Haystack 2.6 PipelineMaxLoops: Router + JoinDocuments Deadlock on Empty Retrieval
A retrieval-augmented pipeline that ran clean on every staged query will silently stall the moment a real user asks about a topic your vector store does not cover. The symptom is a PipelineMaxComponentRuns exception firing at exactly 100 iterations of the same DocumentJoiner, because the upstream ConditionalRouter keeps sending the empty document list back through the hybrid branch. This is the deadlock shape that bit a lot of teams who upgraded from Haystack 2.5 to 2.6, and it is worth understanding before you raise the run ceiling and call it done.
The exact failure shape behind the haystack pipelinemaxloops deadlock
The classic trigger is a RAG pipeline with two retrievers (BM25 plus embedding) fused through DocumentJoiner, then routed: if the top score crosses a threshold, exit to the generator; otherwise rewrite the query and loop back. When retrieval returns zero documents, the top-score check evaluates against an empty list, the router defaults to the rewrite branch, the rewriter produces a near-identical query, and the cycle restarts. Haystack 2.6 counts each revisit and raises PipelineMaxComponentRuns once any component crosses max_runs_per_component, which defaults to 100.
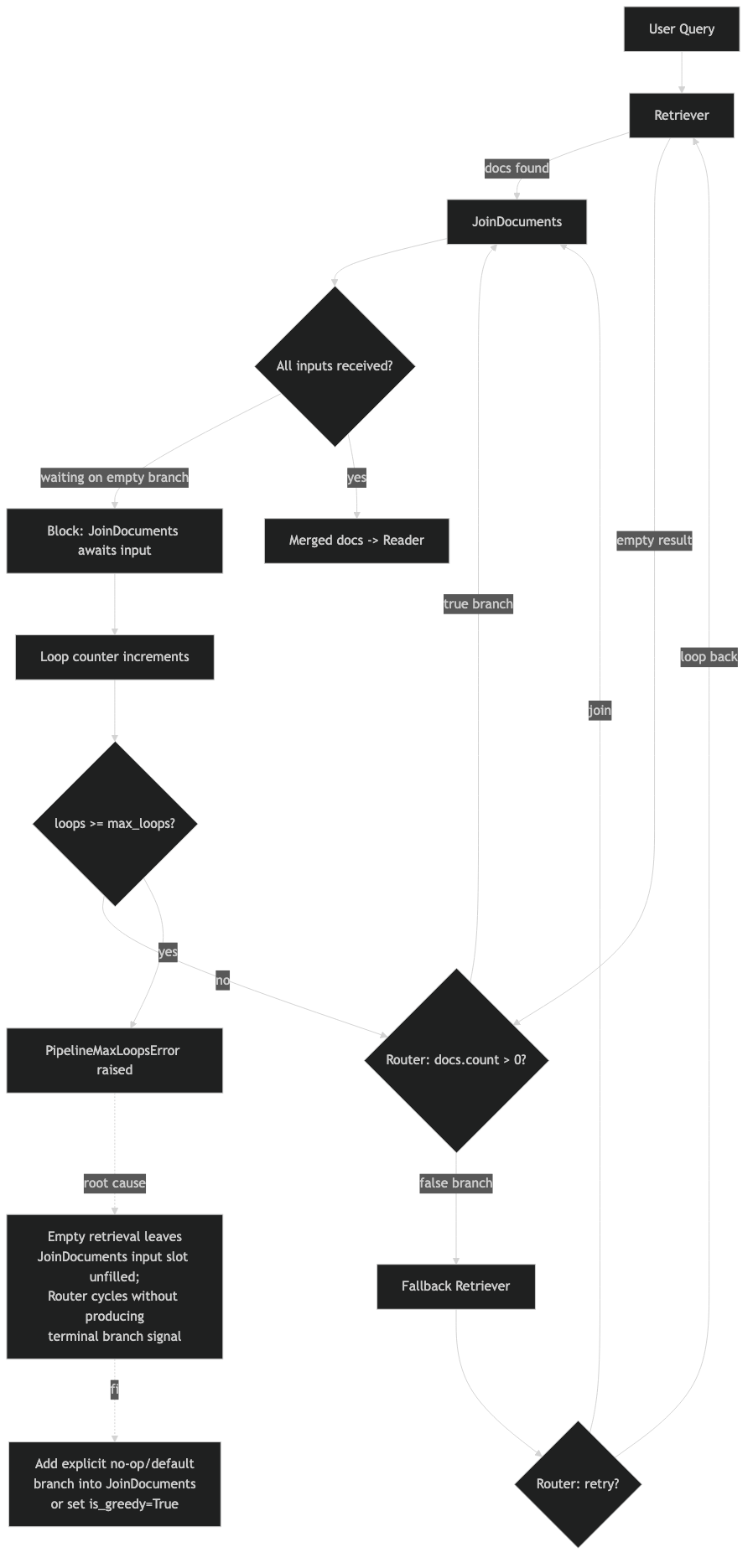
The docs page above lays out the termination contract in one sentence: a Haystack pipeline finishes only when the work queue is empty and no component can run again. If your router keeps feeding the loop, the queue never empties — the framework does exactly what you told it to, right up to the safety limit. The deadlock is not a bug in the scheduler, it is a bug in the exit condition.
