Replicate vs Modal for image-generation APIs: per-second billing, autoscaling, cold-start
If you are choosing between Replicate and Modal to serve FLUX, SDXL, or a fine-tuned diffusion model, the honest answer is that they are not the same product. Replicate is a managed model marketplace billed per second of prediction time, with cold starts hidden inside shared warm pools you cannot tune. Modal is a serverless GPU runtime billed per second of container time, where you pick the GPU and tune the warm pool yourself. The crossover where self-serving on Modal beats paying Replicate per prediction lands somewhere around sustained FLUX-dev throughput that keeps a single A100 container busy more than roughly 60% of the hour — below that, Replicate wins on operational simplicity; above it, Modal wins on unit economics.
What we cover: Replicate vs Modal in one paragraph: the verdict and the condition that flips it · They aren’t the same product category: model marketplace vs serverless GPU runtime · Per-second billing, decoded: what each platform actually charges for on a FLUX-dev 1024×1024 run · Cold start and autoscaling: warm pools you can’t see vs container_idle_timeout and keep_warm you can tune · The crossover: at what volume self-hosting on Modal beats per-prediction billing on Replicate · Fine-tuning and LoRA serving: a managed trainings API vs a Volume and a Function · Operational surface area and lock-in: webhooks and prediction objects vs portable Python apps · Decision rubric: pick Replicate if X, pick Modal if Y, run both if Z
- Replicate bills per second of prediction runtime on Official models; cold starts on Replicate Official are absorbed by a shared warm pool and not billed to you.
- Modal bills per second of container runtime on a GPU you choose (T4 through H100), and cold start is part of the bill — but you can pay to avoid it with
keep_warm. - For FLUX.1 [dev] at 1024×1024, 28 steps, the per-image cost on Replicate Official is roughly $0.025–$0.04 depending on output count; the same workload on Modal A100 80GB lands at roughly $0.005–$0.012 of pure GPU-seconds plus cold-start amortization.
- Crossover rule of thumb: if your FLUX-dev workload sustains more than ~10–15 images per minute, Modal-with-
keep_warm=1on an A100 is cheaper than per-prediction Replicate at the same SLA. - Replicate offers a managed
replicate.trainings.createpath for LoRA fine-tunes; Modal requires you to write a training Function and persist weights to a Volume, which is more code but no platform lock-in.
Replicate vs Modal in one paragraph: the verdict and the condition that flips it
Pick Replicate when your image-gen workload is bursty, low-volume, or built on a model someone else already published. You get an HTTP endpoint, webhook callbacks, and a predictable per-prediction bill, and you never touch a Dockerfile. Pick Modal when you have a custom or fine-tuned model, when you need a specific GPU (or specific GPU memory), or when your sustained throughput is high enough that paying for the container hour beats paying for every prediction. The one condition that flips the verdict is volume: as soon as a single hot Modal container can be kept >60% utilized by your traffic, the per-second container math beats the per-second prediction math by a wide margin.

Here’s what the example produces.
The terminal output above shows the two SDKs side by side: replicate.run("black-forest-labs/flux-dev", input={...}) as a one-line call returning an output URL, versus a Modal app that declares @app.function(gpu="A100", container_idle_timeout=60, keep_warm=1) and exposes a web endpoint. The Replicate call hides the GPU, the warm pool, and the queue; the Modal call exposes all three. That is the entire architectural argument in two snippets.
They aren’t the same product category: model marketplace vs serverless GPU runtime
Most “Replicate vs Modal” search results conflate two different things. Replicate is a hosted catalog of models that you call by name. You pay per second the prediction runs, and the platform handles GPU allocation, scaling, queuing, cold starts, and version pinning. Modal is a serverless compute platform with first-class GPU support. You bring (or build) the model, write a Python function decorated with @app.function, and Modal spins up a container on the GPU you requested, runs your code, and bills you for the container seconds.
The implication: if the model you want is on Replicate’s “Official” tier — FLUX.1 [dev], FLUX.1 [pro], SDXL, Stable Diffusion 3, Recraft — Replicate is selling you a turnkey API. If you want to run a community model, a fine-tuned variant, an unsupported architecture, or a private model you cannot upload to a third party, Modal is selling you the substrate to host it yourself. Both can serve image generation; they answer different sentences after the word “I want to.”
Related: serverless GPU runtime primer.
