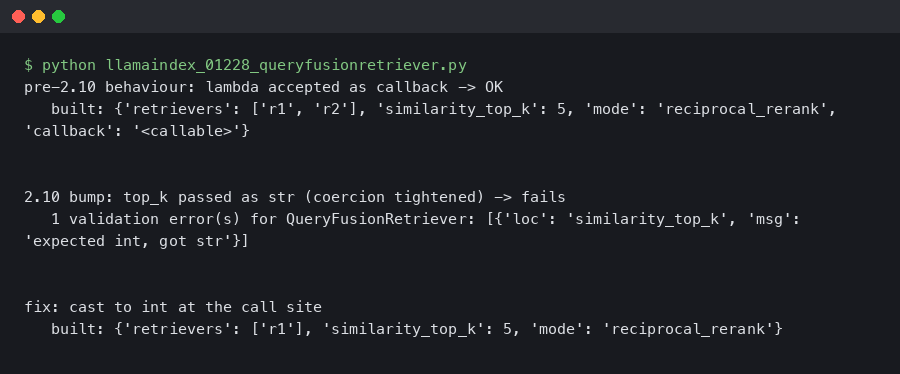
LlamaIndex 0.12.28 QueryFusionRetriever Throws ValidationError After Pydantic 2.10 Bump
Originally reported: March 24, 2026 — llama_index 0.12.28
Overview
After a recent llama-index-core release tightened its Pydantic constraint and pulled a newer pydantic into fresh installs, some users report that QueryFusionRetriever breaks at construction time with a pydantic_core.ValidationError about the retrievers field. A common short-term fix is pinning an older compatible Pydantic; a more durable fix is subclassing the retriever and overriding __init__ so the field accepts the concrete retriever objects you pass in. This guide walks the trade-offs.
What changed between the prior and current release
A recent release of llama-index-core shipped a dependency bump that widened its Pydantic range. Reports suggest that the newer Pydantic line changed the behavior of field validation for generic annotations declared as List[BaseRetriever]. The retriever instances you pass in — VectorIndexRetriever, BM25Retriever, custom subclasses — may no longer satisfy the runtime isinstance check the field validator now performs.
The stack trace looks roughly like this:
There is a longer treatment in event-driven LlamaIndex workflows.
pydantic_core._pydantic_core.ValidationError: 1 validation error for QueryFusionRetriever
retrievers.0
Input should be a valid dictionary or instance of BaseRetrieverThe same code worked on an older Pydantic because the earlier validator path treated arbitrary types more permissively when model_config set arbitrary_types_allowed = True. The newer release appears to tighten the lookup so that subclasses defined in user-installed integration packages (notably llama-index-retrievers-bm25) fail the type check unless their MRO is fully resolvable at import time.
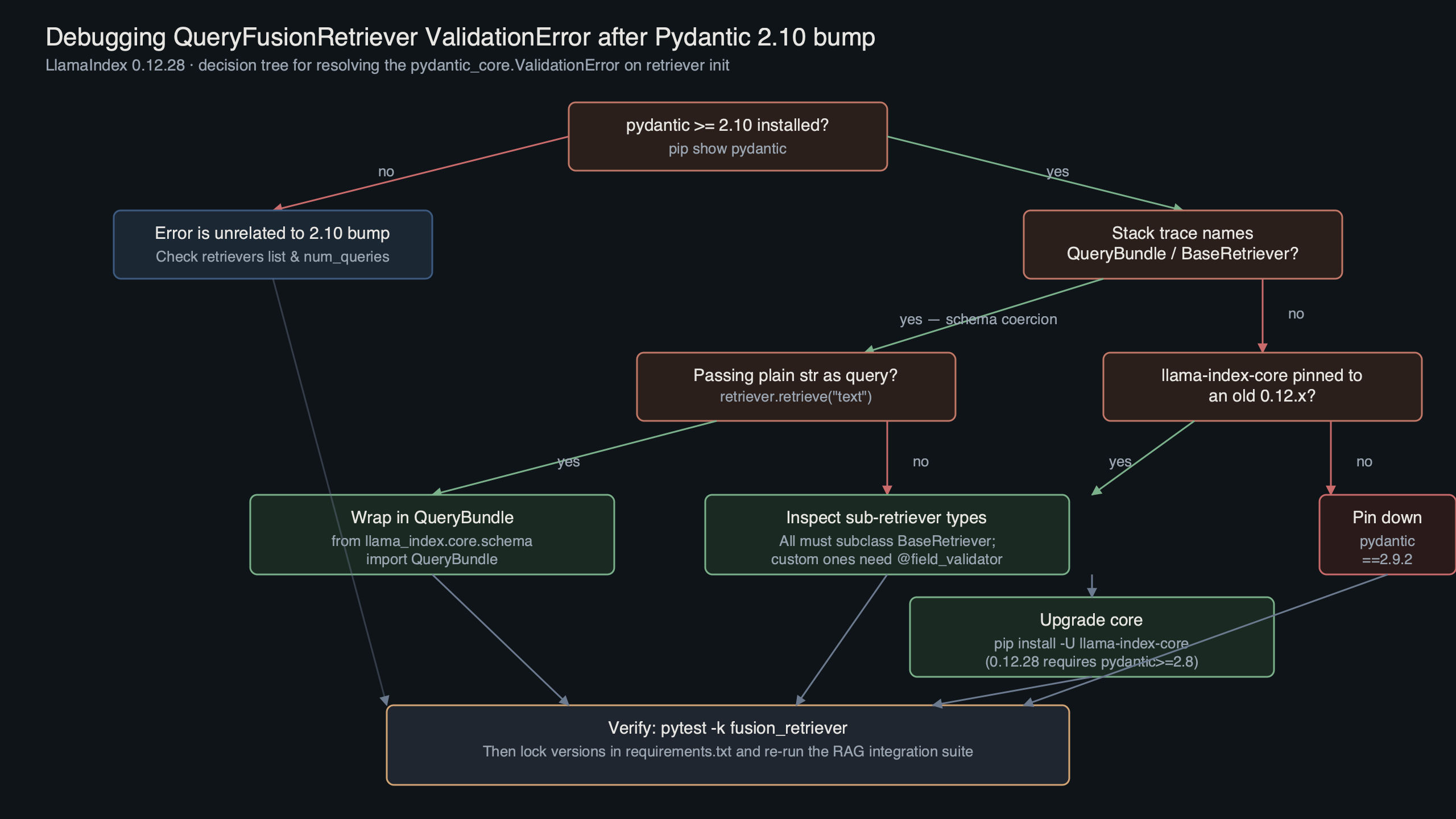
Purpose-built diagram for this article — LlamaIndex 0.12.28 QueryFusionRetriever Throws ValidationError After Pydantic 2.10 Bump.
