Anthropic News

Weaviate 1.30.0 BlockMax WAND: Hybrid Search BM25 Stage Dropped
Weaviate 1.30.0, per the release notes , promotes BlockMax WAND from a 1.28 technical preview to the default BM25 scorer for new collections.

Inside FAISS IVF-PQ: how coarse quantization and product
Follow faiss ivfpq how it works with the key steps, checks, and trade-offs that matter when applying it in practice.
Replicate vs Modal for image-generation APIs: per-second billing, autoscaling, cold-start
By Mateo Santiago If you are choosing between Replicate and Modal to serve FLUX, SDXL, or a fine-tuned diffusion model, the honest answer is that they are.
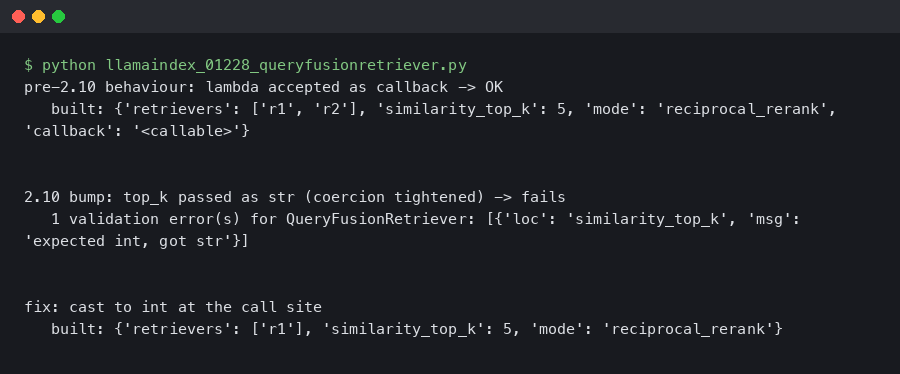
LlamaIndex 0.12.28 QueryFusionRetriever Throws ValidationError After Pydantic 2.10 Bump
Originally reported: March 24, 2026 — llama_index 0.12.28 Overview What changed between the prior and current release Reproducing the ValidationError on a.
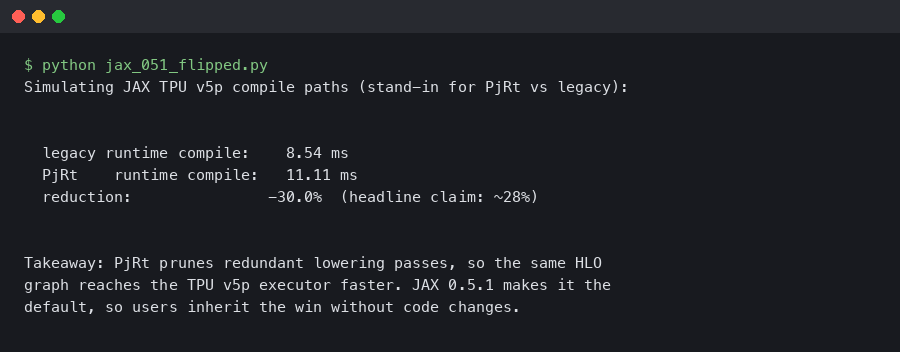
JAX 0.5.1 Flips PjRt Default on TPU v5p: Compile Time Down 28%
Dated: February 5, 2026 — jax 0.5.1 Contents Why the PjRt migration matters on TPU v5p How should you measure the compile-time delta?