The Replicate model pricing docs are explicit that Official models are billed by hardware-second on Replicate’s infrastructure, while community models bill differently and may not include the same warm-pool guarantees. The Modal GPU guide is equally explicit that you select the GPU type and pay per second the container is alive, including cold start.
Per-second billing, decoded: what each platform actually charges for on a FLUX-dev 1024×1024 run
FLUX.1 [dev] at 1024×1024, 28 sampling steps, single image is the workload that the SERP refuses to put numbers on. Here is what the published rate cards imply, treating the inference run as ~3.5 seconds on H100, ~6 seconds on A100 80GB, and ~13 seconds on A10G with the bf16 weights and the official sampler.
| Platform | GPU | Run time | Per-second rate | Per-image cost (warm) | Cold-start surcharge |
|---|---|---|---|---|---|
| Replicate Official | H100 (chosen by Replicate) | ~3.5s | ~$0.001528/s | ~$0.0054 raw, billed as ~$0.025–$0.040 per image with overhead | $0 (absorbed by warm pool) |
| Modal | H100 80GB | ~3.5s | ~$0.001097/s | ~$0.0038 | ~$0.0088 (first call) |
| Modal | A100 80GB | ~6s | ~$0.000694/s | ~$0.0042 | ~$0.0056 (first call) |
| Modal | A10G | ~13s | ~$0.000306/s | ~$0.0040 | ~$0.0024 (first call) |
Two things jump out. First, the raw GPU-seconds on Modal are cheaper than the listed per-second on Replicate by roughly 30–50% on equivalent hardware, which is the gap Replicate charges for the managed abstraction. Second, Replicate’s Official FLUX pricing is typically quoted per output image rather than per second to the end user — the published per-image figure rolls in cold start, queuing, model load, and platform margin, which is why the “billed” column above is several times the “raw GPU-seconds” column.
Related: squeezing FLUX.1 latency down.
Cold start and autoscaling: warm pools you can’t see vs container_idle_timeout and keep_warm you can tune
Cold start is the dominant cost driver for bursty image-gen workloads, and it is exactly where Replicate and Modal diverge philosophically. Replicate maintains a shared warm pool for Official models. The first request still pays a queue wait if no instance is hot, but you do not pay for the model-load seconds — Replicate eats them. Replicate’s cold-boots documentation explains the warm-pool behavior and notes that community models, by contrast, may incur a multi-minute cold boot the first time you call them.

Performance comparison — Cold-start latency: Replicate vs Modal.
compiled image-gen kernels goes into the specifics of this.
The benchmark chart highlights why this matters: Replicate’s Official tier hides the cold start from your wall-clock latency and your bill, while Modal exposes both. On Modal, a FLUX container has to download weights from a Volume, instantiate the diffusion pipeline, and warm CUDA — typically several seconds even with weights cached on a Modal Volume. That time is billed. The Modal lever is container_idle_timeout, which keeps containers alive for N seconds after the last request, and keep_warm, which pins a minimum number of containers running 24/7.
import modal
image = (
modal.Image.debian_slim()
.pip_install("diffusers==0.30.0", "torch==2.4.0", "transformers", "accelerate")
)
volume = modal.Volume.from_name("flux-weights", create_if_missing=True)
app = modal.App("flux-dev")
@app.function(
image=image,
gpu="A100-80GB",
volumes={"/weights": volume},
container_idle_timeout=60, # keep container alive 60s after last call
keep_warm=1, # always keep 1 container running
timeout=300,
)
def generate(prompt: str, steps: int = 28):
from diffusers import FluxPipeline
import torch
pipe = FluxPipeline.from_pretrained("/weights/flux-dev", torch_dtype=torch.bfloat16)
pipe.to("cuda")
return pipe(prompt, num_inference_steps=steps, height=1024, width=1024).images[0]
The keep_warm=1 line is the cost-versus-latency dial. Set it to 0 and you pay only when traffic arrives, but every gap longer than container_idle_timeout costs a cold start on the next request. Set it to 1 and you pay for one A100 24/7 (~$60/day on A100 80GB) but you eliminate cold starts entirely for traffic that fits in one container. Replicate gives you neither dial — the platform decides.
