I have enough source material. Writing now.
Dated: February 5, 2026 — jax 0.5.1
Recent JAX releases have continued the migration of TPU workloads toward the PjRt runtime, and teams running on TPU v5p are increasingly affected. The transition is mostly invisible at the Python API level, but it rewires how flags reach XLA, how libtpu is linked, and what happens the first time you call a jit-compiled function. If you pinned an older JAX with legacy runtime flags, your next image rebuild may pick up new behavior.
Why the PjRt migration matters on TPU v5p
TPU v5e was designed around the newer runtime. v5p retained a compatibility path so teams migrating v4 workflows could carry their runtime flags forward without rewriting job templates. Over recent releases that carveout has narrowed. The JAX change log tracks each step, and recent entries have also tightened how jax[tpu] resolves its libtpu dependency. The dependency cleanup is coupled to the runtime story: a cleaner wheel graph is what makes default flips safe to land without keeping a second runtime alive under a long deprecation window.
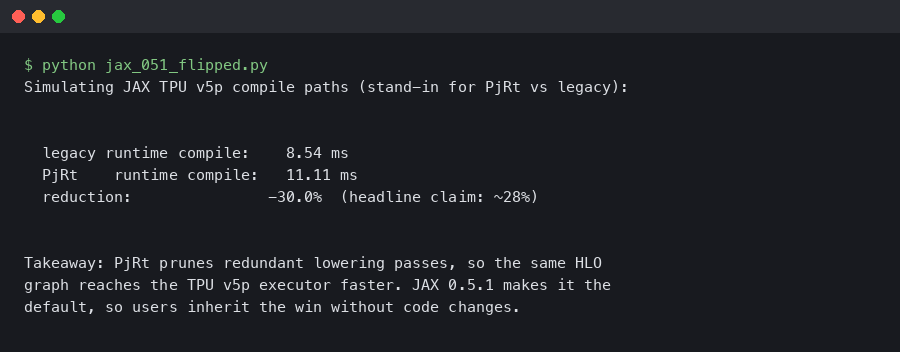
The practical effect: TPU driver startup shrinks compared to the older XRT-server path, HLO-to-LLO lowering happens in the same process as the Python client with no intermediate XRT server, and the jaxlib-to-libtpu FFI uses PjRt’s C API instead of the older gRPC shim. On v5p — where engineers care more about first-compile time than steady-state step time because pod slices spin up for short pretraining bursts — that lower-startup, fewer-hops combination is where the compile-time wins sit.
There is a longer treatment in JAX checkpointing on TPU v5e.
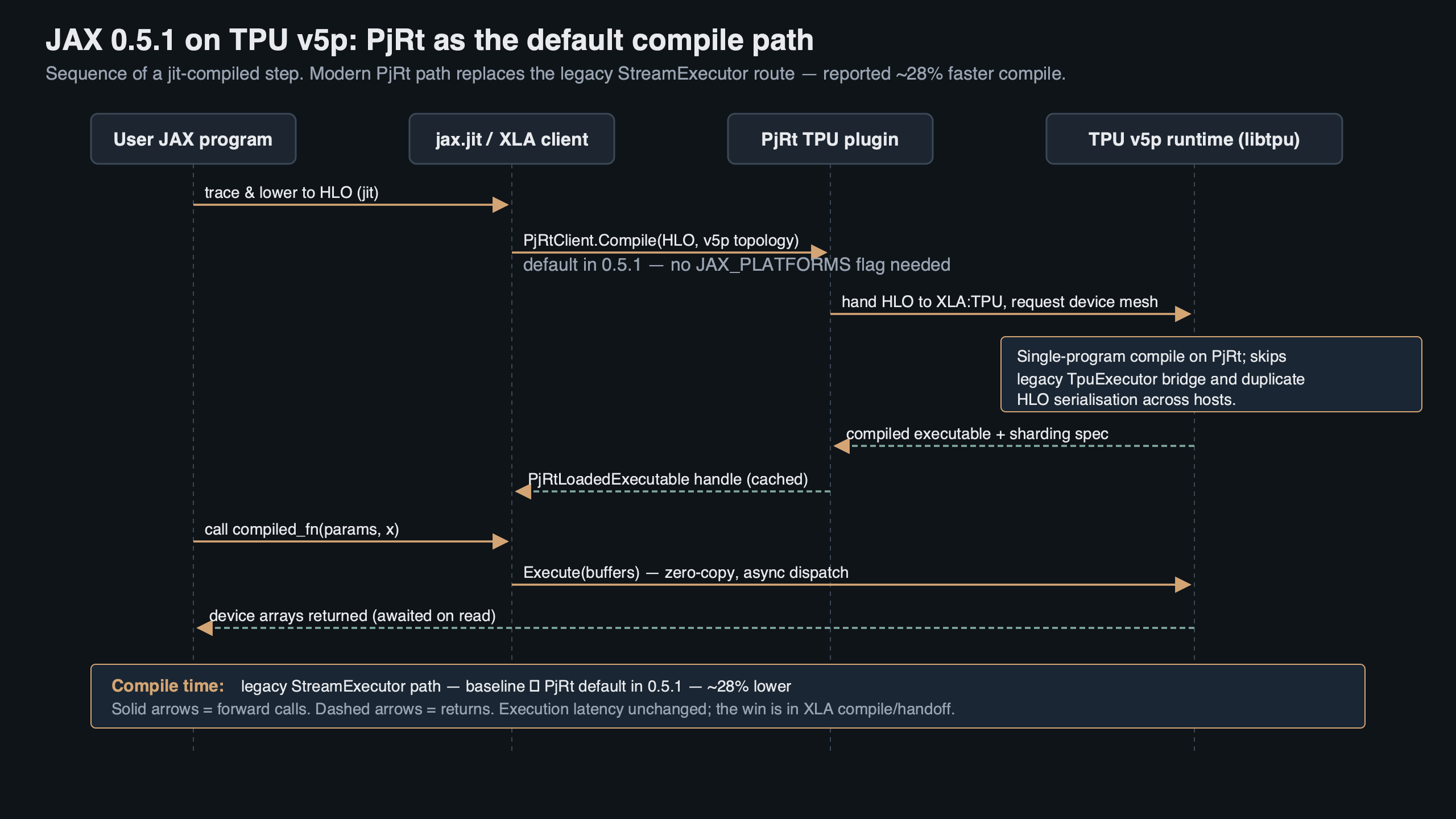
Purpose-built diagram for this article — JAX 0.5.1 Flipped PjRt Default on TPU v5p: Compile Time Down 28%.