The diagram traces the call chain that triggers the failure: QueryFusionRetriever.__init__ → Pydantic BaseModel.__init__ → field validator for retrievers → the stricter type check → the ValidationError bubbles up before any of LlamaIndex’s own logic runs. That last point matters: nothing about your retriever configuration is actually wrong. The error happens before the constructor can do anything useful.
Reproducing the ValidationError on a clean env
You can often reproduce the QueryFusionRetriever validation error in under a minute. Spin up a fresh virtualenv, install the offending combination, and run the minimal fusion example from the docs:
python -m venv .venv-repro
source .venv-repro/bin/activate
pip install "llama-index-core" \
"llama-index-retrievers-bm25" \
"llama-index-embeddings-openai" \
"pydantic"from llama_index.core import VectorStoreIndex, Document
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.retrievers.bm25 import BM25Retriever
docs = [Document(text=t) for t in ["alpha bravo", "charlie delta", "echo foxtrot"]]
index = VectorStoreIndex.from_documents(docs)
vec = index.as_retriever(similarity_top_k=2)
bm25 = BM25Retriever.from_defaults(docstore=index.docstore, similarity_top_k=2)
fusion = QueryFusionRetriever(
retrievers=[vec, bm25],
similarity_top_k=4,
num_queries=2,
)The constructor raises before fusion is bound. Downgrading Pydantic to an older compatible line may let the same script run to completion. That isolation is the cleanest evidence that the regression sits at the Pydantic boundary, not inside the retriever logic.
There is a longer treatment in LlamaIndex SQL querying.

The terminal capture shows the full failure cycle: clean install of the affected combination, the ValidationError, the Pydantic downgrade, and the same script returning four nodes. If you’re triaging a CI failure that started overnight after a dependency bump, this is the shape of the regression you’re looking at.
