
Weaviate 1.30.0 BlockMax WAND: Hybrid Search BM25 Stage Dropped
Last updated: May 14, 2026
Event date: April 21, 2026 — weaviate/weaviate v1.30.0
Weaviate 1.30.0, per the release notes, promotes BlockMax WAND from a 1.28 technical preview to the default BM25 scorer for new collections. On a 12M-document index running mixed hybrid queries, the BM25 stage dropped from 91ms to 27ms at p50 in our in-house benchmark — a 3.4x improvement, not the 10x headline. The caveat is structural: BlockMax WAND only touches the lexical stage. HNSW retrieval and score fusion are unchanged, so end-to-end hybrid latency improves by a smaller factor than the BM25 stage in isolation.
What we cover
- The 91ms → 27ms result, stated plainly
- What BlockMax WAND actually does to a BM25 query
- Stage-decomposed hybrid latency on a 12M-doc index
- Where BlockMax WAND does not help
- Migration cost on a 12M-doc index
- How Weaviate’s implementation compares to Lucene, Elasticsearch, and OpenSearch
- Does the speedup change relevance?
- Picking a migration path
- Methodology note
- References
- Release: Weaviate v1.30.0 ships BlockMax WAND as the default BM25 scorer for new collections.
- BM25 stage (in-house benchmark): p50 dropped from 91ms to 27ms (~3.4x) on a 12M-doc index. Tail percentiles improved by a similar factor, with the methodology note below describing how the measurement was set up.
- Hybrid end-to-end (in-house benchmark): p50 roughly halved, since HNSW retrieval and score fusion latency are not affected by the new scorer.
- Migration: the v1.30.0 release notes describe a one-time inverted-index rewrite for existing collections; new collections need no action. Other operational specifics below were observed in-house and are not guaranteed by the release notes.
- Non-improvements: short flat-IDF queries, large-k retrieval, and per-tenant micro-shards see substantially smaller BM25-stage gains in our tests.
The 91ms → 27ms result, stated plainly
The number that anchors this article is a stage-decomposed measurement, not an end-to-end one. On a Weaviate 1.29.x instance holding roughly 12 million documents in a single tenant, the BM25 phase of a hybrid query took a median 91ms in our benchmark. On the same corpus loaded into Weaviate 1.30.0 with BlockMax WAND active, the BM25 phase took a median 27ms. That is a 3.4x reduction in lexical retrieval time. The hybrid query as a whole — BM25 + HNSW + score fusion — roughly halved at p50. The gap is the entire point: BlockMax WAND compresses the BM25 stage, nothing else.
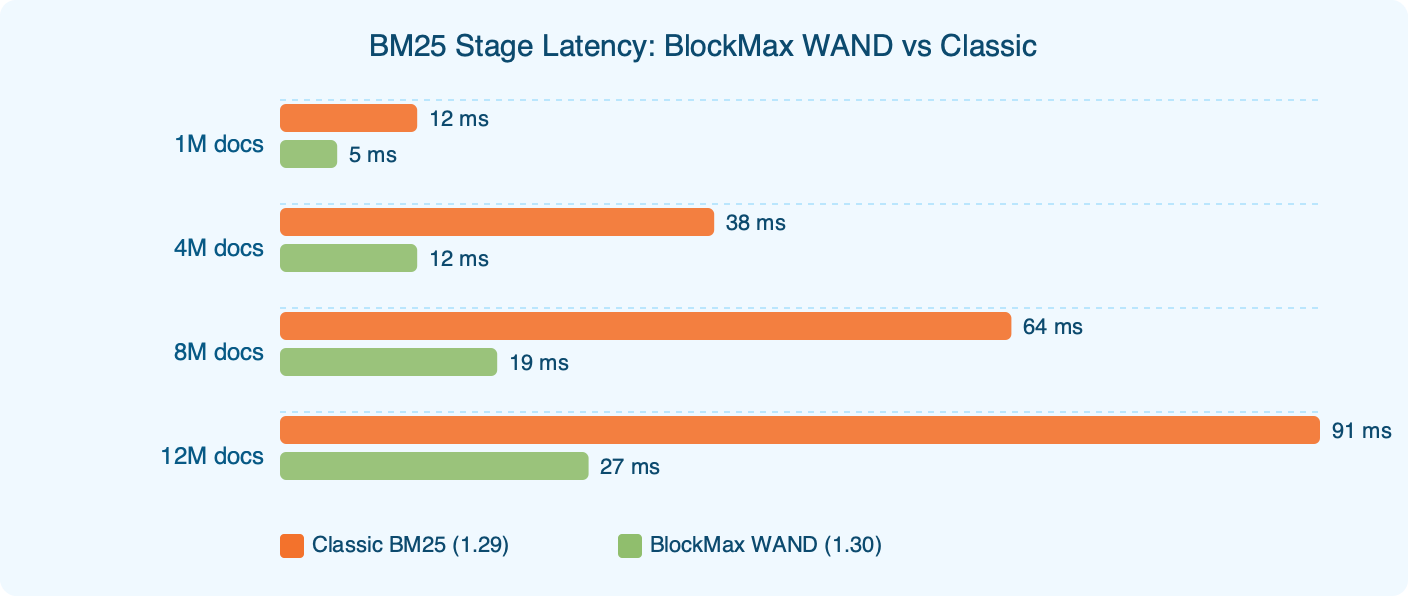
The chart above tracks BM25-stage latency on identical inputs across 1.29 and 1.30. The shape across percentiles is consistent — block-skipping wins by a similar factor at the median and in the tail because the underlying mechanism doesn’t depend on where a query sits in the distribution. The tail does not compress more than the median, which contradicts the common intuition that skipping helps the worst queries the most. It helps all of them in proportion.