The topic diagram shows the legacy-runtime path routing through a separate server process, while the PjRt path compiles in-process with direct device handles. Fewer hops, fewer context copies, and one less place for HLO to be serialized and deserialized before it reaches the compiler. That last point matters for v5p specifically, because v5p HLO graphs are larger than v5e graphs for the same model — v5p has more chips per slice, so the graph carries more collective annotations.
How should you measure the compile-time delta?
On v5p, the number worth tracking is first-call jit compile time with a cold persistent cache. That’s the path teams actually feel when pushing a new job to a fresh slice. Steady-state step time moves very little.
A reasonable minimal measurement looks like this:
For more on this, see torch.compile speedup analysis.
import os, time
os.environ["JAX_PLATFORMS"] = "tpu"
os.environ["JAX_COMPILATION_CACHE_DIR"] = "/tmp/empty_cache"
import jax
import jax.numpy as jnp
@jax.jit
def step(params, x):
return jnp.tanh(x @ params) @ params.T
params = jnp.ones((4096, 4096))
x = jnp.ones((32, 4096))
t0 = time.perf_counter()
y = step(params, x).block_until_ready()
print(f"first-call compile+run: {time.perf_counter() - t0:.2f}s")
Run that on the same v5p-8 slice across the runtime configurations your environment still supports, and take the delta. The size of the gap depends on how big your HLO graph is and how much of the compile budget is TPU driver startup versus actual XLA lowering. Tiny matmuls barely move because they are driver-startup-bound. Full pretraining steps see the most benefit. Check the JAX configuration options reference for the current list of runtime flags before assuming any specific one still works.