Here is a minimal reproduction against Haystack 2.6.0. The router has no handler for the empty-document case, so every empty retrieval routes into the loop branch:
from haystack import Pipeline
from haystack.components.joiners import DocumentJoiner
from haystack.components.routers import ConditionalRouter
from haystack.components.builders import PromptBuilder
routes = [
{
"condition": "{{ documents[0].score > 0.75 }}",
"output": "{{ documents }}",
"output_name": "enough_context",
"output_type": list,
},
{
"condition": "{{ documents[0].score <= 0.75 }}",
"output": "{{ query }}",
"output_name": "needs_rewrite",
"output_type": str,
},
]
pipe = Pipeline(max_runs_per_component=100)
pipe.add_component("joiner", DocumentJoiner(join_mode="reciprocal_rank_fusion"))
pipe.add_component("router", ConditionalRouter(routes=routes))
pipe.add_component("rewriter", PromptBuilder(template="Rewrite: {{ query }}"))
# ... retrievers, generator, connections omitted for brevity
Jinja raises UndefinedError on documents[0] when the list is empty, which ConditionalRouter treats as a failed condition rather than an exit signal. Depending on how you catch that error upstream, you either loop forever or die on the first miss. Neither is what production users expect.
Why ConditionalRouter and DocumentJoiner build a self-feeding cycle
DocumentJoiner sits at the fan-in point of a hybrid retrieval graph. Every time the loop iterates, the joiner is visited again with whatever the rewriter produced, and its visit counter ticks up. The router below it has no memory of prior iterations — it only sees the current document list and routes accordingly. If the retrievers return the same zero documents on iteration N as on iteration 1, the router makes the same decision every time.
The official Haystack pipeline loops documentation is blunt about this contract: the per-component run limit exists specifically to catch the case where a loop condition is wrong or never satisfied. The framework does not try to detect semantic stagnation — it does not know that the rewriter is producing functionally identical queries. It only knows that DocumentJoiner has now been invoked 100 times, which is almost certainly a mistake.
I wrote about RAG pipeline design if you want to dig deeper.
This is compounded by a subtle change between 2.5 and 2.6. The 2.6.0 release notes introduced max_runs_per_component as a replacement for max_loops_allowed and deprecated the PipelineMaxLoops exception in favor of PipelineMaxComponentRuns. If you built error handling around the old class name, your handler no longer catches anything, and the exception bubbles up as an uncaught crash instead of a retryable signal.