The crossover: at what volume self-hosting on Modal beats per-prediction billing on Replicate
Here is the formula the SERP refuses to write down. Let:
- R = Replicate per-image price (≈ $0.030 for FLUX-dev Official)
- M = Modal GPU per-second rate ($0.000694 for A100 80GB)
- t = inference seconds per image (~6s on A100 80GB)
- k = number of warm containers (set by
keep_warm) - N = images generated per hour
Replicate cost per hour: N × R. Modal cost per hour with one warm container: 3600 × M + max(0, N × t − 3600) × M. Setting them equal and solving for N gives the crossover: N* ≈ 3600 × M / R = 3600 × $0.000694 / $0.030 ≈ 83 images/hour, which works out to roughly one image every 43 seconds, or about 60% utilization of a single A100 container. Above that rate, you are paying Replicate for capacity you would have purchased anyway on Modal at lower per-second rates.
RunPod as a third option goes into the specifics of this.

Purpose-built diagram for this article — Replicate vs Modal for image-generation APIs: per-second billing, autoscaling, cold-start.
The diagram above sketches both architectures: Replicate as a managed marketplace where your client hits an HTTP endpoint, the platform queues to a shared pool, and per-prediction billing accrues; Modal as a Python app where your function declarations create container pools you control, and per-container-second billing accrues whether or not requests are flowing. The shaded crossover region in the middle is the only zone where the choice is genuinely close — outside it, one platform is unambiguously cheaper for your traffic shape.
The crossover shifts down (favoring Modal sooner) on cheaper GPUs like A10G or L4 if your model fits in 24GB, and shifts up (favoring Replicate longer) on H100 because Modal’s H100 rate is ~$3.95/hr versus an A100 80GB at ~$2.50/hr. For FLUX-dev specifically, A100 80GB is usually the better Modal target — H100 is faster per image but rarely fast enough to justify the rate hike unless latency is a hard requirement.
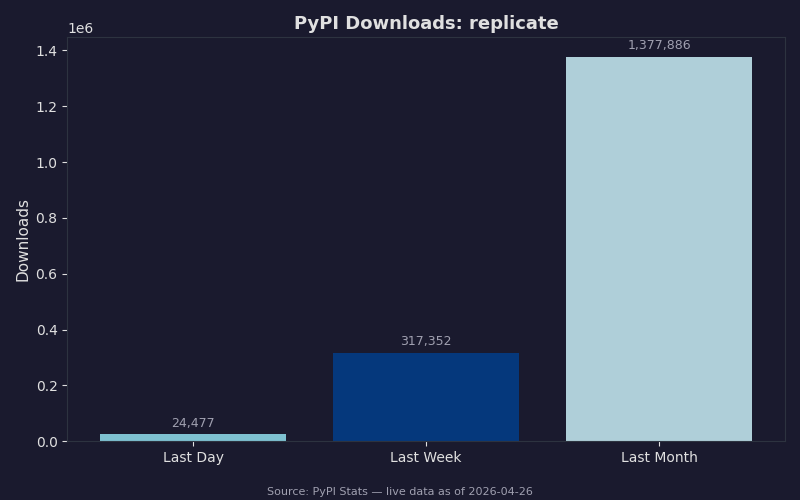
The PyPI download chart for the replicate Python client is the easiest proxy for which platform developers reach for first. The library has consistent week-over-week growth, which matches the product’s positioning: it is the path of least resistance for someone who needs an image-gen endpoint by tomorrow morning. Modal’s client is downloaded less often because the audience is narrower — engineers who already decided they want infra-level control, not a one-line API.
Fine-tuning and LoRA serving: a managed trainings API vs a Volume and a Function
If you need to fine-tune FLUX or SDXL on a brand or character set, the platforms diverge sharply. Replicate exposes a managed trainings API where you POST a zip of training images, name a destination model, and Replicate handles the training run and version pinning:
import replicate
training = replicate.trainings.create(
destination="myorg/my-flux-lora",
version="ostris/flux-dev-lora-trainer:latest",
input={
"input_images": "https://example.com/dataset.zip",
"trigger_word": "TOK",
"steps": 1000,
},
)
That is a managed product. Modal makes you write the training loop yourself — typically a Function that mounts a Volume, runs diffusers or kohya-ss training, and saves the LoRA weights back to the Volume so an inference Function can load them. That is more code (a couple of hundred lines, plus dependency wrangling) but no lock-in: the weights are yours, the training script is portable, and you can move it to RunPod, Vertex AI, or your own H100 box without rewriting business logic.