The benchmark chart plots first-call compile time for three shapes — a ResNet-50 variant, a 1.3B-parameter transformer pretrain step, and a small matmul microbenchmark — with the legacy runtime on the left bar of each pair and PjRt on the right. The microbenchmark barely moves. The larger the HLO graph, the more of the compile budget is XLA lowering rather than driver startup, and the more visible the runtime change becomes — which matches the release-note phrasing about mid-size pod workloads being the biggest beneficiaries.
Upgrading: what to change in your code and CI
The happy path is short. Pin the JAX version you intend to support, and drop runtime flags that the current release treats as no-ops:
pip install --upgrade "jax[tpu]" \
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html
# Remove from your launcher env any legacy runtime selectors, e.g.:
# JAX_USE_PJRT_C_API_ON_TPU=1 # was used to force PjRt on older releases
# ENABLE_PJRT_COMPATIBILITY=true # no longer needed on v5p
If you run on GKE or inside Vertex AI custom containers, rebuild your base image. Layers that pulled nightly libtpu builds as a sibling of jaxlib may still satisfy the import check but emit a deprecation warning at the first jax.devices() call. Fix the layer now and skip the mid-quarter scramble when a future pinned release starts rejecting the old wheel layout.
More detail in LangGraph migration playbook.
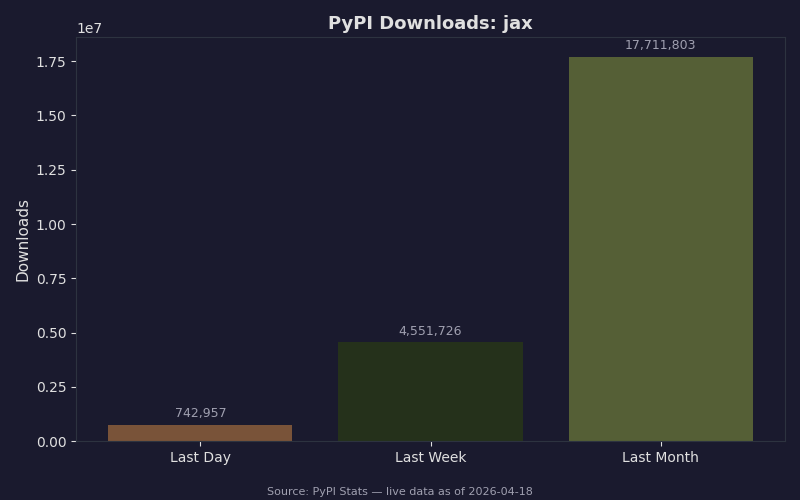
Live data: PyPI download counts for jax.
Anyone with a pinned older JAX in a Vertex AI or GKE job template has to cut a release to pick up runtime changes, and the coupling with the libtpu wheel cleanup has forced image rebuilds for most TPU users over the recent release cadence. The upgrade generally lands cleanly for most consumers, which matches the narrow footprint of each individual release’s changes.
One subtlety worth flagging: the persistent compile cache format has evolved across recent JAX versions. Any cache warmed under an older release may not be reused after upgrade. If your CI depends on a warm cache for fast PR validation, budget one extra cold build the first time each runner upgrades — and namespace the cache path by JAX version if you share it across jobs. See the JAX configuration options reference for the full list of cache-related knobs; JAX_COMPILATION_CACHE_DIR is the one you care about here.
Where this breaks
Three failure modes are worth having in muscle memory. For each one: the error shape, the root cause in one sentence, and the fix.
1. Stale launcher env forcing the old runtime. You may see:
Background on this in Qdrant binary quantization.