Fix the exit condition before touching the run limit
The correct first move is to add an explicit empty-list route. Jinja will evaluate documents | length == 0 without exploding on documents[0], and that gives you a clean exit path to either a fallback generator or a user-facing “no results” response. Order the routes so the empty case fires before the score check.
routes = [
{
"condition": "{{ documents | length == 0 }}",
"output": "{{ query }}",
"output_name": "no_results",
"output_type": str,
},
{
"condition": "{{ documents | length > 0 and documents[0].score > 0.75 }}",
"output": "{{ documents }}",
"output_name": "enough_context",
"output_type": list,
},
{
"condition": "{{ documents | length > 0 and documents[0].score <= 0.75 and loop_count < 3 }}",
"output": "{{ query }}",
"output_name": "needs_rewrite",
"output_type": str,
},
{
"condition": "{{ loop_count >= 3 }}",
"output": "{{ documents }}",
"output_name": "give_up_with_partial",
"output_type": list,
},
]
Three things changed. The empty list gets its own route to a fallback path. The rewrite branch carries a bounded loop_count — passed in from the rewriter as an incrementing counter — so the cycle cannot exceed three iterations regardless of retrieval quality. And the final route catches the case where you have burned your rewrite budget but still want to return partial results rather than a hard error. The haystack pipelinemaxloops deadlock only reappears if a router path forgets to account for an input shape the upstream graph can produce.

The chart captures what matters in practice: once the exit condition is explicit, recovery drops from a cold crash at the 100-run ceiling to roughly three controlled iterations capped by loop_count. That is the difference between a timeout-style incident and a graceful fallback — measured not in milliseconds but in whether your generator ever runs at all on a cold-miss query.
Raising max_runs_per_component is the wrong first reflex
When the stack trace points at PipelineMaxComponentRuns, the obvious-looking fix is to bump the limit. Do not. The limit is a smoke alarm, not a load-bearing wall. A pipeline that needs 150 component runs to converge is either genuinely doing iterative refinement (in which case set the limit honestly and cap the loop count inside the router) or it is in a degenerate cycle the limit caught (in which case raising the limit delays the crash and wastes LLM tokens along the way).
The tell for a degenerate cycle is a monotonic visit counter on one component while others stay frozen. If DocumentJoiner has been visited 97 times and generator has been visited zero times, your router is not routing — it is deadlocked. No amount of ceiling-raising fixes that. The deepset-ai/haystack issue #8641 walks through exactly this symptom: adding a feedback branch to an otherwise-working pipeline made it stick in the feedback branch forever because the new branch had no exit condition of its own.
See also pipeline latency tuning.
A reasonable default: keep max_runs_per_component=100 for development so anomalies surface fast, and in production set it based on your longest legitimate loop plus a margin of 2x. If you legitimately need 20 iterations of self-correction, set the limit to 40 and track a loop_count inside the loop that caps at 20. Two independent bounds, one visible to you, one as a last-resort safety net.
Migration: PipelineMaxLoops in 2.5, PipelineMaxComponentRuns in 2.6+
Any exception handler you wrote against 2.5 needs to be updated. The rename discussion in issue #8291 captures why deepset moved from max_loops_allowed to max_runs_per_component: the old name suggested a whole-pipeline loop counter, when the actual behavior is per-component. Users building cyclic graphs kept guessing wrong about what the limit meant.