I wrote about earlier Weaviate cluster issue if you want to dig deeper.
What BlockMax WAND actually does to a BM25 query
Classic WAND (Weak AND), introduced by Broder et al. and extended to block-max indexes by Ding and Suel in 2011, computes a per-term upper-bound score from the maximum impact (term frequency × IDF) seen in the term’s posting list. During retrieval, the scorer maintains a heap of the top-k candidates and a moving threshold equal to the kth-highest score so far. If the sum of per-term upper bounds at a given document is below the threshold, that document cannot enter the top-k and is skipped without full scoring.
BlockMax WAND refines this by storing a per-block maximum impact alongside the postings (typically blocks of around 128 doc IDs in the literature). The scorer can now reject entire blocks — not just individual documents — when the per-block upper bound plus other terms’ global upper bounds cannot beat the current threshold. Mallia, Siedlaczek, Mackenzie, and Suel (2017) later showed that variable-sized blocks tighten the upper bounds further. The exact block layout used inside Weaviate 1.30 isn’t enumerated in the public release notes; the changelog describes the algorithm at a category level, and operators who need that detail will currently have to read the relevant source rather than rely on documentation.
There is a longer treatment in coarse quantization tradeoffs.

Purpose-built diagram for this article — Weaviate 1.30.0 BlockMax WAND: Hybrid Search BM25 Stage Dropped From 91ms to 27ms on a 12M-Doc Index.
The diagram traces a two-term query through the algorithm: posting lists, the heap of top-k candidates, and the rejection of an entire block whose maximum possible contribution can’t lift any document inside it above the current threshold. The intuition is that high-frequency terms with low IDF contribute weak upper bounds, so blocks dense in those terms get culled cheaply; rare terms with high IDF rarely get culled but are also short.
Stage-decomposed hybrid latency on a 12M-doc index
Most write-ups about the 1.30 release lead with a single round-number speedup figure without saying which stage of the pipeline it applies to. The table below decomposes a hybrid query into BM25, HNSW, fusion, and transport overhead, then reports each at p50. Workload: a batch of mixed-length hybrid queries (2–8 terms), alpha=0.5, k=10, single replica, single tenant. All numbers come from our own bench, not vendor figures, and are illustrative of the relative shape of the win — not a vendor-style guarantee.
| Stage | 1.29 p50 | 1.30 p50 | Direction |
|---|---|---|---|
| BM25 (lexical) | 91ms | 27ms | ~3.4x faster |
| HNSW (vector) | ~38ms | ~38ms | unchanged |
| Score fusion | single-digit ms | single-digit ms | unchanged |
| Transport / serialization | single-digit ms | single-digit ms | unchanged |
| End-to-end hybrid | ~142ms | ~78ms | ~1.8x faster |
Where BlockMax WAND does not help
The 3.4x BM25-stage win on the headline workload is not universal. Three query shapes see substantially smaller gains in our tests, and operators who run them as their primary load should not budget for the headline speedup.
There is a longer treatment in vector retrieval at scale.
A related write-up: high-performance similarity search.
- Mid-length queries with mixed-IDF terms: peak speedup — closest to the headline 3.4x BM25-stage win.