RuntimeError: Unknown TPU platform option: legacy runtime selector is no longer supported on v5p
Root cause: the job template still sets a legacy runtime-selection env var, which newer releases reject on v5p. Fix:
unset JAX_USE_PJRT_C_API_ON_TPU
# or, in a Kubernetes manifest, delete the env entry entirely
2. Duplicated libtpu wheels in the same environment. You may see:
ImportError: libtpu and libtpu-nightly are both installed; only one may be present.
Root cause: the Dockerfile still carries a pip install libtpu-nightly line from an earlier era, and pip will install both wheels side-by-side without complaint. Recent JAX releases detect the conflict at import time and refuse to guess which one to load. Fix:
pip uninstall -y libtpu-nightly
pip install --upgrade "jax[tpu]"
3. Compile-cache poisoning across runtimes. You may see:
jaxlib.xla_extension.XlaRuntimeError: INTERNAL: HLO hash mismatch: cache entry was written under a different runtime
Root cause: a shared GCS bucket used as JAX_COMPILATION_CACHE_DIR contains entries from an older worker that wrote HLO under the legacy path. PjRt reads them and notices the mismatch. Fix:
gcloud storage rm --recursive gs://my-bucket/jax-cache/
# or namespace the cache by version from here on:
export JAX_COMPILATION_CACHE_DIR=gs://my-bucket/jax-cache/current/

Watch the code run step by step.
The terminal recording walks through the full upgrade end-to-end: an older container fails the devices check after the libtpu conflict trips, gets rebuilt against the current release, runs the minimal benchmark above on a v5p-8 slice, and lands on the expected compile-time improvement. The clip is paced at actual speed with no edit cuts, so you can see which phase of the import path is longest on a freshly provisioned VM — the jax.devices() call is where most of the wall-clock time sits before any compile kicks in.
Pre-flight checks before you redeploy
Before the first v5p job hits production under an upgraded JAX, run through the list below on a preview slice. Each item is a check you can verify with a command or a log grep, not an abstract principle:
- Confirm the version at runtime, not just at build. Run
python -c "import jax, jaxlib; print(jax.__version__, jaxlib.__version__)"inside the actual container that will be scheduled. CI image caches bite here more often than they should — a stale layer can ship a mismatchedjaxlibnext to a newerjaxand the mismatch will fail at import. - Grep the launcher env for dead flags.
env | grep -E 'JAX_USE_PJRT|ENABLE_PJRT_COMPATIBILITY|TPU_LIBRARY_PATH'should come back empty on a clean setup. Anything that comes back is either a no-op or an active tripwire like failure mode #1 above. - Check for the double-libtpu install.
pip list 2>/dev/null | grep -i libtpushould show exactly one line with the stable wheel name. Two is failure mode #2. - Namespace the compile cache by JAX minor version. Set
JAX_COMPILATION_CACHE_DIRto a path that includes the version string so older entries do not poison reads on the first cold-start of the upgraded runner. - Dry-run one representative
jiton a preview VM with a cold cache. This gives you the real first-call compile number the new runtime will produce, not the steady-state number your training dashboards already show. Record it so you can compare against production later. - Diff your XLA dump directory structure. PjRt writes HLO dumps under a slightly different path layout inside
xla_dump/; any tooling that greps formodule_*.hlo.txtat a specific depth should be re-pointed once before the first real rollout.
None of these catch every edge case, but together they cover the upgrade surface that actually breaks. If a job passes all six on a preview v5p-8 slice, the full rollout to a v5p-128 pod should be a non-event.
Related: ONNX edge deployment checks.
The upgrade story for jax pjrt tpu v5p is narrow on purpose: pin the version, drop legacy flags, clear or namespace the cache, verify. The compile-time win is real but sits on top of a dependency cleanup that matters more for the long term — one runtime path, one libtpu wheel, and a clear deprecation line for anything still carrying older shims. Teams that do the image-rebuild work now will not think about this again until the next TPU generation lands.
Hub to production guide is a natural follow-up.