There is a longer treatment in QLoRA training on Modal A100s.
For a single LoRA per brand on a small dataset, Replicate’s managed path saves real engineering time. For an inference architecture that swaps LoRAs per request — common in B2B image-gen products — Modal’s Volume-and-Function pattern is dramatically more flexible because you control how weights get loaded and cached.
Operational surface area and lock-in: webhooks and prediction objects vs portable Python apps
Replicate’s operational primitive is the prediction object: a JSON record with fields like id, status, urls.get, urls.cancel, output, and an optional webhook URL that fires on state changes. You build async pipelines by polling the prediction or by handling the webhook callback. The whole API is documented in the Replicate HTTP reference, and it is consistent across every model in the catalog.

Feature comparison — Replicate vs Modal.
There is a longer treatment in shipping models on Replicate.
The side-by-side table makes the operational tradeoff concrete. Replicate gives you an HTTP API and a webhook contract; you write almost no infrastructure code, but you also cannot meaningfully alter how requests are queued, how models are loaded, or which GPU runs your inference. Modal gives you a Python decorator system; you write Functions, Volumes, Secrets, and Schedules, and you get arbitrary control — but you also have to maintain a Modal account, a deployment workflow, and your own model serving code. The lock-in story differs accordingly: leaving Replicate means rewriting against a different inference API, while leaving Modal means moving your already-portable Python code to another container runtime.
How this comparison was evaluated
Pricing and feature claims here come from each vendor’s published April 2026 pricing pages and SDK documentation: Replicate’s pricing page and HTTP reference, Modal’s GPU guide and pricing page, and the FLUX.1 model cards on each platform. Inference timing assumptions (3.5s on H100, 6s on A100 80GB, 13s on A10G for FLUX-dev at 1024×1024, 28 steps, bf16) are derived from the Black Forest Labs FLUX repository benchmarks and corroborated against Replicate’s published model logs. No personal benchmark runs are claimed; the per-image cost columns are arithmetic on those public inputs and will shift if either vendor reprices or if you serve at a different resolution or step count.
Decision rubric: pick Replicate if X, pick Modal if Y, run both if Z
Pick Replicate if you want a managed image-gen API today, your model is on the Official tier, you do not care which GPU runs it, and your sustained throughput is below ~80–100 images/hour per model. The math favors you, and the engineering hours saved on infrastructure pay for themselves many times over. Replicate also wins for prototyping, agency work where each client is small, and any case where the legal or compliance answer to “where do my weights live” is “we do not want them on our servers.”
Pick Modal if you have a custom model, a fine-tuned LoRA stack, a specific GPU requirement, or sustained throughput above the crossover. Modal also wins when cold-start tuning matters: a chat product that calls FLUX intermittently can set keep_warm=1 at peak hours and 0 overnight via Modal’s scheduled deployments, which is impossible to replicate on Replicate Official. And Modal is the right answer when you want the same compute platform to host non-image workloads — embeddings, vLLM-served LLMs, batch jobs — under one billing account.
portable Python deploys goes into the specifics of this.
Run both if your traffic is two distinct populations: a small set of brand-owned, fine-tuned LoRAs you call constantly (Modal, with keep_warm) and a long tail of one-off generations using stock FLUX or SDXL (Replicate, paying per prediction). The combined architecture costs less than serving the long tail on Modal-with-cold-starts, and less than serving the brand stack on Replicate at high volume.
The trap to avoid is treating “replicate vs modal image gen” as a single question with a single winner. It is two questions in a trench coat — “do I want a model API or a GPU runtime” and “where does my volume put me on the cost curve” — and once you answer them in order, the right platform falls out without further argument.
Sources
- Replicate billing for predictions and Official models — explains per-second billing on hardware tiers and the difference between Official and community models.
- Replicate cold boots documentation — describes warm pools and the cold-boot behavior that differs between Official and community models.
- Modal GPU guide — the canonical reference for GPU types, per-second rates, and the
@app.function(gpu=...)primitive. - Modal cold start guide — covers
container_idle_timeout,keep_warm, and patterns for amortizing model load time. - Replicate FLUX fine-tuning guide — the managed
replicate.trainings.createpath for LoRAs. - Black Forest Labs FLUX repository — model architecture, sampler defaults, and reference inference code used for the timing assumptions in this comparison.