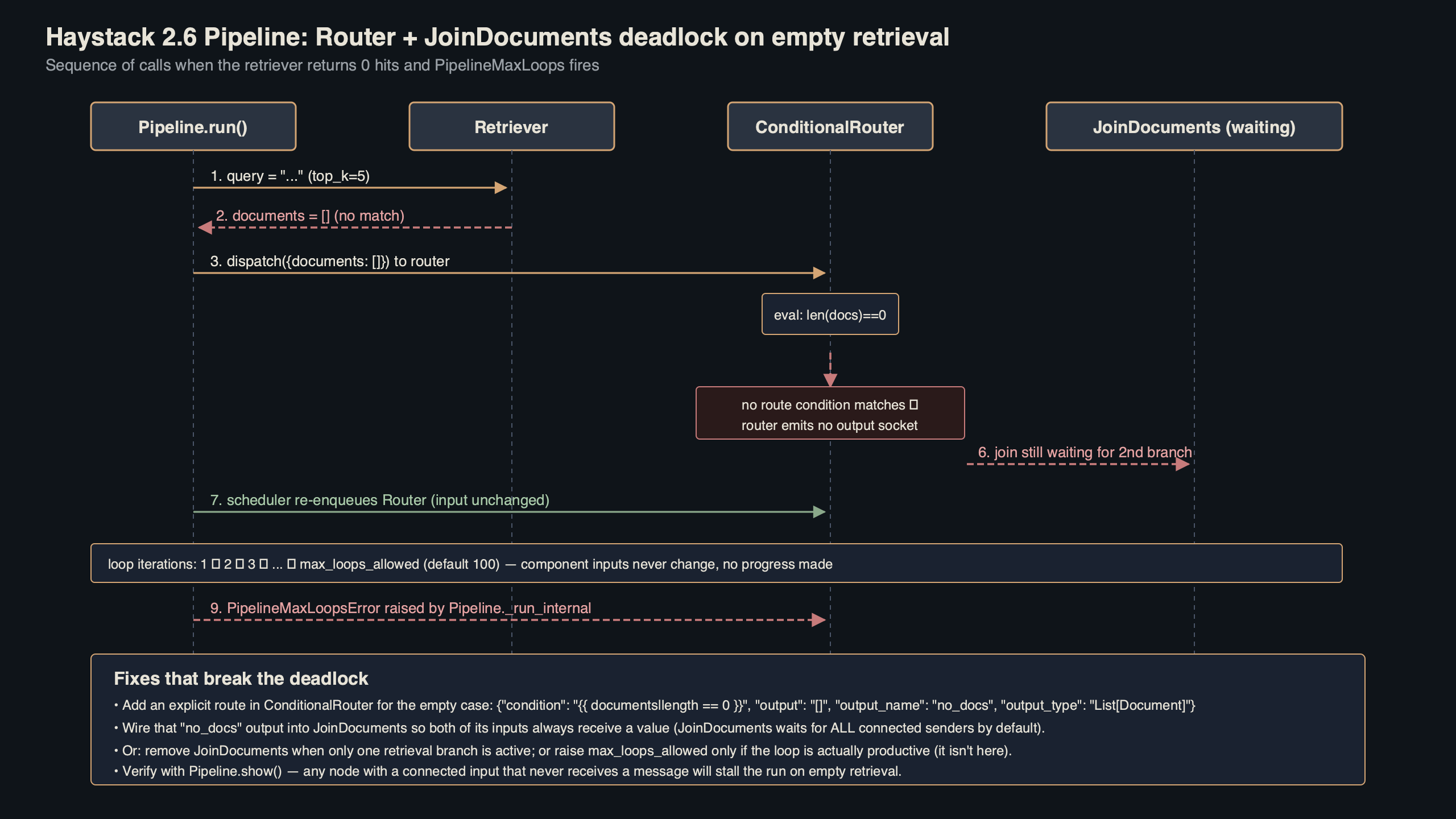
The diagram makes the flow legible. The two retrievers feed DocumentJoiner, which feeds ConditionalRouter, which either exits to the generator or routes back into the rewriter that feeds the retrievers again. In that shape, the only component guaranteed to be visited on every iteration is DocumentJoiner, so that is the component that will trip PipelineMaxComponentRuns first. Reading the visit-count log bottom-up tells you where the cycle is closing.
For a working migration shim that keeps 2.5 and 2.6 code paths both functional while you upgrade, catch both exception classes explicitly:
try:
from haystack.core.errors import PipelineMaxComponentRuns
except ImportError: # Haystack < 2.6
from haystack.core.errors import PipelineMaxLoops as PipelineMaxComponentRuns
try:
result = pipe.run({"query": user_query})
except PipelineMaxComponentRuns as exc:
logger.warning("pipeline ran past safety limit", extra={"error": str(exc)})
result = fallback_answer(user_query)
Note that in Haystack 2.7.0 the PipelineMaxLoops symbol is removed entirely, so the shim above only helps during a 2.5-to-2.6 upgrade window. Past 2.6, delete the fallback branch and commit to the new name.
