AI/ML

OpenAI vs Anthropic: Choosing the Best LLM for RAG Pipelines
I’ve spent the last two years tearing apart, rebuilding, and agonizing over Retrieval-Augmented Generation (RAG) architectures.

How I Cut FLUX.1 Inference to 3 Seconds with TensorRT
I was staring at my terminal at 1:30 AM last Thursday, watching my RTX 4090 scream at 98% utilization while spitting out a single 1024×1024 image every 15.

Meta’s $100B AMD Pact Actually Fixes PyTorch’s Biggest Headache
The Monopoly Tax is Getting Old I spent three hours yesterday trying to provision a single H100 instance on AWS. Three hours. For one node.

TensorRT Just Fixed Local Image Generation
Running modern, heavy diffusion models locally has felt like trying to stuff a mattress into a compact car for months now. You Learn about TensorRT News.

Local Inference is Finally Good (Thanks, TensorRT)
I spent the better part of yesterday fighting with a Docker container that refused to see my GPU. You know the drill.
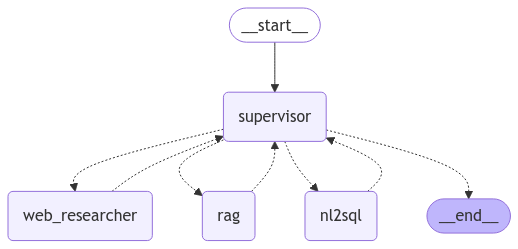
Multi-Agent RAG in Streamlit: It’s Finally Not a Hack
Actually, I used to dread the words “multi-agent” and “Streamlit” in the same sentence. Don’t get me wrong, I love Streamlit for quick dashboards.

Optuna Is Still The HPO King (Yes, Even In 2026)
Actually, I should clarify – I spent last Tuesday fighting with a “self-optimizing” LLM agent that promised to tune my hyperparameters automatically.

Optuna’s New Rust Storage Backend Is Absurdly Fast
Actually, I should clarify – I spent three hours last Tuesday staring at a progress bar that simply refused to move. You know the feeling.

Secure AI in Hex: Running Claude Inside Snowflake Cortex
I’ve lost count of how many times I’ve had to kill a project—or at least neuter it significantly—because InfoSec took one look at the architecture diagram.

OpenAI Weights on SageMaker: Hell Froze Over
Honestly, I had to check the URL three times. Then I checked the SSL certificate. Then I texted a buddy at Amazon to ask if their marketing team had gone.