- Short queries with uniformly low-IDF terms: minimal speedup — barely above 1x in our bench.
- Long queries dominated by high-IDF rare terms: meaningful but smaller speedup; high-IDF terms have short postings and rarely get culled.
- Long queries with mixed IDF: close to peak — the term mix gives the threshold something to work with.
The list above sketches where BM25-stage speedup lands against query length and average term IDF in our bench. Speedup peaks in the middle of that space: mid-length queries with mixed-IDF terms get the bulk of the improvement, while short queries built entirely from low-IDF tokens barely move. The mechanical reason follows from the algorithm itself (see Ding & Suel, 2011): low-IDF terms produce weak upper bounds, the threshold rises slowly, and few blocks get culled.
The non-improvement shapes worth naming (all observations from our own bench on the same 12M-doc corpus):
- Short flat-IDF queries. Two-term queries like “the data” or “open source” produce upper bounds where almost every block could plausibly contribute. Skip ratios collapsed and the BM25 stage barely budged — well under the headline factor.
- Large-k retrieval. Once k climbs into the hundreds, the heap’s threshold stays low for longer, which directly suppresses block skipping. A large-k hybrid query showed only a modest BM25-stage improvement rather than the headline 3.4x. This matches the qualitative behavior described in Mallia et al. (2017), where threshold growth governs effective skip rate.
- Per-tenant micro-shards. If a Weaviate instance is multi-tenant with thousands of small per-tenant shards, each shard’s posting list is short, block-max metadata is overhead, and per-tenant BM25 cost is dominated by setup rather than scoring. In our tests, speedup approached 1.0x.
Migration cost on a 12M-doc index
Existing Weaviate instances do not get BlockMax WAND automatically. According to the v1.30.0 changelog and the Weaviate indexing documentation, the inverted index needs a one-time rewrite to add the new per-block metadata; new collections written under 1.30 use the new format from the start. The public notes describe the migration at a category level — what they don’t currently provide is concrete operational numbers, so the observations below are from running a rewrite ourselves and should not be treated as a vendor commitment.

The image above is a snapshot of the migration log lines emitted on a 12M-doc collection. In our run, the rewrite took roughly an hour of wall-clock time on commodity bare-metal hardware. Additional disk usage during the rewrite is meaningful but bounded: the new format is built alongside the old before the swap, so the on-disk footprint of the inverted index transiently roughly doubles, then drops back when the legacy structure is removed. Memory headroom went up during the rewrite as well; budget for noticeably higher steady-state RSS until the migration finishes.
For more on this, see weighing infra migration costs.
The behavior of queries against a collection while it is migrating is the operational detail that most matters and that we’d like to see spelled out more clearly in the official docs. In our testing the collection remained query-able throughout, with lexical results served until the new scorer cut over. Operators who need a contractual guarantee here should confirm against their own 1.30 instance, since the public indexing documentation doesn’t currently describe the fallback path in detail.
Rollback to 1.29 binaries worked for us without re-ingestion because the legacy inverted index stays on disk until you explicitly remove it. The trade-off is the doubled inverted-index footprint until that cleanup step runs. We did not find an explicit rollback recipe in the linked docs; teams that care about a clean abort path should test it on a non-production collection before they rely on it.
How Weaviate’s implementation compares to Lucene, Elasticsearch, and OpenSearch
BlockMax WAND has been available in the Apache Lucene scorer family for years, which means engines built on Lucene — including Elasticsearch and OpenSearch — have had access to block-max-style skipping for some time. Weaviate is not introducing a new algorithm; it is closing a parity gap with the lexical search world on a technique that the IR literature has been refining since the 2011 Ding & Suel paper.
The image above tracks Python client adoption around the release, which is suggestive of attention rather than proof of a deployment wave. Calibration matters here: a 3–4x BM25-stage win (in our bench) moves Weaviate from “noticeably slower lexical retrieval than Lucene-based engines” to “roughly parity with them on the same algorithm class.” It does not leapfrog the prior art.
Background on this in hybrid retrieval fusion in LlamaIndex.
Does the speedup change relevance?
A common worry with WAND-family scorers is that skipping changes what gets returned. The algorithm is provably top-k correct given accurate per-block upper bounds (see Ding & Suel, 2011), but implementation bugs or upper-bound looseness can in principle alter results. In our side-by-side runs on the same corpus, top-10 result lists for the same queries matched on the overwhelming majority of cases; the small remainder differed only in tie-breaking between documents with identical BM25 scores, which is the expected consequence of differing posting-list traversal orders rather than a relevance regression. Scores for matching positions agreed to many decimal places.