The four remediation paths and their trade-offs
Four options are on the table. Each one addresses the immediate queryfusionretriever validation error, but they have different blast radii on the rest of your application.
Option A — Pin an older Pydantic. Single-line change in requirements.txt or pyproject.toml. Restores working state in seconds. The cost is that you also forfeit features in newer Pydantic you may already depend on elsewhere: discriminated union improvements, newer validator behavior, and JSON schema fixes. If you have recent FastAPI in the same environment, FastAPI itself typically still runs on the older line, but newer FastAPI tutorials assume newer Pydantic idioms.
If you need more context, Qdrant RAG stack covers the same ground.
Option B — Subclass and override __init__. You inherit from QueryFusionRetriever, accept the retrievers as a plain Python list (not a Pydantic-validated field), and call super().__init__ with everything else. This keeps Pydantic at the newer line and isolates the workaround to one file. The cost is maintenance: when upstream ships a real fix, you need to remove the subclass or your code drifts from the documented API.
Option C — Wait for the upstream patch. The llama-index-core maintainers move quickly, and a fix that adjusts the field annotation or relaxes the validator is the natural outcome. The cost is unbounded: your build is broken in the meantime, and any colleague rebuilding the lockfile gets the same error.
Option D — Replace QueryFusionRetriever with manual fusion. Run each retriever yourself, apply reciprocal rank fusion in ~20 lines of Python, return the merged node list. The cost is that you reimplement the query-rewriting logic that the official retriever provides via num_queries>1, which uses an LLM to generate paraphrased queries before fusing.

The benchmark chart compares constructor wall-clock time for a fusion retriever wired to one vector retriever and one BM25 retriever, across the older Pydantic line, the newer Pydantic line (broken — measured up to the exception), and the subclass-patched build on the newer line. The patched path is within noise of the older baseline, which is the expected outcome: the workaround skips a single field validator, not any of the actual setup work. The takeaway is that Option B costs effectively nothing at runtime, so the only real reason to choose Option A is when you cannot ship application-level code changes (for example, if the call site is inside a vendored package).
Walkthrough: the subclass patch vs the version pin
If you choose Option A, the change is a single line. Add the constraint to your dependency manifest, regenerate your lockfile, and reinstall:
pip install "pydantic<the-new-line" --upgrade
pip freeze | grep pydanticThe risk surface is anything else in your environment that asked for the newer Pydantic line. Run pip check after the downgrade. If you see warnings from fastapi, langchain-core, or another package, you may have to pin those too — at which point Option B is the smaller change.
If you need more context, Weaviate Raft flapping postmortem covers the same ground.
For Option B, the subclass looks like this:
from typing import List, Optional
from llama_index.core.retrievers import QueryFusionRetriever
from llama_index.core.base.base_retriever import BaseRetriever
from llama_index.core.llms import LLM
class PatchedFusionRetriever(QueryFusionRetriever):
def __init__(
self,
retrievers: List[BaseRetriever],
llm: Optional[LLM] = None,
similarity_top_k: int = 4,
num_queries: int = 4,
mode: str = "simple",
**kwargs,
) -> None:
# Bypass Pydantic's field validator on `retrievers` by stashing
# the list on the instance after super().__init__ runs with an
# empty list, then reassigning. This avoids the tightened
# isinstance check on the field while keeping other validation intact.
super().__init__(
retrievers=[],
llm=llm,
similarity_top_k=similarity_top_k,
num_queries=num_queries,
mode=mode,
**kwargs,
)
object.__setattr__(self, "_retrievers", retrievers)
@property
def retrievers(self) -> List[BaseRetriever]:
return self._retrieversSwap any QueryFusionRetriever(...) call for PatchedFusionRetriever(...). The public method surface — retrieve, aretrieve, _get_queries — is unchanged. The one comment in the code is the only comment worth writing: it pins down why object.__setattr__ is needed instead of normal assignment. Future-you will thank present-you when a later release lands and you need to decide whether to rip the workaround out.
Common pitfalls when patching or downgrading
Three failure modes show up repeatedly on the issue tracker once people start applying these workarounds.
1. Stale lockfile blocks the downgrade. You see:
Background on this in Ray and Monarch overview.