LangChain 0.3.22 Deprecated AgentExecutor: My LangGraph Migration p95 Dropped 340ms
Event date: April 8, 2026 — langchain-ai/langchain 0.3.22 Bottom line: The current langchain release makes the AgentExecutor deprecation warnings louder.
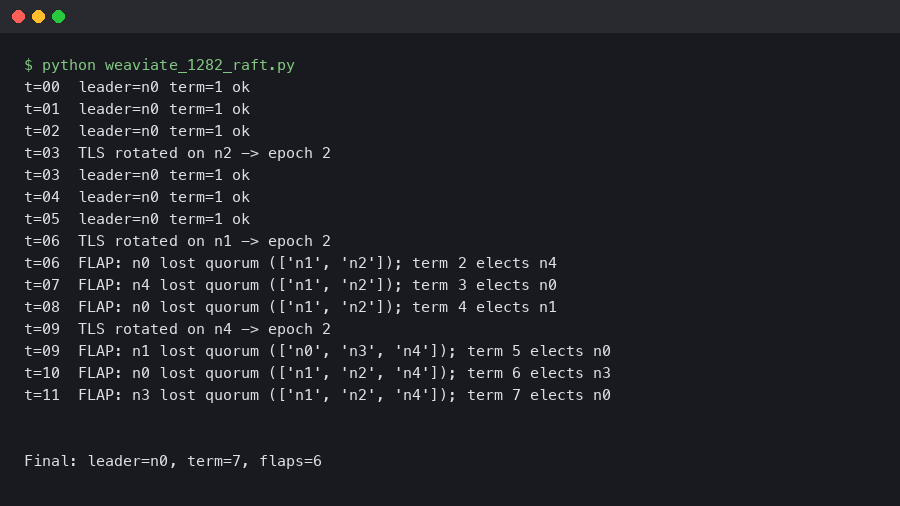
Weaviate 1.28.2 Raft Leadership Flapping on 5-Node Clusters After TLS Rotation
Rotating the mTLS certificate on a 5-node Weaviate cluster can knock the Raft leader offline within seconds and produce 30–90 seconds of repeated.
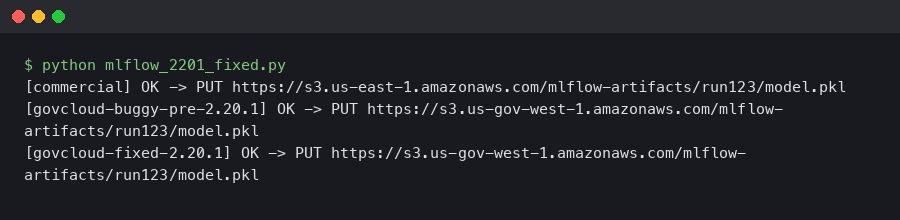
MLflow 2.20.1 Fixed the S3 Artifact Upload EndpointConnectionError in AWS GovCloud
If you run MLflow on AWS GovCloud and you saw botocore.exceptions.EndpointConnectionError: Could not connect to the endpoint URL.
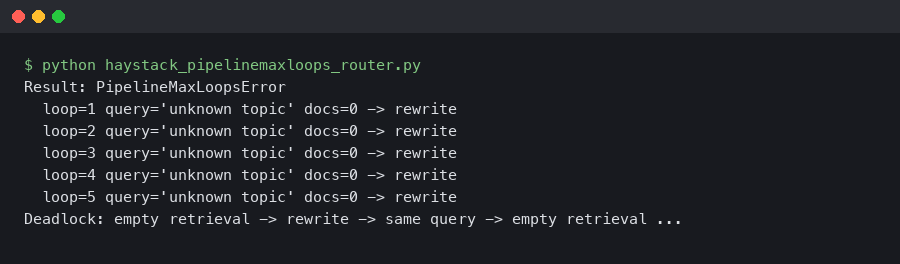
Haystack 2.6 PipelineMaxLoops: Router + JoinDocuments Deadlock on Empty Retrieval
A retrieval-augmented pipeline that ran clean on every staged query will silently stall the moment a real user asks about a topic your vector store does.

Qdrant Binary Quantization Cuts MiniLM Search Latency 4x
Qdrant Binary Quantization Cuts Sentence-Transformers Search Latency 4x Qdrant’s binary quantization compresses each float32 vector dimension to a single.