: The VAE decoder converts the denoised latents back into audible waveforms.
This is distinct from approaches seen in Meta AI News regarding AudioCraft, though the fundamental principles of compression overlap. Let’s look at how to initialize a basic environment for audio generation using PyTorch.
import torch
from diffusers import StableAudioPipeline
import torchaudio
# Check for GPU availability - Essential for Diffusion Models
# Similar to requirements often discussed in NVIDIA AI News
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
def load_audio_model(model_id):
"""
Loads a Stable Audio Open model from Hugging Face.
Ensures optimization with float16 for memory efficiency.
"""
try:
pipe = StableAudioPipeline.from_pretrained(
model_id,
torch_dtype=torch.float16 if device == "cuda" else torch.float32
)
pipe = pipe.to(device)
# Enable memory slicing for lower VRAM usage
# A technique often highlighted in PyTorch News for optimization
pipe.enable_attention_slicing()
return pipe
except Exception as e:
print(f"Failed to load model: {e}")
return None
# Example usage with a hypothetical checkpoint
model_id = "stabilityai/stable-audio-open-1.0"
pipeline = load_audio_model(model_id)In the code above, we utilize the diffusers library. This standardization allows developers to switch between models easily, a convenience often highlighted in Fast.ai News and Keras News. The use of float16 is critical; without it, consumer-grade GPUs would struggle to handle the VRAM requirements of high-fidelity audio models.
Section 2: Implementation of Controlled Music Generation
Artificial intelligence analyzing image – Convergence of artificial intelligence with social media: A …
Responsible AI isn’t just about the training data; it’s about control. Musicians require granular control over BPM, key, and instrumentation. Unlike ChatGPT or LangChain News agents that generate text, audio models need strict timing constraints.
Prompt Engineering for Audio
The conditioning mechanism relies heavily on how the model was trained. If the model was trained on a dataset with rich metadata (a hallmark of responsible datasets from music labels), the prompts can be highly specific. We can control the output by injecting timing embeddings or specific style descriptors.
Here is a practical implementation of a generation function that accepts a prompt, negative prompt, and duration constraints. This setup mirrors workflows found in Vertex AI News or Azure Machine Learning News pipelines.
import scipy.io.wavfile
import numpy as np
def generate_music_segment(pipe, prompt, negative_prompt, seconds=10, seed=42):
"""
Generates a music segment based on text prompts.
Args:
pipe: The loaded StableAudioPipeline
prompt: Positive description of the music
negative_prompt: What to avoid (e.g., 'low quality', 'noise')
seconds: Duration of the audio
seed: Random seed for reproducibility
"""
# Set generator for reproducibility - vital for scientific workflows
# often discussed in MLflow News and Weights & Biases News
generator = torch.Generator(device).manual_seed(seed)
# Define the audio end time in seconds (models often have a max limit)
audio_end_in_s = float(seconds)
print(f"Generating: '{prompt}'...")
output = pipe(
prompt,
negative_prompt=negative_prompt,
num_inference_steps=200, # Higher steps = better quality, slower inference
audio_end_in_s=audio_end_in_s,
num_waveforms_per_prompt=1,
generator=generator,
)
# Extract the audio tensor
audio = output.audios[0]
# Convert to standard format for saving
# Transpose to (samples, channels) for scipy
audio_np = audio.transpose(0, 1).cpu().float().numpy()
# Save the file
sample_rate = pipe.vae.sampling_rate
filename = f"generated_track_{seed}.wav"
scipy.io.wavfile.write(filename, sample_rate, audio_np)
print(f"Saved to {filename}")
return filename
# Execution
if pipeline:
prompt_text = "Lo-fi hip hop beat, 90 BPM, chill piano, vinyl crackle, high fidelity"
neg_text = "vocals, distortion, heavy metal, low bitrate"
generate_music_segment(pipeline, prompt_text, neg_text, seconds=30)This implementation demonstrates the core inference loop. However, in a production environment—perhaps orchestrated via Kubeflow or monitored with Datadog—you would wrap this in an API using FastAPI News or Flask News standards.
Integration with User Interfaces
For internal tools used by creative teams, command-line interfaces are insufficient. Integrating these models into web apps using Gradio News or Streamlit News libraries allows non-technical producers to interact with the model. The “Responsible” aspect here ensures that the UI includes guardrails, preventing the generation of copyrighted likenesses if the model wasn’t trained for it.
Section 3: Advanced Techniques: Audio-to-Audio and Watermarking
The partnership between AI companies and music groups often centers on “Audio-to-Audio” (style transfer) and content attribution. This is where the technology becomes truly transformative for artists, allowing them to hum a melody and have it rendered by a symphony.