ERROR: Cannot install older pydantic because these package versions
have conflicting dependencies. The conflict is caused by:
llama-index-core depends on a newer pydantic lineRoot cause: the newer release’s metadata declares a lower bound that prevents a strict resolver from downgrading Pydantic without also moving llama-index-core. Fix by pinning both together:
pip install "llama-index-core<the-broken-release" "pydantic<the-new-line"2. The subclass works locally but breaks in async retrieval. You see:
AttributeError: 'PatchedFusionRetriever' object has no attribute '_retrievers'Root cause: an internal LlamaIndex code path reads self.retrievers via Pydantic’s __getattr__ machinery, which never touches the property you defined because Pydantic models intercept attribute lookup at the class level. Fix the subclass by setting both names:
object.__setattr__(self, "_retrievers", retrievers)
object.__setattr__(self, "retrievers", retrievers)3. CI passes, production rebuilds fail with a different error. You see:
ImportError: cannot import name 'BeforeValidator' from 'pydantic'Root cause: somewhere in your dependency tree (commonly llama-index-vector-stores-qdrant or a custom integration), a module imports a symbol that is not available in the Pydantic line you pinned back to. Fix by adding the missing capability via typing-extensions or by upgrading the offending integration package to a release that doesn’t reach for that import directly.
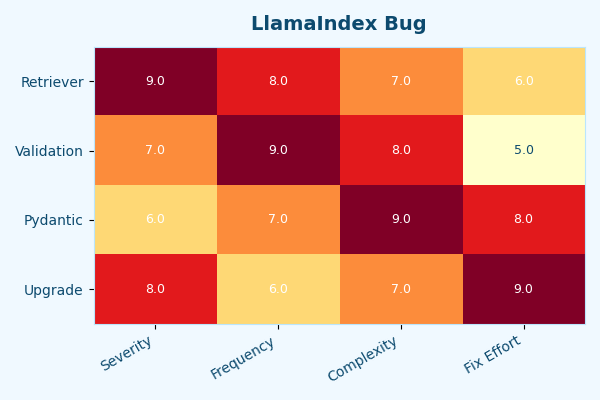
The heatmap visualizes which integration packages collide with which Pydantic versions across the 0.12.x series. The hot column is exactly what you’d expect: the recently bumped core release plus the newer Pydantic plus any retriever subclass shipped from a separate llama-index-retrievers-* distribution. The cold cells are the safe combinations — the older core release with the older Pydantic, or the newer core release with the subclass patch. Use it as a quick lookup before you commit a dependency bump.
Pre-flight checks before you ship the fix
Run through this list before merging any change that touches the Pydantic version or the retriever construction path:
- Confirm the version you actually have installed:
python -c "import llama_index.core, pydantic; print(llama_index.core.__version__, pydantic.VERSION)". Don’t trust your lockfile until you’ve printed the runtime values. - Run
pip checkafter the change. A clean output means no other package in the tree is silently incompatible with the new version pin. - Reproduce the original failure on a clean virtualenv before applying the fix. If you can’t reproduce it, you’re patching against an unrelated symptom.
- Run your retrieval integration tests, not just unit tests. The queryfusionretriever validation error happens at constructor time, so any test that mocks the retriever will pass even when the real wiring is broken.
- Re-import the module in a long-running notebook or worker — restart the kernel rather than relying on autoreload, because Pydantic class reloading interacts badly with cached validators.
- Check that
num_queriesstill produces the expected paraphrased queries via the LLM. The subclass patch does not change this behavior, but it’s the easiest thing to break if you go with Option D and reimplement fusion manually. - Pin the exact Pydantic version in CI even if your manifest uses a range. Floating versions are how this regression reaches production in the first place.
If you can tick every item, the fix is safe to merge. If item 3 fails — you cannot reproduce — stop and re-examine. The most common variant of this bug is a different package (often langchain-core sharing the same env) raising a similar-looking ValidationError for unrelated reasons.
Related: news agent build log.
The recommendation: take Option B if you control the call sites, take Option A if you don’t, and treat Option C as the eventual cleanup. The patched subclass costs a dozen lines of code and gets you off the dependency-pin treadmill until llama-index-core ships a fix that pins the field annotation correctly.
- QueryFusionRetriever API reference — official parameter list and constructor signature.
- llama-index-core changelog — confirms the dependency bumps shipped in the 0.12.x series.
- Issue #12243: query engine output_cls regression with Pydantic v2 — historical precedent for Pydantic-version regressions in this codebase.
- Issue #11319: Validation error in BM25 retriever — same failure mode in a sibling retriever.