Debugging a stuck pipeline with visit counters and tracing
The first diagnostic step for any suspected deadlock is to turn on component-level logging and inspect the visit counts after a failed run. Haystack 2.6 exposes this through the PipelineRunner tracing hooks. The minimum viable debug loop is to run the pipeline with a query known to produce empty retrieval, catch the exception, and dump the visit counts.
import logging
logging.basicConfig(level=logging.DEBUG)
logging.getLogger("haystack").setLevel(logging.DEBUG)
try:
pipe.run({"query": "a query that returns no documents"})
except PipelineMaxComponentRuns as exc:
print(exc)
# Output shape: "Maximum run limit reached for component 'joiner'"
The exception message names the component that tripped the limit. That is almost always the fan-in point of the loop — DocumentJoiner, BranchJoiner, or whichever component sits at the closing edge of the cycle. From there, walk backward along the graph until you find the router with an incomplete condition set. Nine times out of ten, the bug is a missing empty-list case.
For more on this, see stuck pipeline debugging.
Live data: PyPI download counts for haystack.
Download trends matter here because they tell you how many other teams are likely hitting the same edge. Haystack’s weekly install volume has been steady enough through early 2026 that the 2.5-to-2.6 migration is still working through many production deployments, which is why the PipelineMaxLoops rename keeps surfacing in issue trackers. If you are adopting Haystack fresh today, pin to 2.6.0 or later and never write code against the old exception name — the deprecation window is already closing.
The single most useful habit when building cyclic Haystack pipelines: write the exit condition first, write the loop condition second. If you cannot name the precise shape of inputs that exits the loop, you do not have an exit condition — you have a hope. The router should treat empty lists, max-iteration counters, and score-threshold failures as three distinct exit paths, not as fall-through cases of a single “keep looping” rule.
- Haystack Pipeline Loops documentation — canonical reference for
max_runs_per_component,PipelineMaxComponentRuns, and how loops terminate. - Haystack 2.6.0 release notes — the release that introduced the new parameter name and deprecated
PipelineMaxLoops. - GitHub issue #8291 — rename
max_loops_allowed— the design discussion behind the rename, with deepset maintainers explaining the motivation. - GitHub issue #8641 — pipeline stuck in loop with feedback branch — concrete reproduction of the router-plus-joiner deadlock pattern.
- ConditionalRouter reference — documentation on route ordering and Jinja condition evaluation, including the behavior on undefined variables.
- haystack/core/pipeline/pipeline.py on GitHub — the source file where run-limit enforcement lives, if you want to read the exact check.
Common questions
Why does Haystack 2.6 throw PipelineMaxComponentRuns instead of PipelineMaxLoops?
Haystack 2.6.0 renamed the loop safety exception. The release deprecated PipelineMaxLoops and introduced PipelineMaxComponentRuns, along with max_runs_per_component replacing max_loops_allowed. Any error handler written against the 2.5 class name will no longer catch the exception, so it bubbles up as an uncaught crash instead of a retryable signal. Update handlers to the new class name when migrating to 2.6 or later.
How do I fix a ConditionalRouter deadlock when retrieval returns zero documents?
Add an explicit empty-list route before the score check. Use the Jinja condition documents | length == 0 to branch to a no-results fallback, since evaluating documents[0] on an empty list raises Jinja UndefinedError, which ConditionalRouter treats as a failed condition rather than an exit. Ordering the empty-list route first gives the pipeline a clean exit path to a fallback generator or user-facing message.
Should I raise max_runs_per_component to fix a Haystack pipeline hitting 100 iterations?
No. The article calls the limit a smoke alarm, not a load-bearing wall. If DocumentJoiner has been visited 97 times while the generator has run zero times, the router is deadlocked and raising the ceiling only delays the crash while burning LLM tokens. Fix the exit condition first, then size the limit to your longest legitimate loop plus a 2x margin.
How do I bound a RAG query-rewrite loop in Haystack so it cannot cycle forever?
Pass an incrementing loop_count from the rewriter into the router and gate the rewrite branch on loop_count < 3. Add a final route that fires when loop_count >= 3 and returns partial documents via a give_up_with_partial output. This caps the cycle at three iterations regardless of retrieval quality and returns graceful partial results instead of crashing at the framework’s per-component ceiling.