Audio Variation and In-painting
Similar to how Midjourney or DALL-E 3 can edit images, audio models can perform in-painting (replacing a section of audio) or variation. This requires passing an initial audio waveform into the pipeline, adding noise, and then denoising it guided by a new prompt.
Digital Watermarking and Attribution
A critical component of responsible AI, often highlighted in IBM Watson News and Microsoft Azure AI News, is the ability to detect AI-generated content. In audio, this is achieved through imperceptible watermarking—embedding a signal into the frequency spectrum that survives compression (MP3 conversion) but is undetectable to the human ear.

Artificial intelligence analyzing image – Artificial Intelligence Tags – SubmitShop
While proprietary methods exist, we can simulate the concept of embedding metadata or a “sonic signature” using Python libraries. This ensures that generated content can be traced back to the model and the prompt used.
import librosa
import soundfile as sf
def apply_watermark_concept(input_file, output_file, signature_freq=22000):
"""
Conceptual example of adding a high-frequency pilot tone
as a rudimentary watermark.
NOTE: Production systems use spread-spectrum techniques
(like AudioSeal from Meta AI News) which are much more robust.
"""
# Load the generated audio
y, sr = librosa.load(input_file, sr=None)
# Generate a pilot tone at a frequency usually inaudible to adults
# or at the Nyquist edge
duration = len(y) / sr
t = np.linspace(0, duration, len(y))
# Create a very low amplitude sine wave at the signature frequency
watermark = 0.001 * np.sin(2 * np.pi * signature_freq * t)
# Add to original signal
y_watermarked = y + watermark
# Save the watermarked file
sf.write(output_file, y_watermarked, sr)
print(f"Watermarked audio saved to {output_file}")
# Usage
# In a real pipeline, you might use libraries like 'wavmark'
# or proprietary SDKs from responsible AI partners.
apply_watermark_concept("generated_track_42.wav", "generated_track_42_wm.wav")Implementing robust watermarking is a key requirement for enterprise adoption. It aligns with standards discussed in TensorFlow News regarding model governance and Amazon Bedrock News regarding enterprise security.
Section 4: Best Practices and Optimization for Production
Deploying generative audio models presents unique challenges compared to text models. While LangSmith News focuses on tracing LLM chains, audio pipelines require monitoring of latency and spectral quality.
1. Inference Optimization
Audio generation is slow. To speed it up, developers should look into TensorRT News and ONNX News. Converting the U-Net component of the diffusion model to TensorRT can yield 2-3x speedups. Additionally, using DeepSpeed News optimization techniques can help in serving larger models.
2. Dataset Curation and RAG for Audio

Artificial intelligence analyzing image – Artificial intelligence in healthcare: A bibliometric analysis …
Just as Retrieval Augmented Generation (RAG) is popular in LlamaIndex News and Pinecone News for text, “Audio RAG” is emerging. This involves retrieving relevant audio stems or MIDI patterns from a vector database (like Milvus News, Weaviate News, or Qdrant News) to condition the generation. This ensures the output adheres to a specific musical theory or artist style without retraining the model.
3. Ethical Guardrails
When building these tools, you must implement input filtering. If a user prompts for “A song in the exact style of [Famous Artist],” the system should either refuse or transform the prompt if that artist is not licensed. This logic is similar to safety filters discussed in Google Colab News and Kaggle News competitions regarding AI safety.
def validate_prompt(prompt, blocked_terms):
"""
Simple guardrail to ensure responsible usage.
"""
prompt_lower = prompt.lower()
for term in blocked_terms:
if term in prompt_lower:
raise ValueError(f"Prompt contains restricted term: {term}")
return True
try:
# Example of blocking specific artist names not in the licensed dataset
blocked = ["taylor swift", "drake", "beatles"]
validate_prompt("Make a song like Drake", blocked)
except ValueError as e:
print(f"Security Alert: {e}")
# Log this event to a monitoring system like Comet ML News or ClearML NewsConclusion
The collaboration between major music entities and AI firms marks a turning point in Stability AI News. We are moving away from the “Wild West” of scraping towards a structured, responsible ecosystem where high-quality data yields high-fidelity results. For developers, this means mastering the intricacies of PyTorch, understanding the physics of audio via libraries like torchaudio, and implementing robust engineering practices that prioritize speed, quality, and ethics.
As tools like RunPod News and Modal News make GPU compute more accessible, and frameworks like Ray News and Dask News simplify scaling, the barrier to entry for creating sophisticated music AI applications is lowering. However, the differentiator will no longer be just the ability to generate sound, but the ability to do so responsibly, controllably, and within the legal frameworks that sustain the music industry.
Whether you are following JAX News for research or Snowflake Cortex News for enterprise data, the integration of generative audio is the next frontier. Start experimenting with the code examples provided, ensure your pipelines are optimized, and always prioritize the ethical implications of the content you generate.