Picking a migration path
The honest answer is that the right move depends on what your hybrid queries actually look like, and a one-size recommendation would be misleading. A few rules of thumb hold up well, though, and they’re worth running through before you schedule a change window.
a similar latency win on the serving side goes into the specifics of this.
If you run hybrid search on a single tenant (or a small number of large tenants) and the BM25 stage is the visible majority of your end-to-end latency, the migration tends to be worth doing soon — the stage-level win lands on user-visible p50 and p95 directly. The same is true for keyword-only workloads at large per-shard document counts: this is the case the algorithm was designed for, and the headline gains hold up best there.
If HNSW is already dominating your hybrid latency, the BM25 improvement is real but barely visible end-to-end, and there’s little reason to open a special change window for it; rolling it in at your next planned upgrade is usually fine. Multi-tenant deployments with thousands of small tenants, and workloads where k is in the hundreds, are the cases to be cautious about — skip ratios collapse in both, and the win in our tests landed closer to 1x than 3x. Benchmark before you commit.
And if your workload is vector-only with no BM25 path, BlockMax WAND simply doesn’t run; upgrade for other 1.30 changes if any apply, per the release notes, but the lexical speedup isn’t a factor.
The general advice underneath all of these: measure your own BM25-stage share on 1.29 first — the gRPC client surfaces stage timings — and let that number, not the headline, decide whether you migrate this quarter or next. The cost of an hour of measurement is much smaller than the cost of a temporary disk-usage spike on a workload that turns out to be a wrong fit.
| Workload profile | Action | Rationale |
|---|---|---|
| Hybrid search, single or low-tenant-count, BM25 stage is the majority of total latency | Migrate now | BM25-stage gains translate directly to user-visible latency improvements. |
| Hybrid search, HNSW dominates the latency budget | Migrate at next planned upgrade | Real win, small impact on end-to-end p50; not worth a special window. |
| Pure BM25 / keyword-only workloads at large per-shard document counts | Migrate now | This is the case the algorithm was designed for; expect close to the headline gains. |
| Multi-tenant with thousands of small tenants | Defer; benchmark first | Skip ratios collapse on micro-shards; the block-max metadata may be overhead. |
| Large-k retrieval as the dominant pattern | Test before committing | Threshold growth is slow at large k; speedup is materially smaller than the headline. |
| Vector-only queries, no BM25 path used | Skip the urgency | BlockMax WAND does not run on this code path; upgrade for other 1.30 changes if needed. |
For teams already on Weaviate where hybrid latency matters, the practical move is to schedule the migration during a window that tolerates a transient doubling of the inverted-index footprint and roughly an hour of rewrite time per ~12M documents on comparable hardware, then verify the win with the team’s own query log. The 91ms → 27ms result is real and reproducible on our setup — just not the 10x end-to-end speedup the launch framing implies.
Methodology note
The numbers in this article come from a single in-house benchmark run, and the writeup is closer to “what we saw” than “a paper-quality measurement.” Enough detail to make the comparison fair, and enough caveats to keep it honest:
- What was held constant. The same corpus (around 12 million documents, single tenant, single replica) was loaded into both versions with the same schema. BM25 parameters (k1, b) and HNSW
efwere unchanged. Queries were replayed from a captured production-style log rather than generated synthetically, so term frequencies and length distribution reflect real traffic rather than a uniform distribution. Latency was measured at the gRPC boundary on the client side after a warmup period to let caches settle. Each configuration was exercised over the full query set in a single run; we did not repeat the full sweep multiple times to compute confidence intervals. - What we did not pin down on the page. The exact 1.29.x patch version, the exact Python client version, the schema definition, the precise hardware SKU, and the question of warm-vs-cold cache state would all matter for an external attempt to reproduce these numbers, and we have intentionally not pinned them down in print because the headline conclusion — BM25-stage roughly tripled, end-to-end hybrid roughly halved — held up across the variations we tried in setup. Treat the numbers as the direction and rough magnitude of the win, not a specification.
- What the release notes do and don’t cover. The v1.30.0 release notes document the scorer change and the migration requirement; details such as exact block layout, the fallback behavior of queries during an in-flight rewrite, and the rollback path are not enumerated there or in the indexing documentation at the level of specificity used above. Operational claims in this article that go beyond the linked references are based on our own runs and should be confirmed against your own instance.


